元字符分类
1.字符匹配
. 表示匹配的任意单个字符
2.匹配次数
* 前面的字符出现任意次,包含0次
\? 前面的字符出现0次或者1次
\+ 前面的字符出现1次或者多次
\{n,m\} 前面的字符至少出现n次,最多出现m次
3.位置锚定
正则表达式默认的查找方式是包含,不限定指定字符串出现的位置.
行首 ^
行尾 $
单词词首 \<
单词词尾 \>
4.分组
\( \)

正则表达式组合用法示例
1.如何去掉数字后面的百分号或者其它特殊符号 对已经过滤后的结果再次进行grep即可实现相应的效果 相当于多次grep


2.cat /etc/fstab | grep -v "^#" | grep -v "^[[:space:]]*$"
[[:space:]]* 当正则表达式中出现匹配次数的时候,它和前面的字符表达式应该当作一个整体
[[:space:]] 表示某行中必须出现一个空格
[[:space:]]* 表示某行中可以不出现空格或者出现1次和任意次空格,它并不是表示必须先出现一个空格然后再判断在空格后面可以出现或者不出现空格
3.分组匹配的结果
\1 表示的是前面的分组正则表达式匹配到的结果字符串,而不是正则表达式模式本身.前面(r..t)匹配到的字符串是root,所以\1表示的是root而不是 r..t

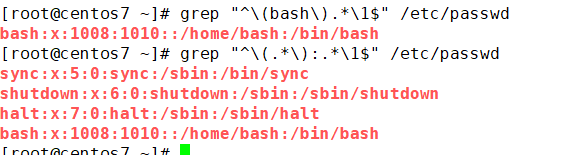
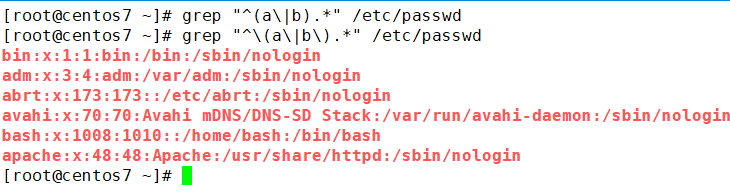

正则表达式 或者的语法
1. echo axy | grep "a\|bxy" 表示需要匹配字符a或者字符串bxy 而不是匹配 axy 或者 bxy
2. echo axy | grep "(a\|b)xy" 表示匹配 axy 或者匹配 bxy