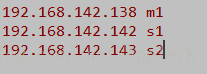网上的一些配置文章千篇一律,太杂了,也不是看不懂,就是感觉从头捋下来,累个半死,其实搭建的过程不是太难,只是对于初次搭建的同学们来说,简直就是噩梦,又是什么免密登录,又是什么设置主机名,又是什么集群添加几个slave节点的,还有什么配置core-site.xml,hdfs-site.xml的.etc,最后还要什么格式化namenode的,最最最后才是启动我们的hadoop环境,我去,还以为在Linux下装个JDK就算装逼的,好家伙,装个Hadoop集群环境不得装个大的啊,啊哈哈,不说了,下面,我就带领大家一起配个玩玩,注意是玩玩,可不是什么精深的,毕竟,如果项目中有用到Hadoop环境的,身为开发人员的我们,重心还是放在demo上吧,毕竟,环境配置什么的就交给其他人吧。
一、最终效果图展示

二、准备三台虚拟机
其实就是Copy三份CentOS镜像系统 ==>虚拟机开启三个,因为每一份CentOS都会要求装JDK【标配】,所以,我会事先准备好一个纯净版的带JDK1.8的,如下
很大,大约2.8G,这不是重点,重点是我们要配置集群的啊,有一个可不行,我们这里需要三个,一个NameNode,两个DataNode,解释下什么是Hadoop的节点,摘自百度百科,如下:
上面太抽象,不容易理解, 这里我就打个比方吧:NameNode假设是小组长,手底下管着好几号人,比如A、B、C;小组长分任务,任务交由A、B、C来完成,任务这里相当于一个文件,而一个任务分给A、B和C三个人,可能被分成了好几个小任务,相当于一个文件被分成了好几个块,由于A、B和C完成任务的能力不一样或者任务根本不需要三个人共同来完成,因此,任务可能是A一个人完成,也有可能是A和C一起完成的,当然也有可能是三个人一起完成的,相当于一个文件的多个块被存储到了一个DataNode或者多个DataNode节点上,不管存在哪个DataNode上,总之文件的目录信息是存储在NameNode上的,相当于小组长不关心任务是怎么完成的,他只关心最后,交付任务的时候,能不能从A、B和C那里拿到自己想要的,这里还有个关键的人存在,那就是副小组长,也就是在小组长请假了或出差的时候,暂时顶替小组长的位置,帮助小组长监工,相当于Secondary NameNode,这个我就不继续往下说了
继续说,上面说过我们需要三个节点来搭建一个Hadoop集群,因此我们需要三台虚拟机,Copy上面的纯净版的CentOS镜像成三份,分别命名:NameNode、DataNode1、DataNode2,,效果如下:
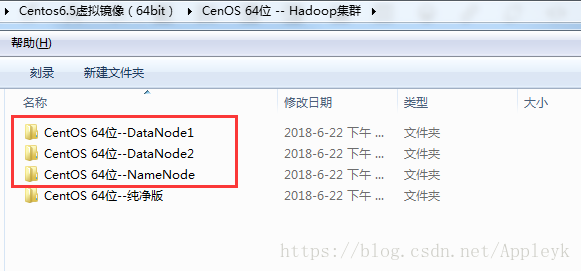
先不说集群环境该怎么搭建,起码,你要有搭建集群的决心和态度啊,准备三台虚拟机这个环节是真心省不了!
OK,用VM【我用的是VMware-8.0】分别打开上图中的三个CentOS 6.5镜像如下:

虽然模拟的是三台机子,但其实只要我们配好一台的Hadoop的环境就ok了,剩余两台,就是把配置好的Hadoop扔给【Copy】它们就行了,由于启动Hadoop集群之后,NameNode是通过SSH来启动和停止各个DataNode节点上的各种守护进程的,所以在节点之间执行指令的时候不能有密码,因此,在搭建集群环境之前,很重要的一件事,就是设置SSH免密登录
三、验证JDK和查询IP
登录NameNode所在的CentOS,并打开终端,查看IP和JDK版本
ifconfig
java -version

| CSDN排版功能,垃圾! |
同样的方式,三连登如下:
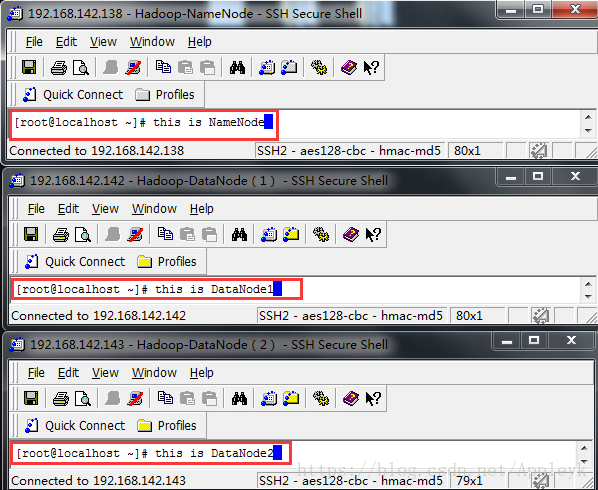
NameNode :192.168.142.138 == 对应主机名: m1 【待会进行IP和主机名的映射】
DataNode(1):192.168.142.142 == 对应主机名: s1 【待会进行IP和主机名的映射】
DataNode(2):192.168.142.143 == 对应主机名: s2 【待会进行IP和主机名的映射】
五、IP地址和主机名映射
| CSDN排版功能,垃圾! |
Now,please follow me together 设置主机IP和主机名的映射关系,比如在Windows下, IP地址 127.0.0.1 == 主机名 localhost,其修改的文件是hosts,位置在:
| CSDN排版功能,垃圾! |

| CSDN排版功能,垃圾! |
而在Linux下,其要修改的文件有两处:
(1)修改主机名,位置: /etc/sysconfig/network
使用vim编辑器,对network文件进行编辑:vim /etc/sysconfig/network == CentOS 7 下,使用vi命令
| CSDN排版功能,垃圾! |

| CSDN排版功能,垃圾! |
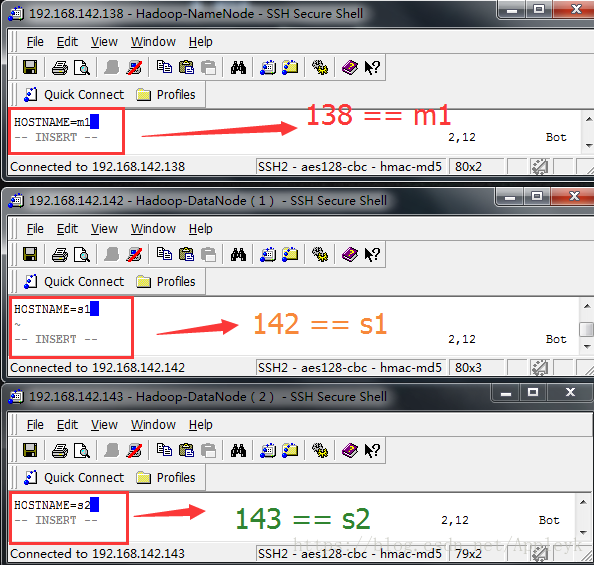
三台虚拟机,依次修改主机名称为:m1 (NameNode)、 s1(DataNode1)、s2(DataNode2)如下:
| CSDN排版功能,垃圾! |
| CSDN排版功能,垃圾! |
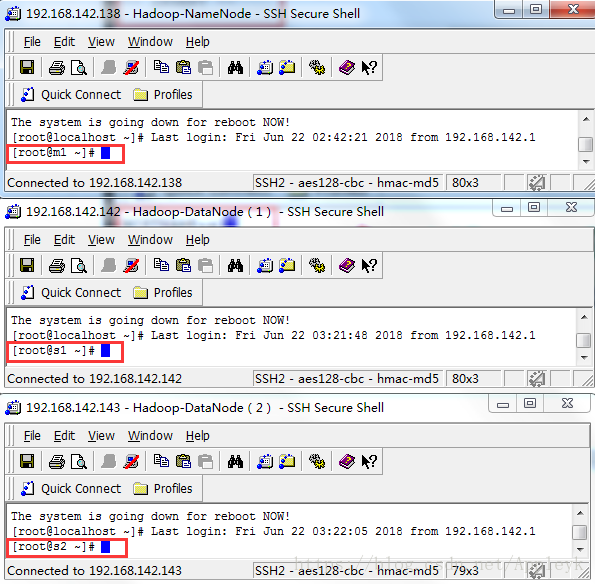
统一保存后,三台虚拟机需要重启reboot,才能使刚才的修改生效,重启后,在连接后就可以看到效果了:
| 这尼玛文章编辑器真垃圾啊,排个版费半天劲,最后还得使用table表格替代换行符,大写的服! |
| CSDN排版功能,垃圾! |
(2)修改IP地址和主机名之间的映射,位置: /etc/hosts
| CSDN排版功能,垃圾! |
添加如下映射关系【下面的内容直接copy添加】
192.168.142.138 m1
192.168.142.142 s1
192.168.142.143 s2
| CSDN排版功能,垃圾! |
这里我们利用EdiPlus的ftp连接功能,连接上虚拟机,其下载地址在我的网盘,当然使用vi或者vim命令修改hosts文件也行,不过我还是喜欢更直接更简单的方式,使用EdiPlus进行修改文件,如下:
| CSDN排版功能,垃圾! |
A、打开FTP配置
| CSDN排版功能,垃圾! |
| CSDN排版功能,垃圾! |
B、配置FTP连接参数
| CSDN排版功能,垃圾! |
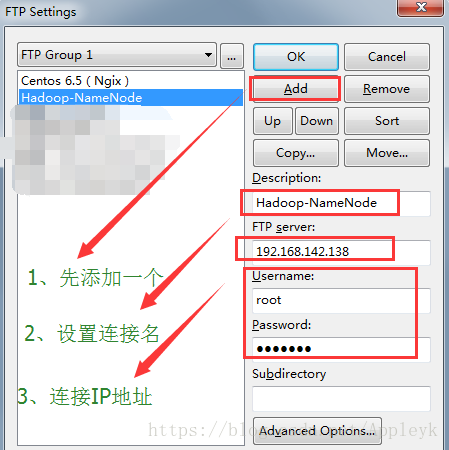
| CSDN排版功能,垃圾! |
C、高级选项【Advanced Options】,设置加密方式【sftp】和端口【22】
| CSDN排版功能,垃圾! |
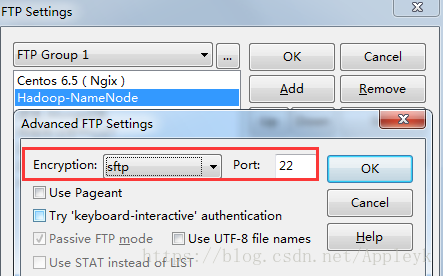
| CSDN排版功能,垃圾! |
D、连接
| CSDN排版功能,垃圾! |
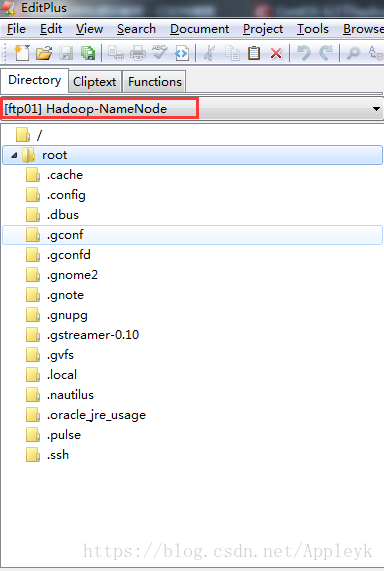
| CSDN排版功能,垃圾! |
E、目录/文件serach定位到/etc/hosts文件,并打开它
| CSDN排版功能,垃圾! |

| CSDN排版功能,垃圾! |
添加内容(将上面的映射copy进来)
| CSDN排版功能,垃圾! |

| CSDN排版功能,垃圾! |
保存
| CSDN排版功能,垃圾! |
| CSDN排版功能,垃圾! |
同样的方式,设置主机名s1和s2,此处略....
没设置前,利用ssh命令,s1连接自己s1(直接写主机名的方式),会报错
| CSDN排版功能,垃圾! |

| CSDN排版功能,垃圾! |
设置后,利用ssh命令,s1连接自己s1(直接写主机名的方式),则不会报错,而是会提醒你建立连接需要输入密码
| CSDN排版功能,垃圾! |
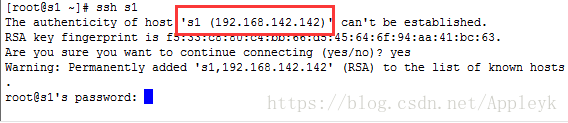
| CSDN排版功能,垃圾! |
上面我们说过,NameNode是通过SSH来启动和停止各个DataNode节点上的各种守护进程的,所以在节点之间执行指令的时候不能有密码,也就是上面这个,我们要设置成免密码登录的,不然,你们懂的,
| CSDN排版功能,垃圾! |
| CSDN排版功能,垃圾! |
| CSDN排版功能,垃圾! |
六、SSH免密码登录
| CSDN排版功能,垃圾! |
(1)免密码登录原理
| CSDN排版功能,垃圾! |
第一步:A上生成公钥和私钥
第二步:A上生成的公钥copy给B,存到authorized_keys(经授权的钥匙)文件中
第三步:A发送请求欲连接B
第四步:B要核实A身份,遂去authorized_keys文件中查找有没有A的信息(公钥密文中),有就随机生成一个字符串S,并将S用公钥加密成消息M回传给A(响应A的连接请求)
第五步:A拿到B响应的消息后,用自己的私钥解密消息M,并将解密后的消息R再次发送给B,B核对消息R,如果R和S一致,则允许A免密登录自己(B)的主机
对于非对称加密,公钥加密的密文不能公钥解开,只能用私钥解开。
| CSDN排版功能,垃圾! |
(2)免密码登录设置
| CSDN排版功能,垃圾! |
了解了SSH免密登录的原理后,下面我们就开始来设置免密登录了
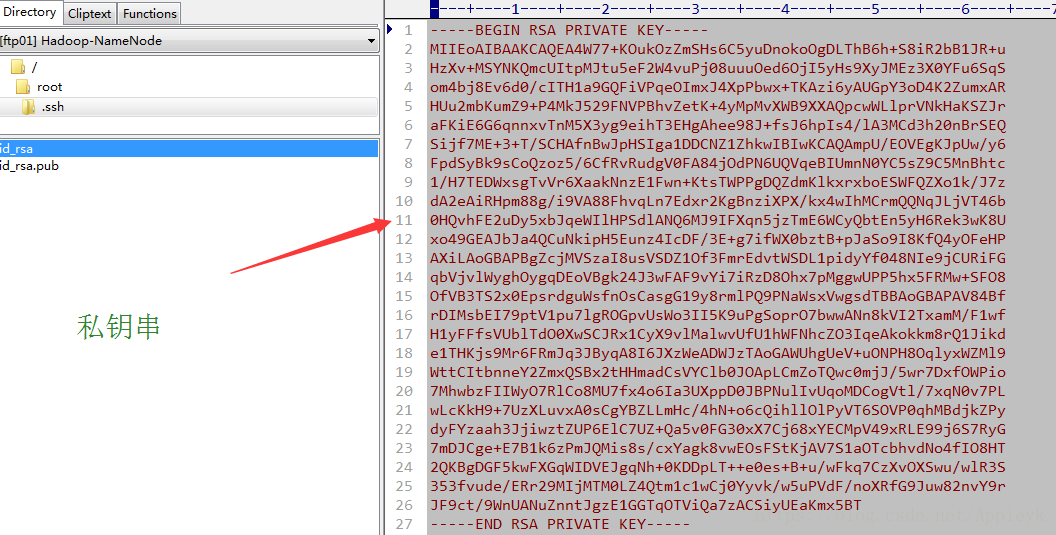
第一步:在NameNode所在的主机m1上,利用ssh-keygen命令生成公钥(id_rsa.pub)和私钥文件(id_rsa)
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
== -t 指定要生成秘钥的类型(type,rsa) -P '' 密码空, -f 指定生成的文件名 ~表示当前root目录
| CSDN排版功能,垃圾! |

| CSDN排版功能,垃圾! |
第二步:我们去/root/.ssh/ 目录下,查看一下是不是生成了这两个文件
| CSDN排版功能,垃圾! |

| CSDN排版功能,垃圾! |
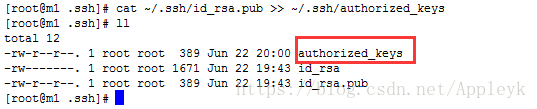
第三步:把m1生成的公钥添加到自己的authorized_keys文件【使用>>追加文件内容】中
| CSDN排版功能,垃圾! |
Linux输出重定向>和>>区别如下:
1.>: 会重写文件,如果文件里面有内容会覆盖。
2.>>这个是将输出内容追加到目标文件中。如果文件不存在,就创建文件。
3.>>:追加文件,也就是如果文件里面有内容会把新内容追加到文件尾。
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
| CSDN排版功能,垃圾! |
| CSDN排版功能,垃圾! |
第四步:连接自己验证免密登录
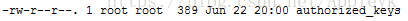
| CSDN排版功能,垃圾! |
注:由于authorized_keys文件的的当前用户(user)的权限具有rw(该文件不具备x执行权限),也就是读写权限,而当前用户是root,如果想让同用户组(group)或者其他用户(others)登录时,对这个文件也具有rw权限的话,需要用chomd命令修改该文件的权限,具体如何请查看相关文章
ssh m1
| CSDN排版功能,垃圾! |

| CSDN排版功能,垃圾! |
第一次登录的时候,会告诉你要建立信任关系,选择Yes后,无需输入密码即可登录成功
| CSDN排版功能,垃圾! |

| CSDN排版功能,垃圾! |
第五步:重复上述步骤,将DataNode1和DataNode2所在的主机也配置一下(省略)
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
| CSDN排版功能,垃圾! |
第六步:m1和s1、s2二者之间建立免密登录(Data节点之间不需要建立)
| CSDN排版功能,垃圾! |
原理:就是把m1的公钥发给s1和s2,并追加到s1和s2各自的authorized_keys文件中
先设置m1和s1之间的免密登录,m1和s2之间的同理
利用Linux的scp命令,将m1的公钥文件复制到s1上(也可以copy内容直接追加到s1的authorized_keys文件中)
Linux scp命令用于Linux之间复制文件和目录。
scp是 secure copy的缩写, scp是linux系统下基于ssh登陆进行安全的远程文件拷贝命令。
scp ~/.ssh/id_rsa.pub s1:~/.ssh/m1_rsa.pub
因为,m1和s1之间没有建立免密登录,所以,复制公钥文件的时候,连接s1需要输入密码(小意思啦)
| CSDN排版功能,垃圾! |

| CSDN排版功能,垃圾! |
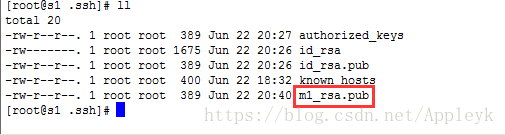
| CSDN排版功能,垃圾! |
m1的公钥拿到了,接着就是把m1的公钥密文追加到s1的authorized_keys文件中了,我们依然使用cat命令
cat ~/.ssh/m1_rsa.pub >> ~/.ssh/authorized_keys
| CSDN排版功能,垃圾! |

| CSDN排版功能,垃圾! |
ok,到这里我们就建立了m1到s1之间的SSH免密码登录,我们来试一下
| CSDN排版功能,垃圾! |

| CSDN排版功能,垃圾! |
ok,完美通过,由于m1和s2之间还未进行免密设置,因此,尝试下面的操作,会出现:
| CSDN排版功能,垃圾! |
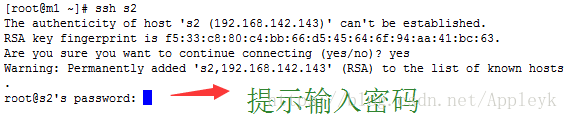
| CSDN排版功能,垃圾! |
这时候,我们只需要重复上面的操作,设置一下m1到s2之间的SSH免密登录就行了,过程略
| CSDN排版功能,垃圾! |
scp ~/.ssh/id_rsa.pub s2:~/.ssh/m1_rsa.pub == 在m1主机上操作
cat ~/.ssh/m1_rsa.pub >> ~/.ssh/authorized_keys == 在s2主机上操作
至此,NameNode和DataNode之间的SSH免密登录就设置完成了,接下来,就是安装Hadoop,配置集群环境了
| CSDN排版功能,垃圾! |
七、hadoop 3.1.0 下载
| CSDN排版功能,垃圾! |
| CSDN排版功能,垃圾! |
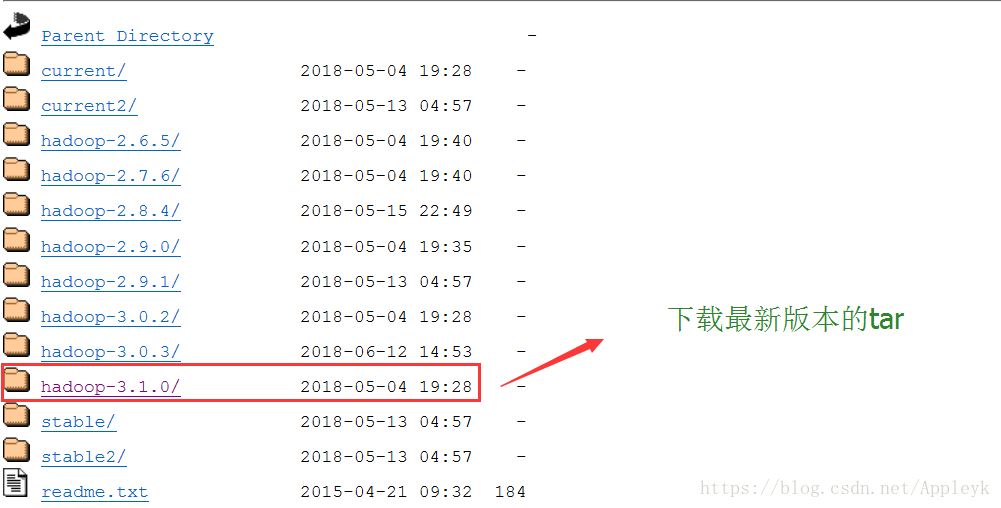

| CSDN排版功能,垃圾! |
也可以去我的百度网盘中下:hadoop-3.1.0.tar.gz
下完后,将压缩包上传至NameNode主机,放到/usr/local/目录下
| CSDN排版功能,垃圾! |
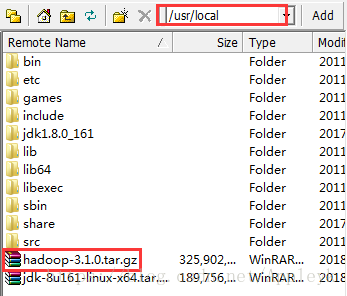
| CSDN排版功能,垃圾! |
解压命令 :tar
参数:
-v:显示操作过程
-f<备份文件>或--file=<备份文件>:指定备份文件;
完整命令,将tar包解压缩: tar -zxvf 文件名
| CSDN排版功能,垃圾! |
tar -zxvf hadoop-3.1.0.tar.gz
文件比较大,解压需要等待一会,解压完后,我们用editplus查看下hadoop的目录结构如下
| CSDN排版功能,垃圾! |

| CSDN排版功能,垃圾! |
| CSDN排版功能,垃圾! |
八、设置Hadoop 环境变量
| CSDN排版功能,垃圾! |
| CSDN排版功能,垃圾! |
export JAVA_HOME=/usr/local/jdk1.8.0_161
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export HADOOP_HOME=/usr/local/hadoop-3.1.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$JAVA_HOME/bin
| CSDN排版功能,垃圾! |
export使用方法:export PATH=$PATH:路径1:路径2:路径N;$PATH为系统变量
| CSDN排版功能,垃圾! |
| CSDN排版功能,垃圾! |
使用source命令,使修改后的profile文件立即生效
| CSDN排版功能,垃圾! |
source /etc/profile
| CSDN排版功能,垃圾! |

查看hadoop环境变量是否已添加,打印hadoop的版本信息如下
| CSDN排版功能,垃圾! |
hadoop version
| CSDN排版功能,垃圾! |
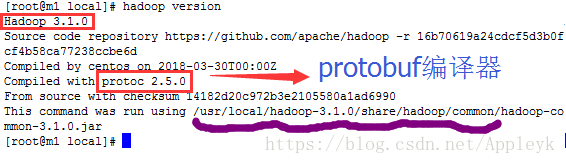
注:Hadoop环境变量只需要在NameNode所在的主机上配置就行,DataNode节点无需配置
| CSDN排版功能,垃圾! |
| CSDN排版功能,垃圾! |
九、Hadoop 配置文件
| CSDN排版功能,垃圾! |
| CSDN排版功能,垃圾! |
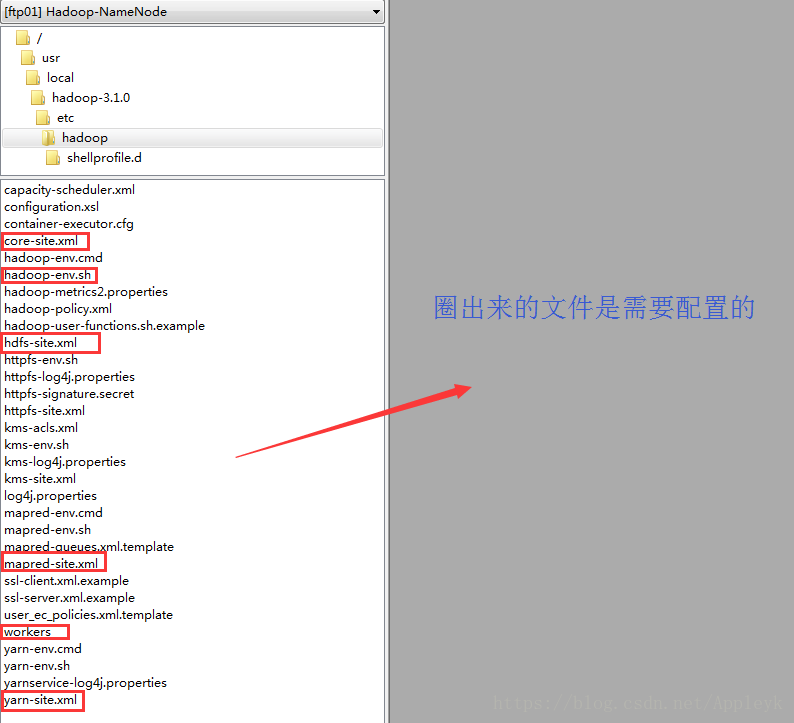
| CSDN排版功能,垃圾! |
core-site.xml : Hadoop Core的配置项,例如HDFS和MapReduce常用的I/O设置等。
hadoop.env-sh : Hadoop是Java开发的且运行在JVM上,因此需要在hadoop环境里面配置JDK
hdfs-site.xml : 配置HDFS(分布式文件系统)
mapred-site.xml : 配置MapReduce
workers : 配置从节点(DataNode主机名或主机IP地址)
yarn-site.xml : 配置资源管理和作业调度/监控器(ResourceManager)
| CSDN排版功能,垃圾! |
(1)配置hadoop-env.sh,添加JDK
| CSDN排版功能,垃圾! |

| CSDN排版功能,垃圾! |
(2)配置core-site.xml,指定hadoop的FileSystem的url及hadoop文件dir
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://m1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/tmp</value>
</property>
</configuration>hadoop.tmp.dir 是hadoop文件系统依赖的基础配置,很多路径都依赖它。如果hdfs-site.xml中不配置namenode和datanode的存放位置,默认就放在这个路径中,如果不配置这个路径,启动hadoop的时候会报错。

(3)配置hdfs-site.xml,指定hadoop的namenode和datanode节点的文件dir
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>s1:9001</value>
</property>
<property>
<name>dfs.http.address</name>
<value>0.0.0.0:50070</value>
</property>
</configuration>hadoop的secondary namenode(辅助namnode) 跑在s1主机上,以免namenode所在的主机挂掉了,影响整个集群
dfs.http.address 50070:NameNode web 管理端口
(3)配置mapre-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.job.tracker.http.address</name>
<value>0.0.0.0:50030</value>
</property>
<property>
<name>mapred.task.tracker.http.address</name>
<value>0.0.0.0:50060</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>
/usr/local/hadoop-3.1.0/etc/hadoop,
/usr/local/hadoop-3.1.0/share/hadoop/common/*,
/usr/local/hadoop-3.1.0/share/hadoop/common/lib/*,
/usr/local/hadoop-3.1.0/share/hadoop/hdfs/*,
/usr/local/hadoop-3.1.0/share/hadoop/hdfs/lib/*,
/usr/local/hadoop-3.1.0/share/hadoop/mapreduce/*,
/usr/local/hadoop-3.1.0/share/hadoop/mapreduce/lib/*,
/usr/local/hadoop-3.1.0/share/hadoop/yarn/*,
/usr/local/hadoop-3.1.0/share/hadoop/yarn/lib/*
</value>
</property>
</configuration>(4)配置yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>m1:8099</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4906</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>1</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4906</value>
</property>
</configuration>(5)配置workers(早前的版本是slaves)
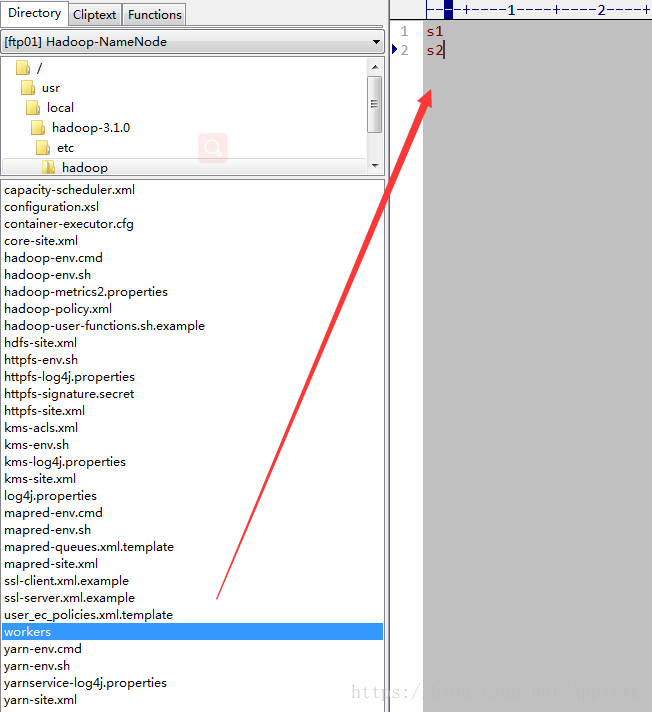
(6)重复上述步骤,将配置好的hadoop文件目录拷贝到s1和s2主机上
scp -r /usr/local/hadoop-3.1.0 root@s1:/usr/local/
scp -r /usr/local/hadoop-3.1.0 root@s2:/usr/local/
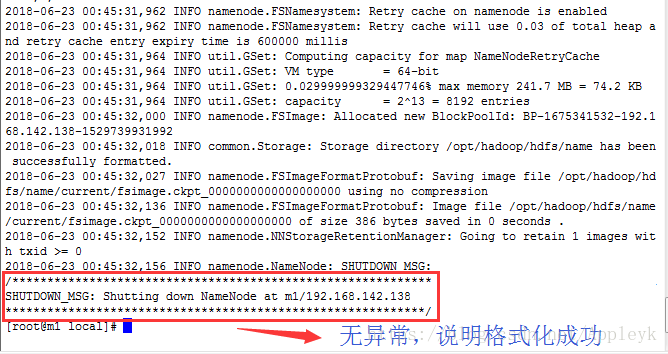
十、格式化NameNode
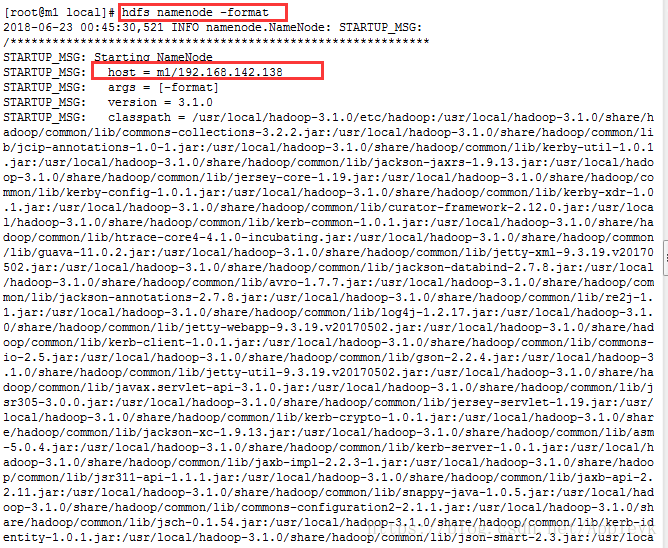
十一、启动Hadoop集群
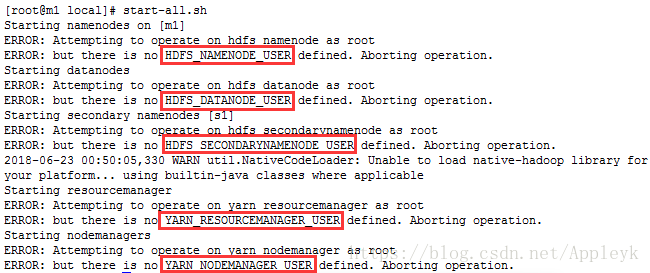
hdfs 和 yarn 缺少root用户定义,因为当前我们使用的是root执行的start脚本,其识别不了root用户,因此,我们需要分别在hdfs和yarn的启动和停止脚本文件中,追加内容如下:
vim start-dfs.sh
vim stop-dfs.sh
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
vim start-yarn.sh
vim stop-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
然后再次启动(jps是java的查看进程的命令)

s1主机上查看(DataNode和辅助NameNode守护进程已启动)

s2主机上查看(只启动了一个DataNode守护进程)

使用hadoop 的 fs文件系统,列出根目录下的文件列表
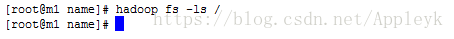
当前还未有任何文件传至fs文件系统的根目录下,我们用put传一个文件试试,该文件位于/root下
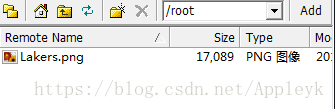
先将其传至fs的根目录下,命令如下
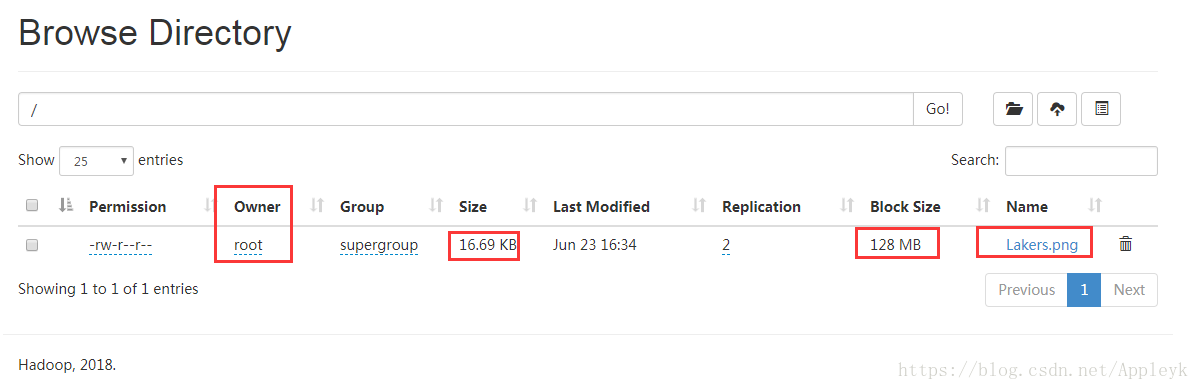
hadoop fs -put /root/Lakers.png /

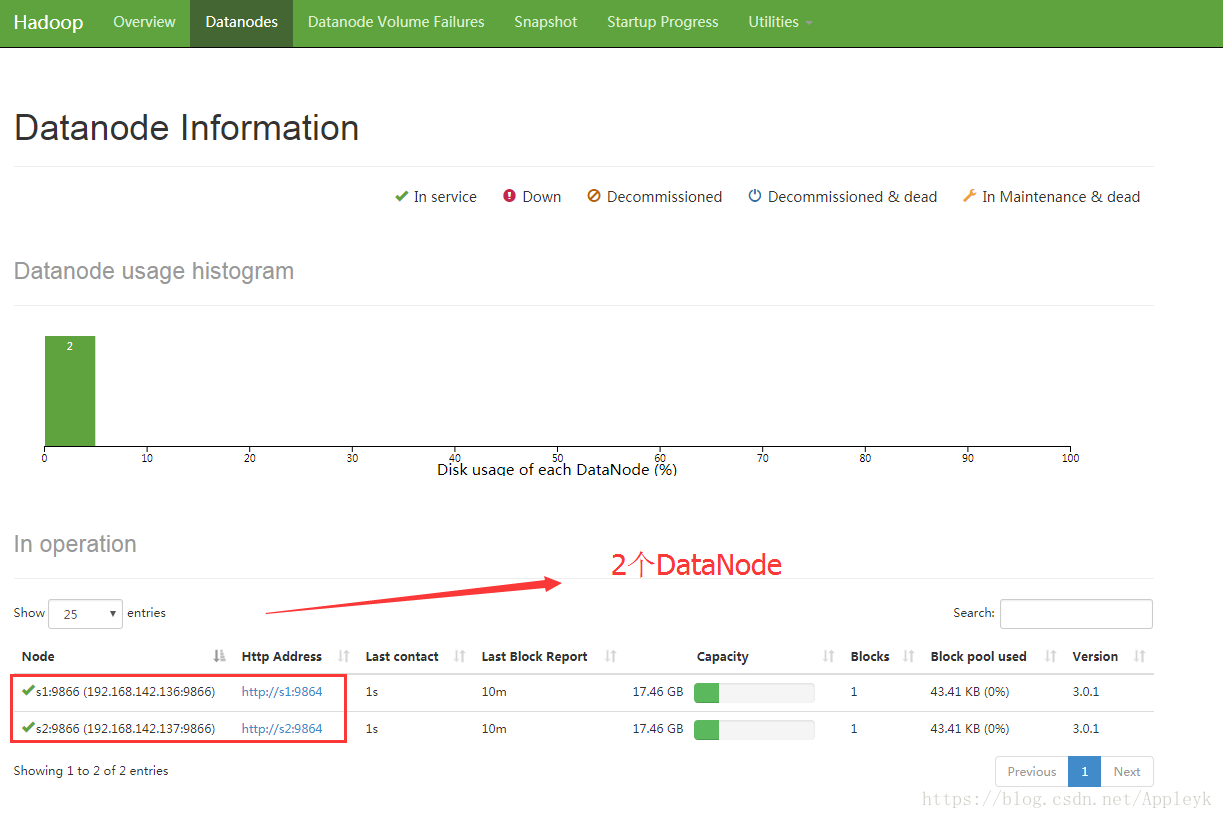
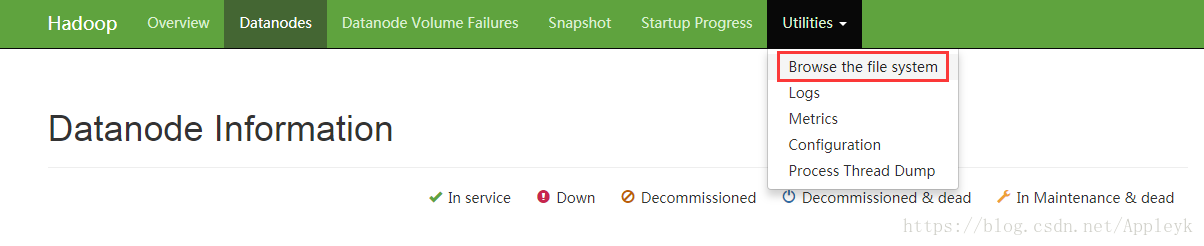
十二、浏览器打开NameNode的Web界面
地址:http://192.168.142.138:50070 == 如何IP换成主机名m1,请在Windows下进行hosts文件的修改

切换到DataNodes进行查看

针对刚才上传的Lakers.png,我们可以通过下面的方式进行文件浏览
浏览信息如下(当前为文件系统的根目录/)
选中文件,我们可以下载至本地系统
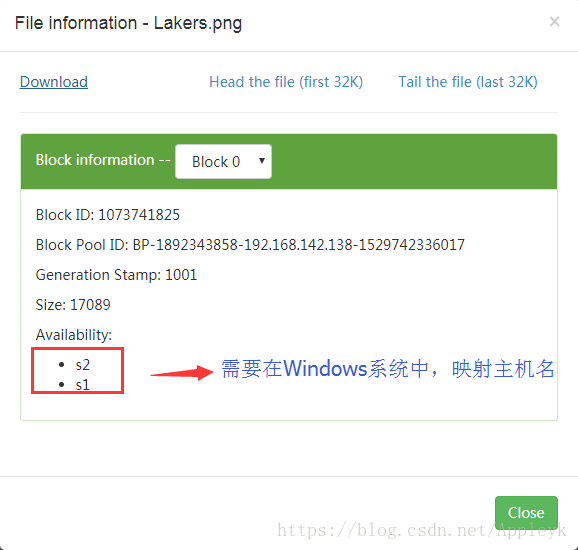
修改hosts文件,添加如下映射(C:\Windows\System32\drivers\etc\hosts)