版权声明:wang https://blog.csdn.net/m0_37846020/article/details/83859619
作者课堂笔记,有问题请联系[email protected]
目录
1 指数族
如果一种分布可以写成如下形式,那么这种分布属于指数族:
p(y;η)=b(y)eηTT(y)−a(η)
-
η:分布的自然参数
-
T(y):充分统计量
-
a(η):log的分隔函数(
a(η)作为归一化常量,目的是让
∑yp(y;η)=1)
1.1 伯努利分布
分布形式:
p(y;ϕ)=ϕy(1−ϕ)1−y
-
η=log(1−ϕϕ)
-
b(y)=1
-
T(y)=y
-
a(η)=log(1+eη)
1.2 高斯分布
y∼χ(μ,1)
p(y;θ)=2π
1e−2(y−μ)2
-
η=μ
-
b(y)=2π
1e2y2
-
T(y)=y
-
a(η)=21η2
y∼χ(μ,σ2)
p(y;θ)=2πσ2
1e−2σ2(y−μ)2
-
η=[σ2μ−2σ21]
-
b(y)=2π
1
-
T(y)=[yy2]
-
a(η)=2σ2μ+logσ
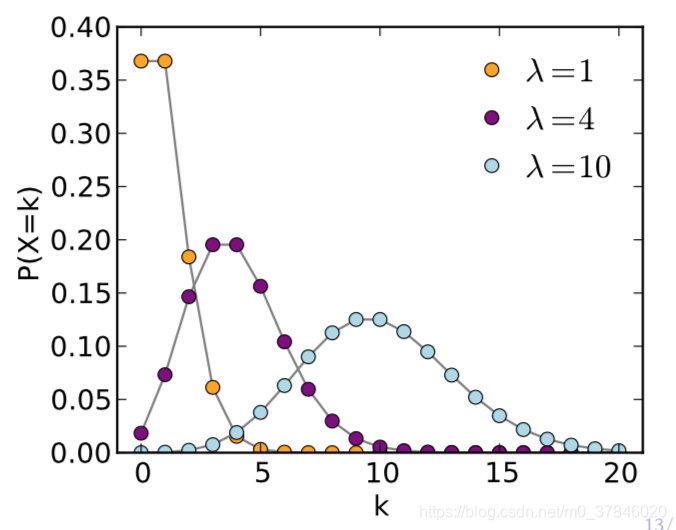
1.3 柏松分布
p(y;λ)=y!λye−λ
-
η=log(λ)
-
b(y)=y!1
-
T(y)=y
-
a(η)=eη
2 广义线性模型
通过改变y的分布,从而更好的拟合数据。是一种构造线性模型的方法,其中Y|X来自于指数族。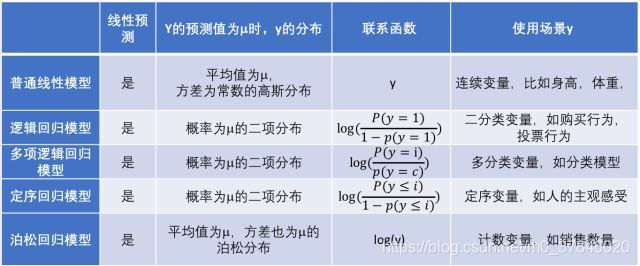
来源https://www.sohu.com/a/228212348_349736
广义线性模型的设计初衷:
- 为了使响应变量y可以有任意的分布。
- 允许任意的函数(链接函数)可以随着输入的x变化。
构建方法:
- y|x;
θ∼指数族分布(高斯、柏松、伯努利…)
- 我们的目标是给定x,预测T(y)的期望,大多数情况是T(y)=y,而在其他情况下可能是E[y|x;
θ]
- 自然参数
η和x是线性相关的,满足
η=θTx
如果问题满足以上的三个假设,那么我们那就可以构造广义线性模型来解决问题。
2.1 最小二乘法
应用GLM的构造准则:
- y|x;
θ∼N(μ,1)
η=μ,T(y)=y
- 推导假设函数:
hθ(x)=E[y∣x;θ]=μ=η
- 应用线性模型
η=θTx
hθ(x)=η=θTx
典范响应函数:
μ=g(η)=η
典范链接函数:
η=g−1(μ)=μ
2.2 Logistic回归
应用GLM的构造准则:
- y|x;
θ∼Bernoulli(ϕ)
η=log(1−ϕϕ),T(y)=y
- 推导假设函数:
hθ(x)=E[y∣x;θ]=ϕ=1+e−η1
- 应用线性模型
η=θTx
hθ(x)=1+e−θTx1
典范响应函数:
ϕ=g(η)=sigmoid(η)
典范链接函数:
η=g−1(ϕ)=logit(ϕ)
2.3 柏松回归(顾客预测)
应用GLM的构造准则:
- y|x;
θ∼Poisson(λ)
η=log(λ),T(y)=y
- 推导假设函数:
hθ(x)=E[y∣x;θ]=λ=eη
- 应用线性模型
η=θTx
hθ(x)=eθTx
典范响应函数:
λ=g(η)=eη
典范链接函数:
η=g−1(λ)=log(λ)
2.4 SoftMax回归
p(y;ϕ)=i=1∏kϕi1{y=i}
ϕk=1−∑i=1k−1ϕi
- T(y)=
⎣⎡1{y=1}...1{y=k−1}⎦⎤
-
η=⎣⎢⎡log(ϕkϕ1)...log(ϕkϕk−1)⎦⎥⎤
- b(y)=1
- a(
η)=
−log(ϕk)
应用GLM的构造准则:
- y|x;
θ∼Multinomial(ϕ1,....ϕk)
ηi=log(ϕkϕi),T(y)=⎣⎡1{y=1}...1{y=k−1}⎦⎤
ϕi=∑j=1keηjeηi
- 推导假设函数:
hθ(x)=E[T(y);θ]=⎣⎡ϕ1...ϕk−1⎦⎤....=ϕi=∑j=1keηjeηi
- 应用线性模型
η=θiTx
hθ(x)=∑j=1keηj1⎣⎡eθ1Tx...eθk−1Tx⎦⎤
典范响应函数:
ϕi=g(η)=∑j=1keηjeηi
典范链接函数:
η=g−1(ϕi)=log(ϕkϕi)
3 总结广义线性模型

4 练习
答案地址:https://pan.baidu.com/s/1ytOYfFKUDKVJI7Yg-07KoA


