注:本文所有的例子都来自于《正则表达式必知必会(修订版)》。
正则表达式的作用是用来检索文本或替换文本。如:
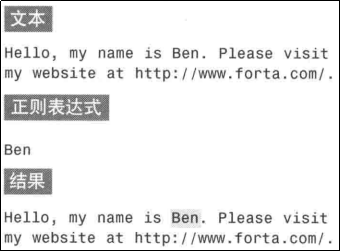
(绝大多数正则表达式引擎的默认行为是返回第1个匹配结果。)
正则表达式中一个非常重要的概念就是元字符,你可以不用去理什么限定符、定位符之类,只要记住它们都是元字符就行。
基本元字符
| 元字符 | 说明 |
| | | 逻辑或操作符 |
| \ | 转义符 |
| . | 匹配单个任意字符。如果想匹配多个,就用多个. |
| [] | 字符区间。如[0123456789],则匹配0或1或2或3或4... |
| [ - ] | 连字符。如[0-9]等价于[0123456789]。 |
| [^ ] | 取非。取非字符区间,如[^0-9],则匹配非数字。 |
基本元字符(\)

基本元字符(.)

基本元字符([])

基本元字符([ - ])

基本元字符([^ ])


数量元字符
| 元字符 | 说明 |
| ? | 匹配前一个字符0次或1次 |
| * | 匹配前一个字符0次或多次 |
| + | 匹配前一个字符1次或多次 |
| {n} | 匹配前一个字符n次 |
| {n,m} | 匹配前一个字符至少n次至多m次 |
| {n,} | 匹配前一个字符至少n次 |
数量元字符(?)

数量元字符(*)
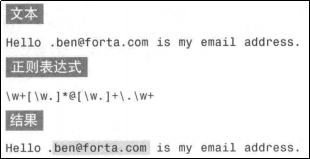
数量元字符(+)
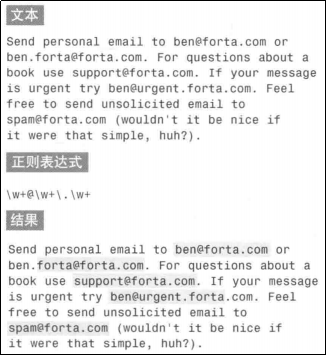
数量元字符({n})


数量元字符({n,m})

数量元字符({n,})

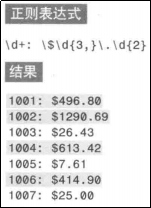
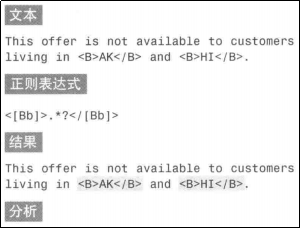
贪婪型
正则表达式中的元字符有一些是贪婪型的,它会从文本的开头一直匹配到文本的结尾,忽略中间的匹配。看一个例子或许你就会明白:
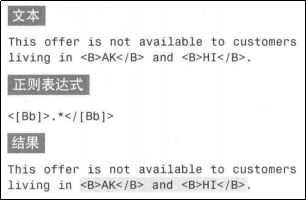
上面的匹配结果肯定不是我们所期望的。
| 贪婪型元字符 | 懒惰型元字符 |
| * | *? |
| + | +? |
| {n,} | {n,}? |
位置元字符
| 元字符 | 说明 |
| ^ | 匹配字符串的开头 |
| $ | 匹配字符串的结尾 |
| \b | 匹配单词边界(开头和结尾) |
| \B | 匹配非单词边界 |
位置元字符(^)

位置元字符($)

位置元字符(\b)

位置元字符(\B)

特殊元字符
空白元字符
| 元字符 | 说明 |
| [\b] | 回退并删除一个字符 |
| \f | 匹配换页符 |
| \n | 匹配换行符 |
| \r | 匹配回车符 |
| \t | 匹配制表符 |
| \v | 匹配垂直制表符 |

数字元字符
| 元字符 | 说明 |
| \d | 匹配任何一个数字,等价于[0-9] |
| \D | 匹配任何一个非数字字符,等价于[^0-9] |

字母数字元字符
| 元字符 | 说明 |
| \w | 匹配任何一个数字字符或下划线,等价于[a-zA-Z0-9_] |
| \W | 匹配任何一个非数字或非下划线字符,等价于[^a-zA-Z0-9_] |

空白字符元字符
| 元字符 | 说明 |
| \s | 匹配任何一个空白字符,等价于[\f\n\r\t\v] |
| \S | 匹配任何一个非空白字符,等价于[^\f\n\r\t\v] |
大小写转换元字符
| 元字符 | 说明 |
| \l | 把下一个字符转换为小写 |
| \u | 把下一个字符转换为大写 |
| \L | 把\L到\E之间的字符全部转换为小写 |
| \U | 把\U到\E之间的字符全部转换为大写 |
| \E | 结束\L或\U转换 |
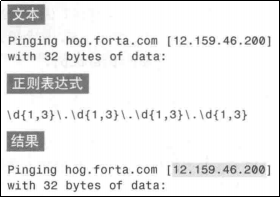
子表达式()
之前的数量元字符只能作用前面的一个字符,如果想作用一长串字符串的话就得使用子表达式。
子表达式是一个更大的表达式的一部分;把一个表达式划分为一系列子表达式的目的是为了把那些子表达式当作一个独立元素来使用。



回溯引用 \1
这个概念光看名字很难理解,看一个例子或许就知道了:
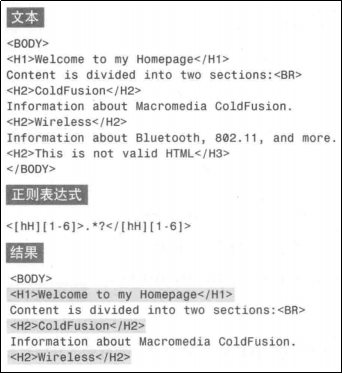

上面的“<H2>This is not valid HTML</H3>”就不是我们所期望的匹配。
这种问题必须使用回溯引用才能解决。
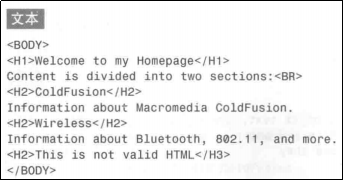
\1是一个回溯引用。它代表着正则表达式里的第一个子表达式,\2代表着第二个子表达式,以此类推。
前后查找
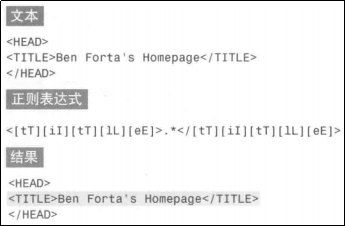
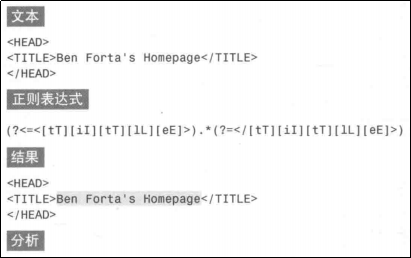
上面的例子可能符合正则表达式的匹配,但是如果我们只想匹配出title里的内容该怎么办呢?
这时候就需要向前或向后查找了。
向前查找 ?=
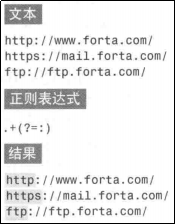
只匹配:前的内容。
向后查找 ?<=

只匹配$后面的内容。
各种前后查找操作符
| 操作符 | 说明 |
| (?=) | 向前查找 |
| (?<=) | 向后查找 |
| (?!) | 负向前查找 |
| (?<!) | 负向后查找 |

负向后查找,只匹配那些不以$开头的数值。
嵌入条件
回溯引用条件
嵌入条件语法使用了?,它的语法格式是“(?(回溯引用)子表达式)”,看一个例子你就会懂得。
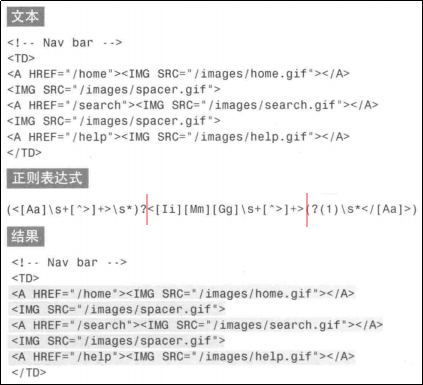
“(<[Aa]\s+[^>]+>\s*)?”这里将匹配0个或1个<A>或<a>标签以及<A>或<a>标签的任意属性;
“<[Ii][Mm][Gg]\s+[^>]+>”这里将匹配一个img标签及任意属性;
“(?(1)\s*</[Aa]>)”就是一个回溯引用条件,“?(1)”的作用就是当前面的第一个子表达式匹配成立时,才会执行“\s*</[Aa]>”这个子表达式的匹配。
也就是前面匹配到了<A>标签后面才会匹配</A>标签。
前后条件查找

向前查找存在时,才去匹配“-\d{4}”。