本文介绍GMM算法,也就是高斯混合模型,或则更准确的说,应该称为高斯线性混合模型。
##高斯分布
又称为正太分布,常态分布,是自然界大量存在的、最为常见的分布。例如人类和动物的身高,体重,测量误差等等。正太分布的概率密度函数如下:
f(x)=2σ2π
1e−2σ2(x−μ)2
均值
μ和方差
σ2是正太分布的两个参数。实际中经常遇到的问题是我们知道某个变量是符合正太分布的,需要通过采样的数据估计参数取值。经常使用的方法是MLE最大似然估计。上一章中有介绍这方面的例子。
##高斯混合模型
如何一个变量的取值是多个高斯分布联合产生的,如何进行参数估计呢? 如果对于多个高斯分布联合产生的数据,使用单个高斯分布去拟合的话,可以想象拟合的结果不会很好。
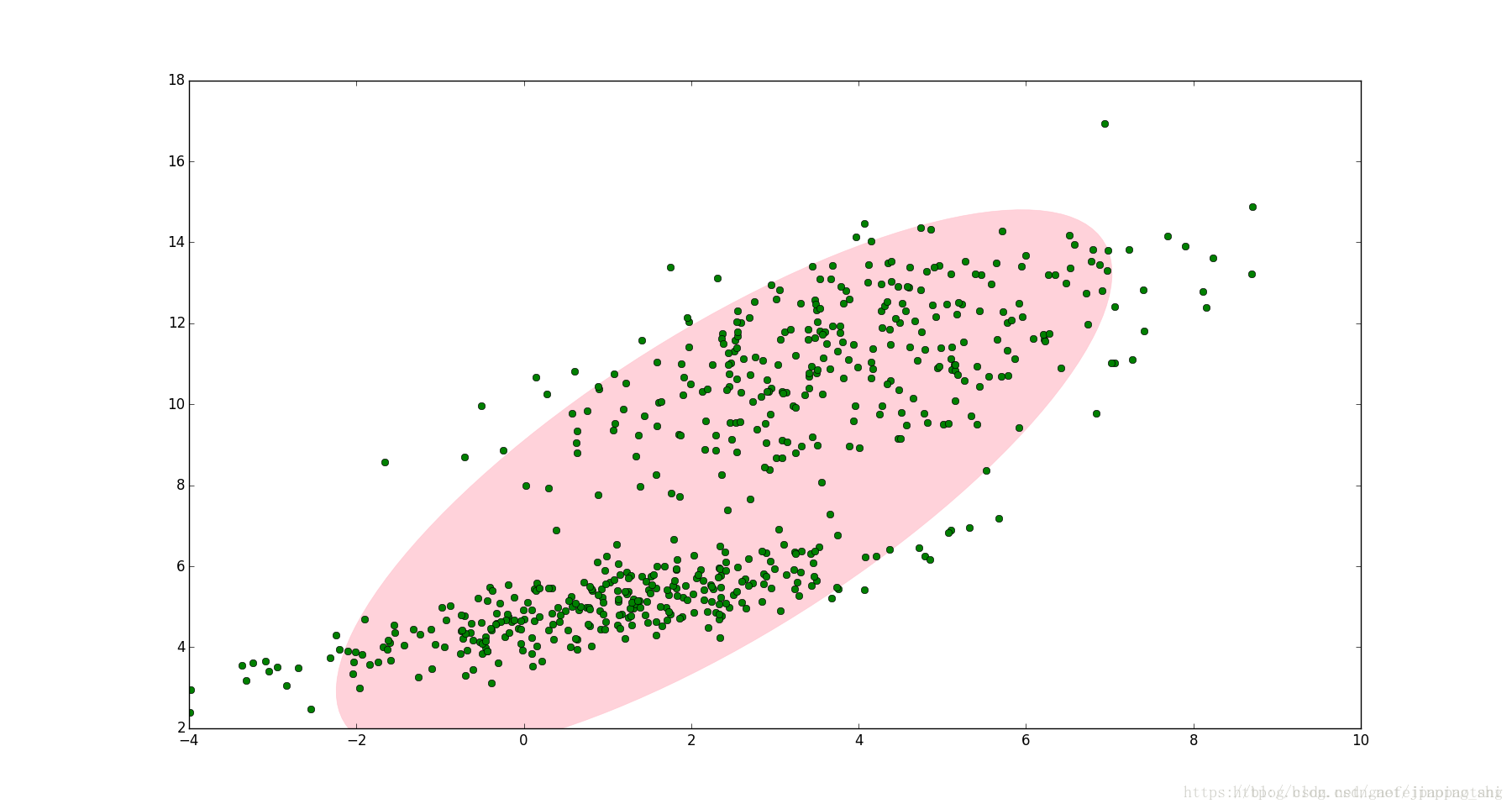
更好的拟合应该是使用多个高斯分布拟合。
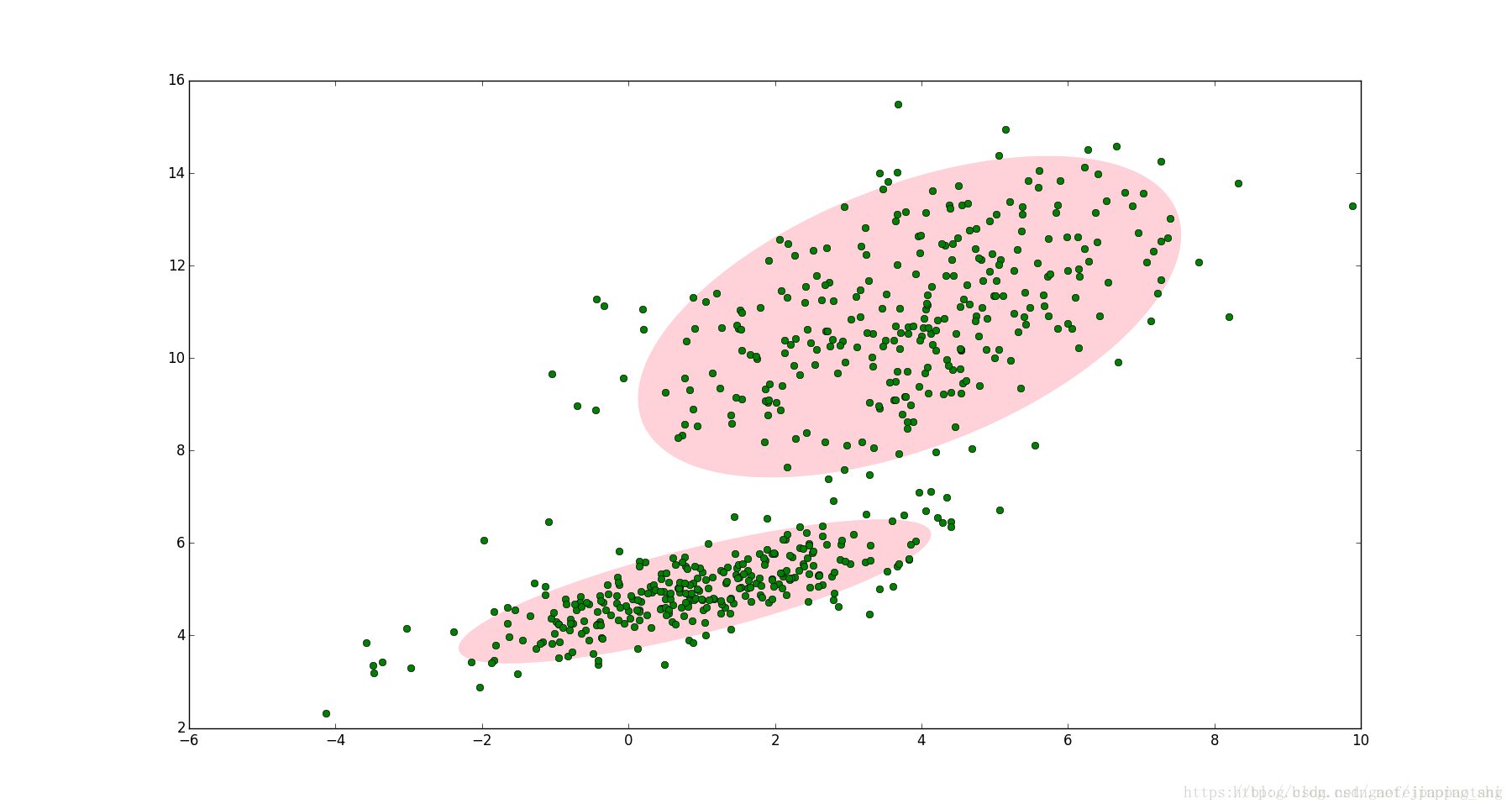
GMM模型就是对由多个高斯分布线性拟合后产生的数据进行参数估计的模型。模型的概率密度函数为:
f(x)=i∑kϕi2σi2π
1e−2σi2(x−μi)2
可以看出,GMM模型的可以通过上一章中的EM算法估计参数值
ϕi,μi,σi2,i∈[1,k].
##GMM聚类
可以依据观察值来自的具体高斯分布将其进行聚类,其实就是对于每个观察值求解
P(T=i∣x),i∈[1,k].求解方式如下:
P(T=i∣x)=P(x)P(T=i)P(x∣T=i)
f(x)ΔxϕiN(x∣μi,σi2)Δx
∑jkϕjN(x∣μj,σj2)ϕiN(x∣μi,σi2)