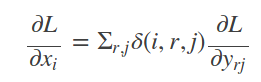1、介绍
R-CNN提供了非常准确的目标检测,但是它也有弊端:1、训练是多阶段的:用log loss先在目标提议上微调卷积网络,然后,用SVM做目标检测器,最后学习边界框回归。2、训练在空间时间上成本高:对于SVM和边界框回归训练,特征从每个图片的每个目标提议上提取并写入磁盘,很深的网络产生特征需要非常大的存储。3、目标检测慢:测试阶段,特征从每个测试图片的每个目标提议上提取,耗时长。
SPPnet(空间金字塔池化网络)提出通过共享计算来加速R-CNN。SPPNET方法计算整个输入图像的卷积特征映射,然后使用从共享特征映射中提取的特征向量对每个目标提议进行分类。通过最大池化将提议中的特征图部分提取出来,并用固定尺寸输出(如6×6)。多个输出大小被合并,然后像空间金字塔池那样连接起来。SPPNET在测试时将R-CNN加速10到100倍。由于更快的提案特征提取,培训时间也减少了3倍。但它仍然存在R-CNN相似的问题。它的训练要经过多个阶段,特征也要存在磁盘中,另外,SPP中的微调只更新SPP层后面的全连接层,对很深的网络这样肯定是不行的。
补充:1、SPPnet的介绍https://blog.csdn.net/qq_31050167/article/details/78927962
2、SPP-Net在fine-tuning阶段之所以无法使用反向传播微调SPP-Net前面的Covs层,是因为特征提取CNN的训练和SVMs分类器的训练在时间上是先后顺序,两者的训练方式独立,因此SVMs的训练Loss无法更新SPP-Layer之前的卷积层参数,因此即使采用更深的CNN网络进行特征提取,也无法保证SVMs分类器的准确率一定能够提升。另外在Fast-RCNN中,由于去掉了SVM分类这一过程,所有特征都存储在显存中,不占用硬盘空间,形成了End-to-End模型。当然proposal除外,end-to-end在Faster-RCNN中得以完善);Fast-RCNN还通过single scale(pooling->spp just for one scale) testing和SVD(降维)分解全连接来减少test time。 原文:https://blog.csdn.net/whfshuaisi/article/details/62237765
fast R-CNN 有几点优势:1、比R-CNN 和SPPnet检测更快。2、训练是单阶段的,使用多任务损失函数。3、训练可以更新所有的网络层。4、特征缓存不需要硬盘存储。
2、Fast R-CNN架构及训练
网络首先使用多个卷积(conv)和最大池层处理整个图像,以生成卷积特征图。然后,对于每个目标提议,感兴趣的区域(ROI)池化层从特征图中提取一个固定长度的特征向量。每个特征向量被送入一系列全连接(fc)层中,最终分支到两个输出层,一个用来分类,一个用来输出四个值优化边界框位置。

2.1 RoI 池化层
ROI池化层使用最大池化将任何有效感兴趣区域内的特征转换为固定空间大小为H×W的特征图。ROI最大池的工作原理是将h×w ROI窗口划分为一个H×W的子网格窗口,其大小约为h/H x w/W,然后将每个子窗口中的值最大池化到相应的输出网格单元中。池化独立应用于每个特征图通道,与标准最大池化相同。
2.2 从预训练网络初始化
首先,最后一个最大池层被一个ROI池化层替换,将H和W设置为与网络的第一个全连接层兼容的值。其次,将网络的最后一个全连接层和SoftMax(经过1000类ImageNet分类训练)替换为之前所描述的两个同级层(K+1类别和特定于类别的边界框回归)。第三,网络被修改为接受两个数据输入:一个图像列表和这些图像中的ROI列表。
2.3 检测微调
多任务损失函数:第一部分是一个离散的概率分布,有K类,最后softmax输出K+1个输出(加背景类)。第二个兄弟层输出回归偏移量![]() ,tk指定相对于对象提议的比例不变转换和log空间高度/宽度偏移,与R-CNN使用的方法一样,下面有补充。
,tk指定相对于对象提议的比例不变转换和log空间高度/宽度偏移,与R-CNN使用的方法一样,下面有补充。
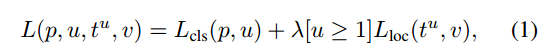
![]()
![]() 是一个元组, u是指示器,当u≥1时[u≥1]计算为1,否则为0。当框中都是背景时,u为0
是一个元组, u是指示器,当u≥1时[u≥1]计算为1,否则为0。当框中都是背景时,u为0
对于背景ROI,没有真实边界框的概念,因此忽略Lloc。对于边界框回归,我们使用损失函数:

λ控制两个损失函数之间的平衡
补充:R-CNN边界框回归方法
![]() 表示目标提议pi的像素中心坐标及宽高,
表示目标提议pi的像素中心坐标及宽高,![]() 是ground truth的像素中心坐标及宽高,目标是学习一个将目标提议的方框P映射到一个ground truth方框G的转换。
是ground truth的像素中心坐标及宽高,目标是学习一个将目标提议的方框P映射到一个ground truth方框G的转换。
用四个函数来参数化转换。![]() ,前两个指定P边界框中心的比例不变转换,而后二个指定P边界框的宽度和高度的log space的转换。在学习了这些函数之后,我们可以将一个输入通过应用转换将P的边界框转换为预测的ground truth框
,前两个指定P边界框中心的比例不变转换,而后二个指定P边界框的宽度和高度的log space的转换。在学习了这些函数之后,我们可以将一个输入通过应用转换将P的边界框转换为预测的ground truth框![]()
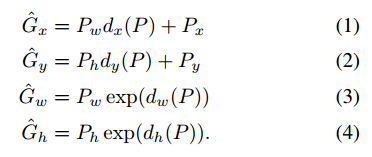
其中![]() 是线性函数,w是可学习参数,可以通过正则化的最小二乘来优化
是线性函数,w是可学习参数,可以通过正则化的最小二乘来优化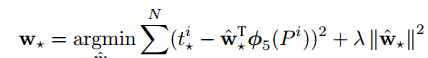 ,
,
小批量采样
每个mini-batch选N=2张图像,每张图像有64个RoI,25%与ground truth有>0.5的IoU。
通过RoI池化层进行反向传播
对每个x求偏导:
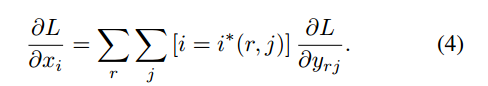
补充:首先考虑普通max pooling层。设xi为输入层的节点,yj为输出层的节点。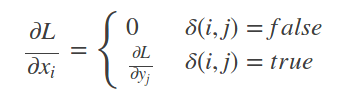
其中判决函数δ(i,j)表示i节点是否被j节点选为最大值输出。不被选中有两种可能:xi不在yj范围内,或者xi不是最大值。
对于roi max pooling,一个输入节点可能和多个输出节点相连。设xi为输入层的节点,yrj为第r个候选区域的第j个输出节点。判决函数δ(i,r,j)表示i节点是否被候选区域r的第j个节点选为最大值输出。代价对于xi的梯度等于所有相关的后一层梯度之和。