正则表达式(Regular Expression)是文本处理中的基本功,是做一名自然语言处理工作者的必备技能。本文主要在了解、应用过正则的基础上,进一步提升,深入学习的指导。
正则表达式是处理字符串的强大工具,拥有独特的语法和独立的处理引擎。
我们在大文本中匹配字符串时,有些情况用str自带的函数(比如find, in)可能可以完成,有些情况会稍稍复杂一些(比如说找出所有“像邮箱”的字符串,所有和meachine learning相关的句子),这个时候我们需要一个某种模式的工具,这个时候正则表达式就派上用场了。
正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串。正则也不是python 语言特有的,这一工具几乎所有语言都支持,那么一起来学习吧~
正则表达式入门
1. 介绍
对于没接触过正则的盆友,这里提供学习的网站 http://www.runoob.com/regexp/regexp-tutorial.html,并建议认真学习两个课时,本文的重点在后面,并不详细抄袭网上一大堆的正则的语法。
下面先给出一个简单的示例:
![]()
-
^ 为匹配输入字符串的开始位置。
-
[0-9]+匹配多个数字, [0-9] 匹配单个数字,+ 匹配一个或者多个。
-
abc$匹配字母 abc 并以 abc 结尾,$ 为匹配输入字符串的结束位置。
我们在写用户注册表单时,只允许用户名包含字符、数字、下划线和连接字符(-),并设置用户名的长度,我们就可以使用以下正则表达式来设定。
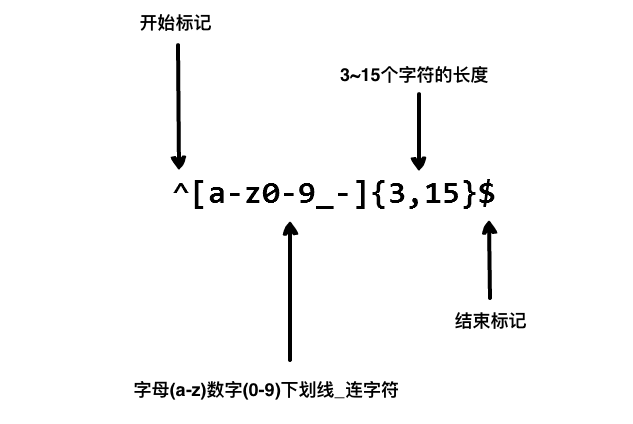
以上的正则表达式可以匹配 runoob、runoob1、run-oob、run_oob, 但不匹配 ru,因为它包含了小写的字母而且太短了,也不匹配 runoob$, 因为它包含特殊字符。
2. 语法
所谓正则的语法,主要是记住一大堆的符号,包括特殊字符、限定符、定位符,通过普通字符(数字、字母等)和其他符号的结合,表达出待匹配的字符模式。
注:不同语言的正则表达式语法似乎不尽相同,具体应用时还是要了解一下该语言的具体情况。
3. 验证工具
写正则遇到困难时不妨用下面的工具验证试验,十分好用。
https://c.runoob.com/front-end/854
4. re模块使用
其他语言的大致相同,本文略略介绍一下python中re模块的使用。
使用re的一般步骤是
- 1.将正则表达式的字符串形式编译为Pattern实例
- 2.使用Pattern实例处理文本并获得匹配结果(一个Match实例)
此处常用的函数方法包括:match, search, split,findall,finditer, sub, subn
- 3.使用Match实例获得信息,进行其他的操作。
此处常用match 实例的string属性获得匹配时使用的文本,或者group方法等获得一个或多个分组截获的字符串。
正则表达式进阶
学完上述知识,有了一些经验后,很容易认为正则的功能大致如此,实际上还有很多可学的东西,虽然很可能在工作上不常用。
窃以为,正则表达式的高级用法主要是1)捕获与分组 ,2)零宽断言(叫环视可能好理解)。
分组就是对正则表达式进行用“()”分割后命名,默认的分组命名方式是:整个正则表达式为分组0,从左到右分组为1、2、3以此类推。也可以自己进行命名,语法如下:
| 代码 | 描述 |
|---|---|
| (exp) | 匹配exp,并捕获文本到自动命名的组内 |
| (?<name>exp) | 匹配exp,并捕获文本到name的组里面,尖括号可以换成'' |
| (?:exp) | 匹配exp,不捕获匹配的文本,也不给此分组分配组号 |
零宽断言从概念理解到实际应用上都是难点,但是是个好用的东西,如果你不知道,一定会妨碍你写正则。
断言(https://www.jianshu.com/p/31d5854bde6f)就是判断当前位置的前后是否匹配,但是不消耗任何字符(零宽),普通的断言,比如\d+(匹配一个或者多个数字),它所匹配的内容是由长度的。
| 代码 | 描述 |
|---|---|
| (?=exp) | 正预测先行断言,断言自身出现的位置的后面可以匹配后面跟的表达式 |
| (?<=exp) | 正回顾后发断言,它断言自身出现的位置的前面可以匹配后面跟的表达式 |
| (?!exp) | 负预测先行断言,它断言自身出现的位置的后面不可以匹配后面跟的表达式 |
| (?<!exp) | 负回顾后发断言,它断言自身出现的位置的后面不可以匹配后面跟的表达式 |
此处学习建议学习其他博客中的用例,理解其含义,再进行一定的练习。
其他高级用法:
参考其他大神的博客学习即可:深入理解正则表达式高级教程 python3正则表达式的几个高级用法
啰嗦一句,注意贪婪、非贪婪的使用,注意匹配的优先级等问题
正则表达式练习
请戳正则表达式进阶练习,可以自己练习一下,争取写出最短的正则表达式完成匹配任务,建议只练习前9道题即可=。=,第十题可以瞅一下就知道为什么后面不用练了。
下面挑几道题看一下
Anchors
Match all of these…✔Mick ✔Rick ✔allocochick ✔backtrick ✔bestick ✔candlestick ✔counterprick ✔heartsick ✔lampwick ✔lick ✔lungsick ✔potstick ✔quick ✔rampick ✔rebrick ✔relick ✔seasick ✔slick ✔tick ✔unsick ✔upstick |
and none of these…✕Kickapoo ✕Nickneven ✕Rickettsiales ✕billsticker ✕borickite ✕chickell ✕fickleness ✕finickily ✕kilbrickenite ✕lickpenny ✕mispickel ✕quickfoot ✕quickhatch ✕ricksha ✕rollicking ✕slapsticky ✕snickdrawing ✕sunstricken ✕tricklingly ✕unlicked ✕unnickeled |
答案是 k$,以k结尾的单词
It never ends – $ not allowed
Match all of these…✔fu ✔tofu ✔snafu |
and none of these…✕futz ✕fusillade ✕functional ✕discombobulated |
答案是u\b, 本质上还是b结尾的单词,只是不可用$
Backrefs – This doesn't really work as a tutorial. Not really clear what you're supposed to do here
Match all of these…✔allochirally ✔anticovenanting ✔barbary ✔calelectrical ✔entablement ✔ethanethiol ✔froufrou ✔furfuryl ✔galagala ✔heavyheaded ✔linguatuline ✔mathematic ✔monoammonium ✔perpera ✔photophonic ✔purpuraceous ✔salpingonasal ✔testes ✔trisectrix ✔undergrounder ✔untaunted |
and none of these…✕anticker ✕corundum ✕crabcatcher ✕damnably ✕foxtailed ✕galvanotactic ✕gummage ✕gurniad ✕hypergoddess ✕kashga ✕nonimitative ✕parsonage ✕pouchlike ✕presumptuously ✕pylar ✕rachioparalysis ✕scherzando ✕swayed ✕unbridledness ✕unupbraidingly ✕wellside |
答案是(...).*\1 ,捕获分组
Abba – Let's pretend this one is not a rehash of the last one.
Match all of these…✔acritan ✔aesthophysiology ✔amphimictical ✔baruria ✔calomorphic ✔disarmature ✔effusive ✔fluted ✔fusoid ✔goblinize ✔nihilistic ✔noisefully ✔picrorhiza ✔postarytenoid ✔revolutionize ✔suprasphanoidal ✔suspenseful ✔tapachula ✔transmit ✔unversatile ✔vibetoite |
and none of these…✕abba ✕anallagmatic ✕bassarisk ✕chorioallantois ✕coccomyces ✕commotive ✕engrammatic ✕glossoscopia ✕hexacoralla ✕hippogriffin ✕inflammableness ✕otto ✕overattached ✕saffarid ✕sarraceniaceae ✕scillipicrin ✕tlapallan ✕trillion ✕unclassably ✕unfitting ✕unsmelled ✕warrandice |
答案是^(?!.*(.)(.)\2\1), 更为复杂的分组,还用^表式不匹配
A man, a plan
Match all of these…✔civic ✔deedeed ✔degged ✔hallah ✔kakkak ✔kook ✔level ✔murdrum ✔noon ✔redder ✔repaper ✔retter ✔reviver ✔rotator ✔sexes ✔sooloos ✔tebbet ✔tenet ✔terret |
and none of these…✕arrogatingly ✕camshach ✕cinnabar ✕defendress ✕derivedly ✕gourmet ✕hamleteer ✕hydroaviation ✕lophine ✕nonalcohol ✕outslink ✕pretest ✕psalterium ✕psorosperm ✕scrummage ✕sporous ✕springer ✕sunburn ✕teleoptile ✕unstuttering ✕womanways |
答案是 (.)(.).?\2\1.?$,结合上题一起理解,当然这不是最优答案,最优是^(.)[^p].*\1$, 我觉得没必要搞这种东西==
Prime
Match all of these…✔xx ✔xxx ✔xxxxx ✔xxxxxxx ✔xxxxxxxxxxx ✔xxxxxxxxxxxxx ✔xx…(17)…xx ✔xx…(19)…xx ✔xx…(23)…xx ✔xx…(29)…xx ✔xx…(31)…xx ✔xx…(37)…xx ✔xx…(41)…xx ✔xx…(43)…xx ✔xx…(47)…xx ✔xx…(53)…xx ✔xx…(59)…xx ✔xx…(61)…xx ✔xx…(67)…xx ✔xx…(71)…xx |
and none of these…✕xxxx ✕xxxxxx ✕xxxxxxxx ✕xxxxxxxxx ✕xxxxxxxxxx ✕xxxxxxxxxxxx ✕xxxxxxxxxxxxxx ✕xxxxxxxxxxxxxxx ✕xxxxxxxxxxxxxxxx ✕xx…(18)…xx ✕xx…(20)…xx ✕xx…(21)…xx ✕xx…(22)…xx ✕xx…(24)…xx ✕xx…(25)…xx ✕xx…(26)…xx ✕xx…(27)…xx ✕xx…(28)…xx ✕xx…(30)…xx ✕xx…(32)…xx |
答案是 ^(?!(xx+)\1+$), 正则还能匹配素数?还真行!结合了分组,贪婪,及断言等思想,比较难。大牛的答案是^(?!(..+)\1+$),自行去理解吧。。
Four
Match all of these…✔Makaraka ✔Wasagara ✔degenerescence ✔desilicification ✔elevener ✔hipponosological ✔homoeomorphy ✔homologous ✔ileocolotomy ✔intervisibility ✔jararaca ✔locomotory ✔micropoikilitic ✔odontonosology ✔parhomologous ✔pogonotomy ✔promonopolist ✔protohomo ✔pseudoprimitivism ✔tocororo ✔unintelligibility |
and none of these…✕Ludgate ✕Mitsukurinidae ✕Ternstroemiaceae ✕arrhythmical ✕bleater ✕energetics ✕inthrow ✕mecopterous ✕multum ✕naphthalene ✕nullibicity ✕observancy ✕overpunishment ✕overregularly ✕overwilily ✕participator ✕predisable ✕reyield ✕rubeola ✕traitorlike ✕unregainable |
答案是 (.)(.\1){3}, 难度还好。
Powers
Match all of these…✔x ✔xx ✔xxxx ✔xxxxxxxx ✔xxxxxxxxxxxxxxxx ✔xx…(32)…xx ✔xx…(64)…xx ✔xx…(128)…xx ✔xx…(256)…xx ✔xx…(512)…xx ✔xx…(1024)…xx |
and none of these…✕xxx ✕xxxxx ✕xxxxxxx ✕xxxxxxxxxxx ✕xxxxxxxxxxxxx ✕xx…(28)…xx ✕xx…(48)…xx ✕xx…(160)…xx ✕xx…(401)…xx ✕xx…(600)…xx ✕xx…(1025)…xx |
匹配幂?在素数的基础上更难了,答案是 ^(?!(.(..)+)\1*$), 学习一下大牛的解法,还是通过断言解决的。
常用正则表达式
业务上常用正则匹配手机号,邮箱等,我们把这些常用的拿出来,省的自己写了。
https://c.runoob.com/front-end/854 刚才的验证网站下有一些常用正则表达式,还可以参考Unicode中文和特殊字符的编码范围 ,下面列出了常用正则:
匹配中文字符的正则表达式: [\u4e00-\u9fa5]
匹配双字节字符(包括汉字在内):[^\x00-\xff])
匹配空白行的正则表达式:\n\s*\r
匹配HTML标记的正则表达式:<(\S*?)[^>]*>.*?</>|<.*? />
匹配首尾空白字符的正则表达式:^\s*|\s*$
匹配Email地址的正则表达式:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*
帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
密码(以字母开头,长度在6~18之间,只能包含字母、数字和下划线):^[a-zA-Z]\w{5,17}$
InternetURL:[a-zA-z]+://[^\s]* 或 ^http://([\w-]+\.)+[\w-]+(/[\w-./?%&=]*)?$
手机号码:^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\d{8}$
电话号码("XXX-XXXXXXX"、"XXXX-XXXXXXXX"、"XXX-XXXXXXX"、"XXX-XXXXXXXX"、"XXXXXXX"和"XXXXXXXX):^(\(\d{3,4}-)|\d{3.4}-)?\d{7,8}$
国内电话号码(0511-4405222、021-87888822):\d{3}-\d{8}|\d{4}-\d{7}
身份证号(15位、18位数字),最后一位是校验位,可能为数字或字符X:(^\d{15}$)|(^\d{18}$)|(^\d{17}(\d|X|x)$)
腾讯QQ号:[1-9][0-9]{4,} (腾讯QQ号从10000开始)
中国邮政编码:[1-9]\d{5}(?!\d) (中国邮政编码为6位数字)
IP地址:((?:(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d)\\.){3}(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d))
匹配特定数字:
^[1-9]\d*$ //匹配正整数
^-[1-9]\d*$ //匹配负整数
^-?[1-9]\d*$ //匹配整数
^[1-9]\d*|0$ //匹配非负整数(正整数 + 0)
^-[1-9]\d*|0$ //匹配非正整数(负整数 + 0)
^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$ //匹配正浮点数
^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$ //匹配负浮点数
^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$ //匹配浮点数
^[1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0$ //匹配非负浮点数(正浮点数 + 0)
^(-([1-9]\d*\.\d*|0\.\d*[1-9]\d*))|0?\.0+|0$ //匹配非正浮点数(负浮点数 + 0)
匹配特定字符串:
^[A-Za-z]+$ //匹配由26个英文字母组成的字符串
^[A-Z]+$ //匹配由26个英文字母的大写组成的字符串
^[a-z]+$ //匹配由26个英文字母的小写组成的字符串
^[A-Za-z0-9]+$ //匹配由数字和26个英文字母组成的字符串
^\w+$ //匹配由数字、26个英文字母或者下划线组成的字符串
正则的知识体系大概就是这样了,不熟悉的部分还是要在此基础上学习,本文只是列出而已。