关于hadoop模式三种的了解,请自行百度了解,此文只说明伪分布式的搭建
前提:jdk(hadoop是有java语言完成的,必须有jdk支持)
可以参考我的经验 --- > Linux-CentOS-6.5下配置JDK
一、准备工作
1、下载hadoop
地址:http://hadoop.apache.org/releases.html
2、关闭防火墙 - 为了方便之后操作
以下操作重启后会失效,说明,CentOS 7命令不一样
# 查看防火墙当前状态
service iptables status
# 开启防火墙
service iptables start
# 关闭防火墙
service iptables stop以下操作重启后生效(即不需要每次开机都必须去关闭防火墙)
# 查看防火墙当前状态
chkconfig | grep iptables
# 开启防火墙
chkconfig iptables on
# 关闭防火墙
chkconfig iptables off3、配置主机名
注意主机名不要有下划线
vim /etc/sysconfig/network使上面命令生效
source /etc/sysconfig/network说明:此处可以重启(reboot重启后,进入该文件查看是否修改成功)
4、配置hosts
vim /etc/hosts填写ip地址与主机名,例如 192.168.91.134 hadoop01
5、配置之间免密互通
生成公钥、私钥
ssh-keygen将公钥copy到本主机
# ssh-copy-id [登录名]@[host/ip地址]
ssh-copy-id [email protected]测试,若没有提示输入密码。则说明免密互通设置成功
# ssh [host/ip地址]
ssh 192.168.91.134二、hadoop解压
# tar -zxvf [hadoop安装包位置] -C [指定目录]
tar -zxvf /home/software/hadoop-2.7.1_64bit.tar.gz -C /home/software/二、hadoop相关配置 - 以下文件都位于hadoop/etc/hadoop/*
1、修改hadoop-env.sh
# vim [hadoop]/etc/hadoop/hadoop-env.sh
vim hadoop-env.sh在hadoop-env.sh中,第27行,修改到安装目录
# 安装目录
export JAVA_HOME=/usr/java/jdk1.8.0_1312、修改core-site.xml - 注意目录为自己本机安装目录
# vim [hadoop]/etc/hadoop/core-site.xml
vim core-site.xml<configuration>
<property>
<!--用来指定hdfs的老大,namenode的地址-->
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:9000</value>
</property>
<property>
<!--用来指定hadoop运行时产生文件的存放目录-->
<name>hadoop.tmp.dir</name>
<value>/home/software/hadoop-2.7.1/tmp</value>
</property>
</configuration>3、修改 hdfs-site.xml
# vim [hadoop]/etc/hadoop/hdfs-site.xml
vim hdfs-site.xml<configuration>
<property>
<!--指定hdfs保存数据副本的数量,包括自己,默认为3-->
<!--伪分布式模式,此值必须为1-->
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>4、修改 mapred-site.xml
说明:在/etc/hadoop的目录下,只有一个mapred-site.xml.template文件,复制一个 cp mapred-site.xml.template mapred-site.xml
# vim [hadoop]/etc/hadoop/mapred-site.xml
vim mapred-site.xml<configuration>
<property>
<!--指定mapreduce运行在yarn上-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>5、修改 yarn-site.xml
# vim [hadoop]/etc/hadoop/yarn-site.xml
vim yarn-site.xml<configuration>
<property>
<!--指定yarn的老大resourcemanager的地址-->
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<property>
<!--NodeManager获取数据的方式-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>6、修改 slaves
# vim [hadoop]/etc/hadoop/slaves
vim slaves这里只需将主机名填写进去即可
7、配置hadoop的环境变量
vim /etc/profile# hadoop安装位置
export HADOOP_HOME=/home/software/hadoop-2.7.1/
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin重新加载profile使配置生效 source /etc/profile
环境变量配置完成,测试环境变量是否生效 echo $HADOOP_HOME
8、重启linux - reboot
不是必须的,但建议执行
9、格式化namenode
进入 hadoop/bin 输入命令格式化
# 以前命令 hdfs namenode -format
hadoop namenode -format若是成功的话,可以再输出的日志倒数第七行看到
Storage directory /tmp/hadoop-root/dfs/name has been successfully formatted
10、启动hadoop
在/home/app/hadoop-2.6.0/sbin目录下
start-all.sh启动成功后,输入 jps 命令(jdk自带的,这里由于配置了环境变量所以任何地方可以使用)会看到如下五个输出
1825 SecondaryNameNode
1988 ResourceManager
2087 NodeManager
2408 Jps(忽略)
1532 NameNode
1630 DataNode
到此伪分布式集群搭建成功
小扩展:
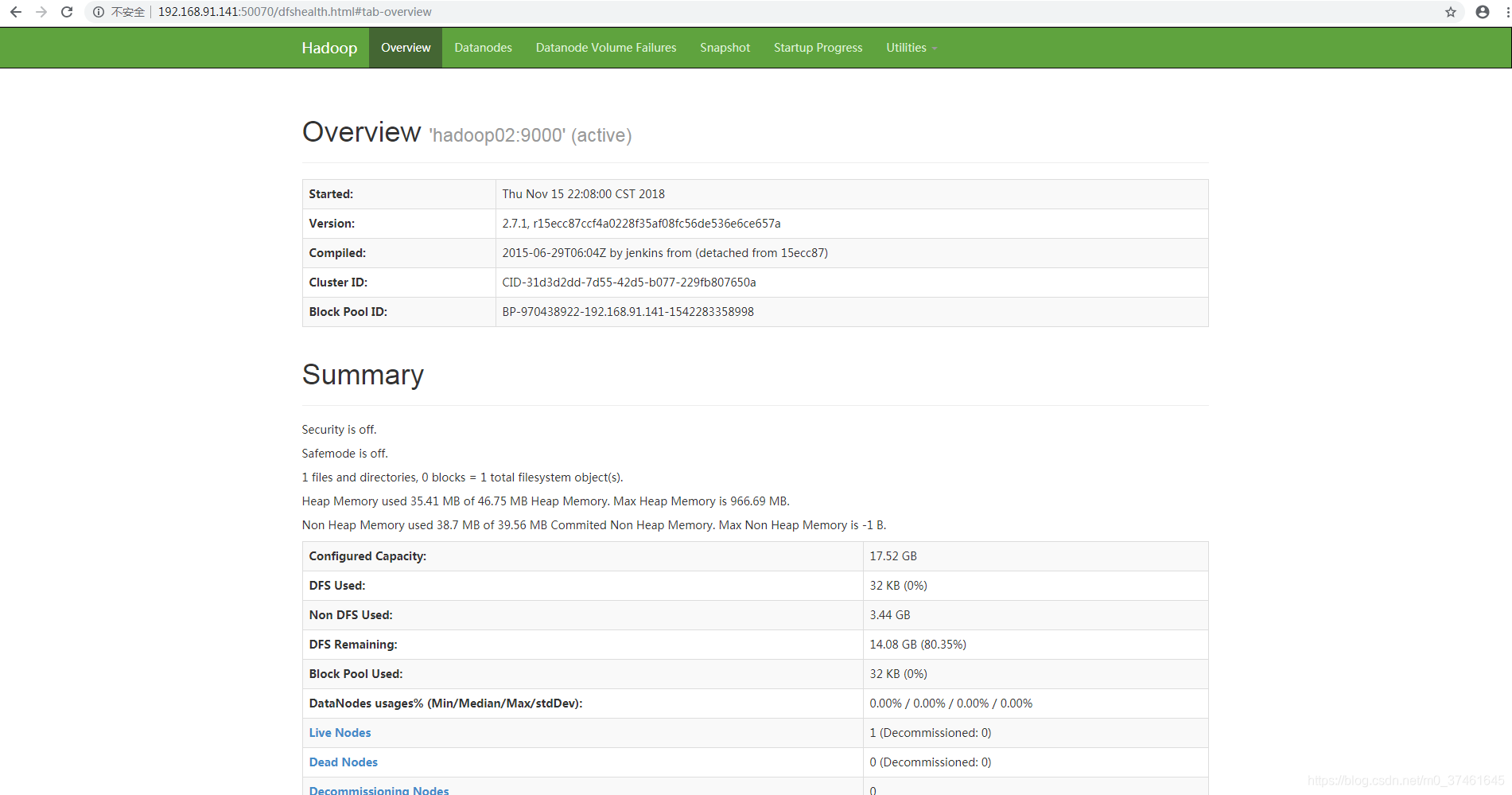
1. 在外部输入http://[ip地址]:50070 可以看到如下
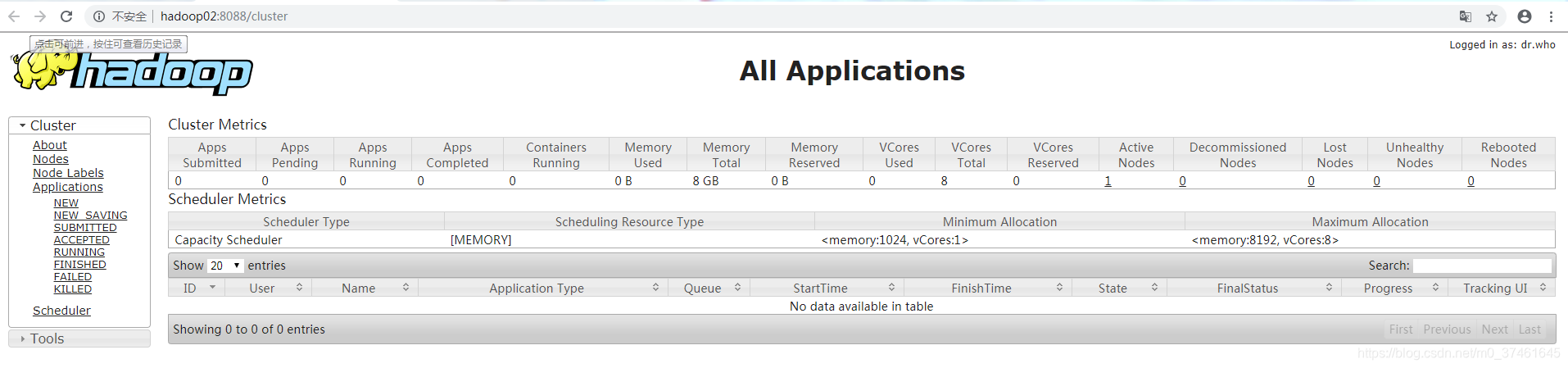
2. 在外部输入http://[ip地址]:8088 可以看到如下