Loss function and optimization
Loss function
损失函数是告诉我们目前分类器表现性能的好坏。
给定数据集
,损失函数定义为
即将每一个样本的损失函数求和取平均。
Multiclass SVM loss
该损失函数认为如果其余类别的预测值与真实类别的预测值值的差值小于-1那么认为该预测是正确的,不计损失;如果差值大于1,那么预测错误需要记录损失(1为margin,根据任务需要进行调节)。
当loss function很小时,说明对训练集很好的拟合,但是如果过于拟合训练集会使得模型很复杂,无法对测试集做出很好的预测,因此需要‘简化’模型,即Regularization
常用的正则化方法:
- L2 regularization
- L1 regularization
- Elastic net(弹性网络)
- Max norm regularization
- Dropout
- batch normalization, stochastic depth
Softmax
只对实际类别的概率求log。
两种方法对比
Softmax可以使正确分类的预测值趋于正无穷,错误分类的预测值趋于负无穷,使得效果一直存在提升
SVM则使正确的变大,错误的变小,当满足正确与错误之间间隔大于margin时,即实现最优化
Optimization
更新值计算方法
随机取值
每次随机选择 ,如果loss变小,那么就更新 ,效果明显不好
每次更新一个值
根据一维方向导数的计算
我们每次对
的一个值
增大
,即
,计算更新
后的loss,再将loss带入上式,求出一个方向导数即为
增大位置
的更新值。
计算慢
analytic gradient
直接计算
Gradient descent
Stochastic Gradient Descent(SGD):使用一部分训练集计算梯度用来更新权重
Image Feature
定义:将图像通过提取特征进行表述,可以有效降低图像的维度
- Color Histogram:通过建立一个颜色的直方图来表示图片
- Histogram of Oriented Gradient:详细介绍见 https://blog.csdn.net/zouxy09/article/details/7929348
文中提到了梯度的计算和梯度大小的处理 - Bag of Word:该方法是从每个图像中提取部分特征,对特征进行归一化构造一个字典(根据KNN将多个特征归类到一个word),对于输入图像在提取特征之后,将特征归类到某个 word中,构造一个基于word的直方图。特征提取方法可以用SIFT。
相关知识
SIFT介绍
参考资料:
https://blog.csdn.net/abcjennifer/article/details/7639681
https://opencv-python-tutroals.readthedocs.io/en/latest/py_tutorials/py_feature2d/py_sift_intro/py_sift_intro.html
SIFT 的步骤分为4步:
- 对于一张图片建立其不同尺度下的图像(为了能够发现各个尺度下的特征点),每个尺度的图像建立一个图像塔(octave),每一个图像塔的下一层是对上一层做Laplacian变换得到。如图
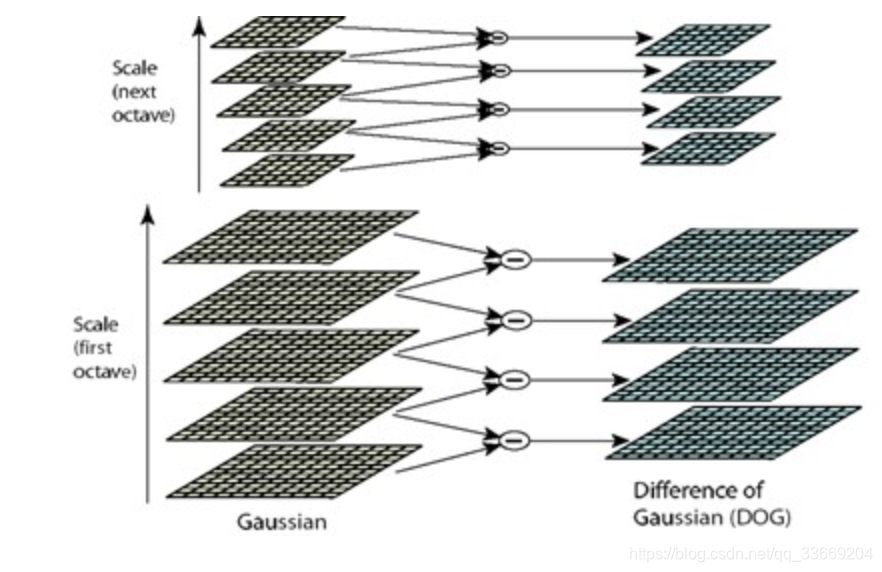
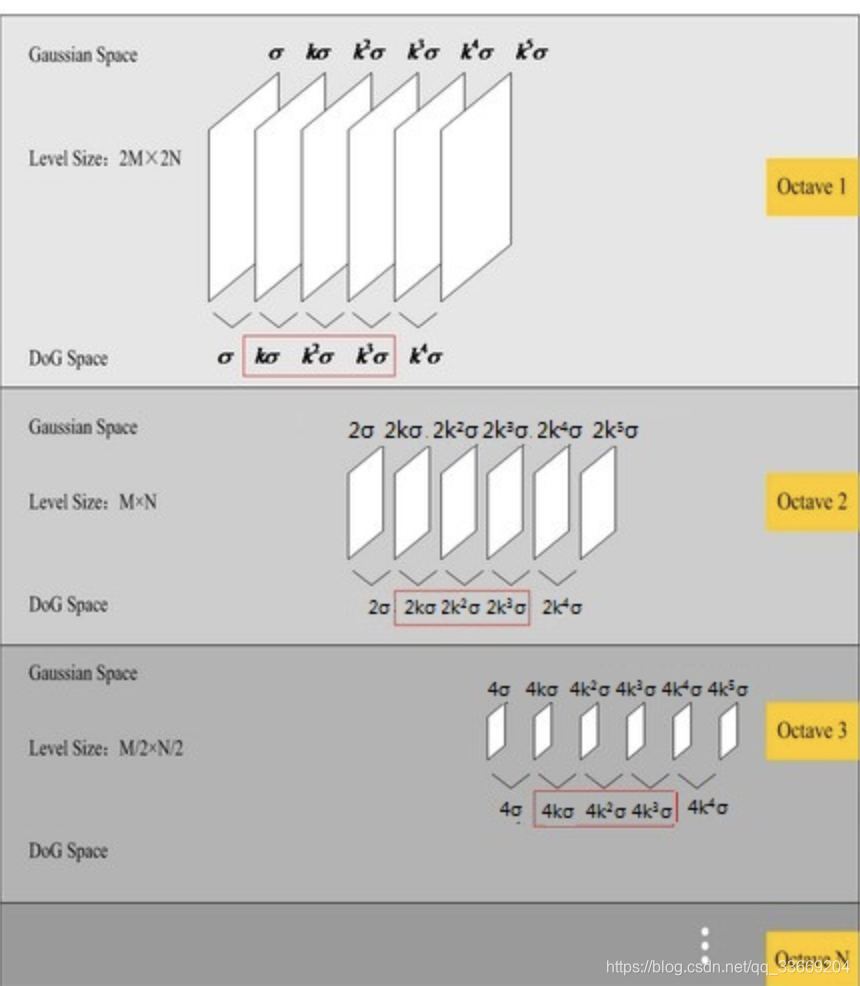
为了寻找尺度空间的极值点,每一个采样点要和它所有的相邻点比较,看其是否比它的图像域和尺度域的相邻点大或者小。如图所示,中间的检测点和它同尺度的8个相邻点和上下相邻尺度对应的9×2个点共26个点比较,以确保在尺度空间和二维图像空间都检测到极值点。 一个点如果在DOG尺度空间本层以及上下两层的26个领域中是最大或最小值时,就认为该点是图像在该尺度下的一个特征点。
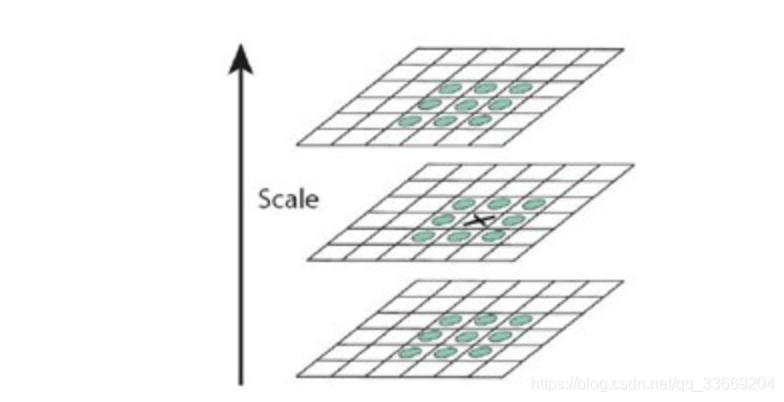
- keypoint的确定:步骤1找到了所有可能的keypoint,为了能进行更准确的判断,需要对keypoint进行一些删减。
- 空间尺度的泰勒展开式,低于阈值的特征点删除,从而获得更准确的极值位置
- 由于keypoint的确定是基于DoG方法,因此会有很多边缘信息。使用2*2的Hession矩阵计算曲度,大于阈值的keypoint删除
- keypoint表述:在获取keypoint之后,我们取keypoint一定大小的周边区域,如1616,来求解keypoint的表述。我们将1616大小的区域划分为16块4*4的区域,对每个区域的像素求梯度,根据梯度的方向划分梯度直方图(通常将360度划分为8个bins),根据梯度的大小增加梯度直方图的权重,比如方向为10度的梯度,大小为2,那么将其归类到0-45度的bins,该bins的权重增大2,这样每个keypoint表述为128维的向量
完整的SIFT算法还有特征的匹配,由于这里只需要一个特征表述,因此不需要匹配。
"""
opencv实现
只适应于opencv3以下的版本,如果opencv3版本,处理方法见:https://stackoverflow.com/questions/52305578/sift-cv2-xfeatures2d-sift-create-not-working-even-though-have-contrib-instal
"""
import cv2
import numpy as np
img = cv2.imread('home.jpg')
gray= cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
sift = cv2.SIFT()
kp = sift.detect(gray,None)
img=cv2.drawKeypoints(gray,kp)
cv2.imwrite('sift_keypoints.jpg',img)
opencv3以上版本SIFT调用
参考:https://www.jianshu.com/p/a6b846a32905
#coding=utf-8
#注意如果脚本中要使用中文,则需要指明编码格式
import cv2
import sys
#imgpath为图像路径
imgpath = sys.argv[1]
# 将图像读取进来, 基本可以支持任意标准格式的文件
# imread(filename, [flags]), flags表示图像的色彩,可选
img = cv2.imread(imgpath)
# 将图像转化为灰度图像
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 构造一个sift对象
sift = cv2.xfeatures2d.SIFT_create()
# 检测关键点和对应的描述子
#cv2.SIFT.detectAndCompute(image, mask[, descriptors[, useProvidedKeypoints]])
# 如果需要在图像中的某一个区域识别,则设置mask
keypoints, descripter = sift.detectAndCompute(gray,None)
# keypoints给定特征点位置,descripter给定特征点的向量内容
flags = cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS
color = (51, 163, 236)
# 绘制关键点
# cv2.drawKeypoints(image, keypoints[, outImage[, color[, flags]]])
img = cv2.drawKeypoints(gray, keypoints, color, flags)
cv2.imshow('sift_ketpoints', img)
while (True):
if cv2.waitKey(1000 / 12) & 0xff == ord('q'):
#按q时退出
break
cv2.destroyAllWindows()
分离高斯模糊
参考:https://blog.csdn.net/zddblog/article/details/7521424
使用二维的高斯模板达到了模糊图像的目的,但是会因模板矩阵的关系而造成边缘图像缺失,
越大,缺失像素越多,丢弃模板会造成黑边。更重要的是当
变大时,高斯模板(高斯核)和卷积运算量将大幅度提高。根据高斯函数的可分离性,可对二维高斯模糊函数进行改进。
高斯函数的可分离性是指使用二维矩阵变换得到的效果也可以通过在水平方向进行一维高斯矩阵变换加上竖直方向的一维高斯矩阵变换得到。从计算的角度来看,这是一项有用的特性,因为这样只需要次计算,而二维不可分的矩阵则需要次计算,其中,m,n为高斯矩阵的维数,M,N为二维图像的维数。
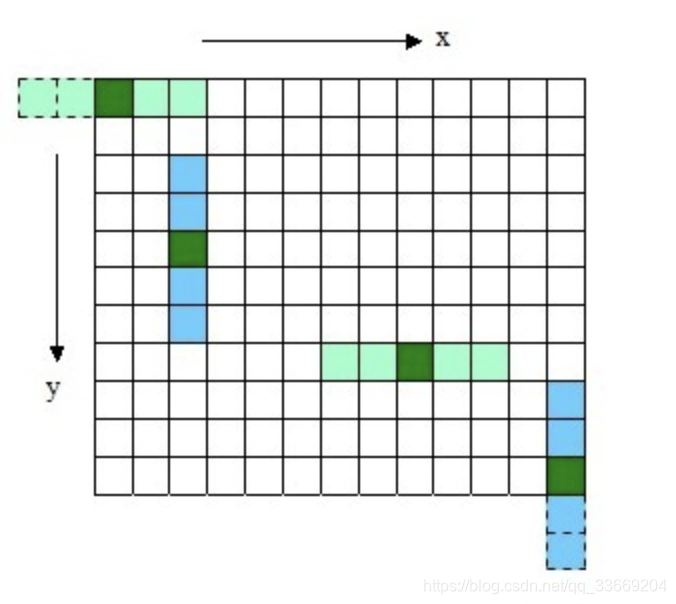
另外,两次一维的高斯卷积将消除二维高斯矩阵所产生的边缘。(关于消除边缘的论述如下图所示, 对用模板矩阵超出边界的部分——虚线框,将不做卷积计算。如图2.4中x方向的第一个模板15,将退化成13的模板,只在图像之内的部分做卷积。)
LOG算子
SIFT通过DOG算子来近似LOG算子,LOG算子的解释:https://blog.csdn.net/songzitea/article/details/12851079
SURF方法
Harr特征:https://blog.csdn.net/q123456789098/article/details/52748918
根据Harr特征理解SURF算法:https://blog.csdn.net/dcrmg/article/details/52601010