以cat为例:
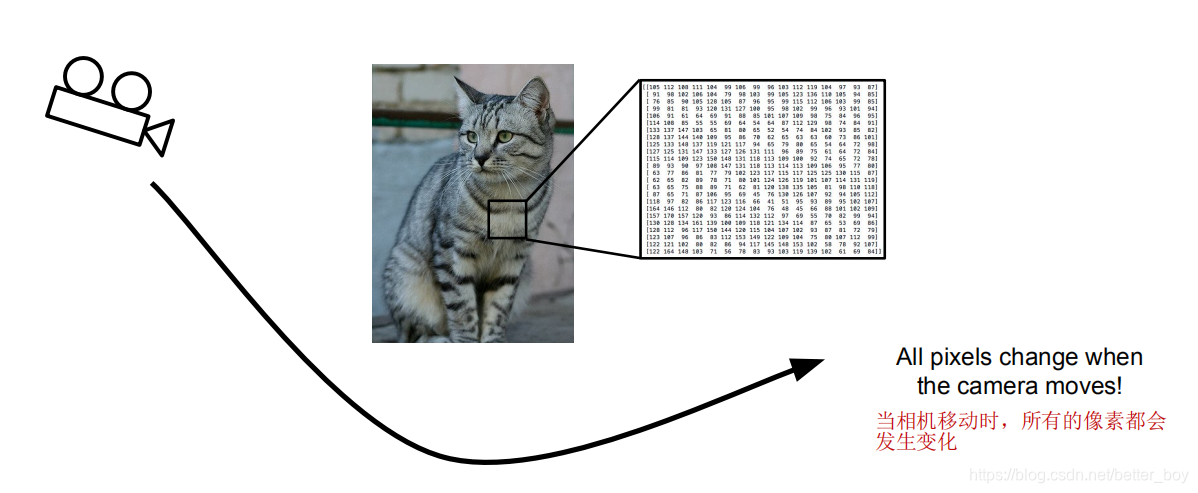
计算机识别cat标签遇到的困难(这里以猫为例)
1.光线的亮度
2.猫不同姿势
3.猫被其他物理挡住,剩下一部分可见
4.背景干扰
5.类内差异(猫的颜色、大小等)
6.观察的视角变化等
实际上并没有明显的方法来认出猫,或其他类(狗、鹿、分机等)
图像分类的流程:
1.收集大量的数据集,给他们打上定义的标签。
2.通过机器学习认知已收集的数据集长什么样,具有同一标签的共同特征,然后以某种方式形成一个训练模型(分类器),该模型总结了如何识别不同的对象类别。
3.最后我们将训练模型应用到新的图像上,从而可以识别猫、狗、鱼、卡车等。
使用L1和L2距离的分类器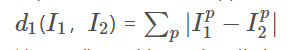

从几何角度来讲L2比L1更能反应2张图像之间的差异,但是要具体情况具体分析,使用两者,哪个效果好用哪个。
K-Nearest Neighbor分类器
思想:
针对需要测试的图片,我们寻找最相似的K个图像的标签,依次对测试图片进行投票,将票数最高的图像的标签作为测试图片的标签。(K=1时,就是Nearest Neighbor分类器,不做详尽叙述)K值如何决定(当然是尝试不同的值,哪个好用哪个了)
###一般我们会将数据分为训练集和测试集,测试集是你最终得出结论的重要依仗,因此我们会使用训练集中的一部分数据来测试最佳K值,而这一部分数据称为验证集。
交叉验证
例如:将训练集平均分成3大份,将其中每一份也分成3份,2份用来训练,1份用来验证,然后我们循环着取其中2份来训练,1份来验证,最后取所有3次验证结果的平均值作为算法验证结果。(具体实践暂时不懂)
c3d的数据分割模式
以3:1的分为训练集和测试集,k值的确定有待考究。后续补上。然后模型训练完毕后,使用模型跑一次测试集,以此次结果来评价所使用的算法的优劣。