| #!/usr/bin/python
# -*- coding: UTF-8 -*-
import urllib,re,requests
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
url_name = [] #url name
def get():
#获取源码
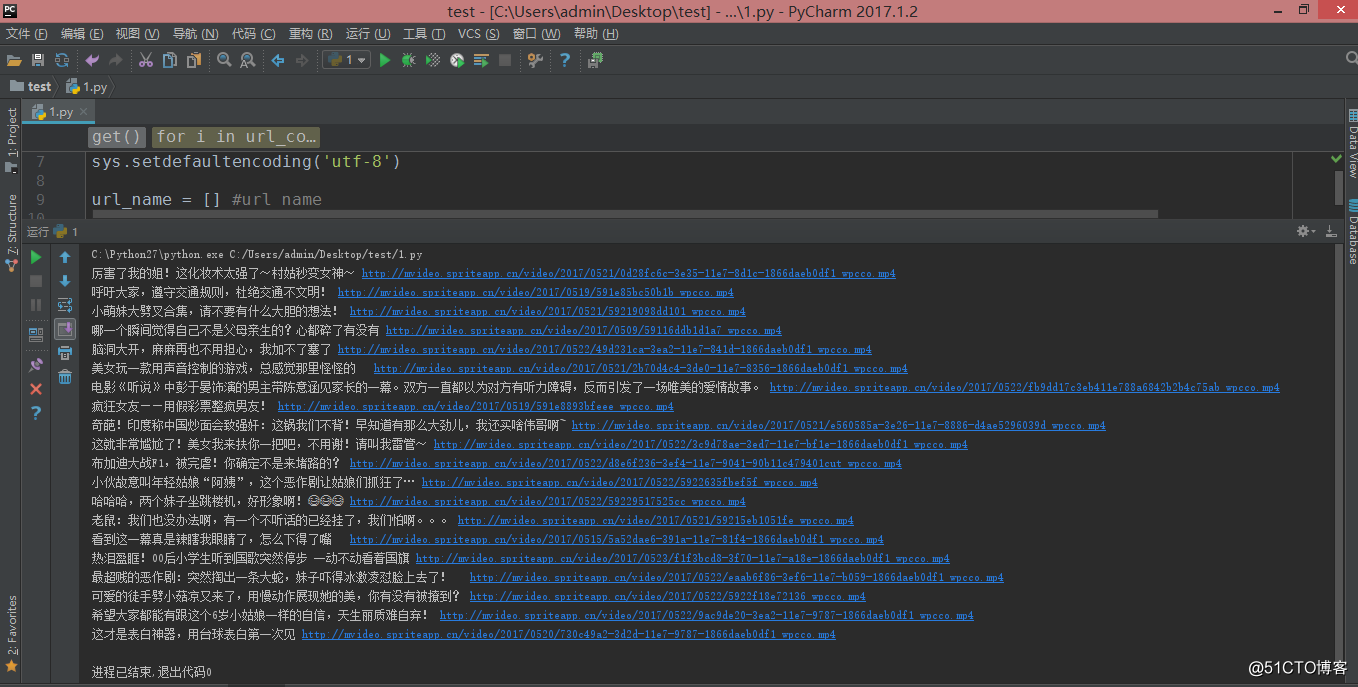
hd = {"User-Agent":"Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"}
url = 'http://www.budejie.com/video/'
html = requests.get(url,headers=hd).text
url_content = re.compile(r'(<div class="j-r-list-c">.*?</div>.*?</div>)',re.S) #编译
url_contents = re.findall(url_content,html) #匹配
for i in url_contents:
#匹配视频
url_reg = r'data-mp4="(.*?)"' #视频地址
url_items = re.findall(url_reg,i)
#print url_items
if url_items: #判断视频是否存在
name_reg = re.compile(r'<a href="/detail-.{8}?.html">(.*?)</a>',re.S)
name_items = re.findall(name_reg,i)
#print name_items[0]
for i,k in zip(name_items,url_items):
url_name.append([i,k])
print i,k
for i in url_name: #i[1]=url i[0]=name
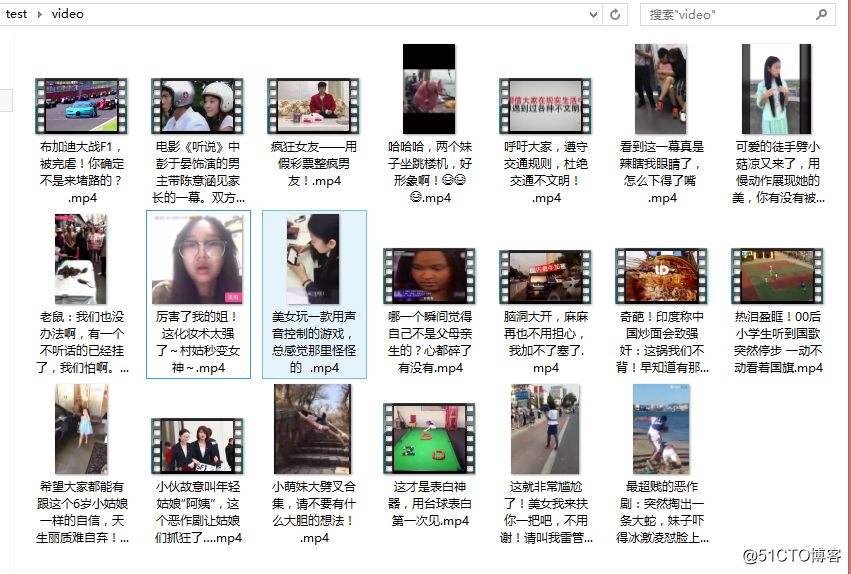
urllib.urlretrieve(i[1],'video\\%s.mp4' % (i[0].decode('utf-8')))
if __name__ == "__main__":
get()
|