本文转载自XZZPPP的CSDN博客,
原始链接地址:https://blog.csdn.net/XZZPPP/article/details/51377771
1、简介
Fast R-CNN将整个图片送入网络时同时将object proposal(这里称为RoI,一张图片中得到约2k个)也送入网络,每一个RoI被Rol pooling layer(相当于一个单层的SPP layer)统一到一个固定大小的feature map,然后通过两个全连接层(FCs)将其映射到一个特征向量。这个特征分别share到两个新的全连接,连接上两个优化目标,第一个是softmax probabilities,优化目标是分类;第二个是bounding-box regression,优化目标是精确边框位置。
Fast R-CNN目标检测系统框图:
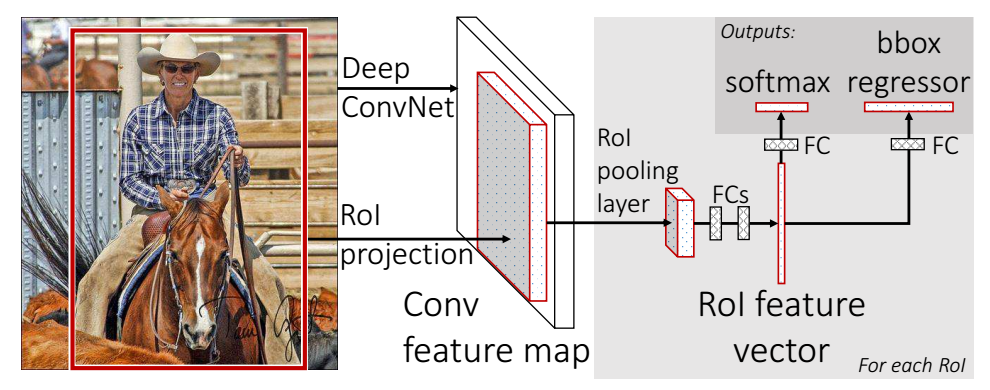
2、Fast R-CNN系统结构和训练
2.1 Rol pooling layer
Rol pooling layer的作用主要有两个,一个是将image中的rol定位到feature map中对应区域(patch),另一个是用一个单层的SPP layer将这个feature map patch下采样为大小固定的feature再传入全连接层。(具体实现过程可参考:spatial pyramid pooling (Spp)-net(空间金字塔池化)笔记)
2.2 Fine-tuning for detection
空间金字塔池卷积层(SPP)无法进行权值更新,Fast R-CNN使用单层SPP layer。利用随机梯度下降法小批量分层采样,同一张图片里面的ROI(region of interest)在前向传播和反向传播中,计算和存储共享,从而降低了计算,可以实现权值更新。
2.3 Multi-task loss
FRCN有两个loss,以下分别介绍。
对于分类loss,是一个N+1路的softmax输出,其中的N是类别个数,1是背景,使用softmax分类器。对于回归loss,是一个4xN路输出的bounding-box regressor(有4个元素(x,y,w,h),左上角坐标(x,y),宽w,高h),也就是说对于每个类别都会训练一个单独的regressor。
在每个标记的ROI中,用一个Multi-task损失函数L,共同训练分类和边框回归:
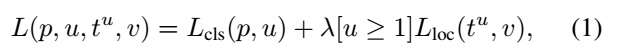
其中,p:ROI在softmax输出的离散概率分布;t:bbox regressor输出偏移值,v表示其真实值,tu表示其预测值;LCls(p,u)=-logpu;Lloc(tu,v)为边框回归损失函数:

这样设置的目的是想让loss对于离群点更加鲁棒,控制梯度的量级使得训练时不容易跑飞。
2.4 Truncated SVD for faster detection
Fast R-CNN利用了一种名为SVD的矩阵分解技术,其作用是将一个大的矩阵(近似)拆解为三个小的矩阵的乘积,使得拆解之后三个矩阵的元素数目远小于原来大矩阵的元素数目,从而达到在计算矩阵乘法时降低计算量的目的,通过将SVD应用于全连接层的权值矩阵,处理一张图片所需要的时间能够降低30%。
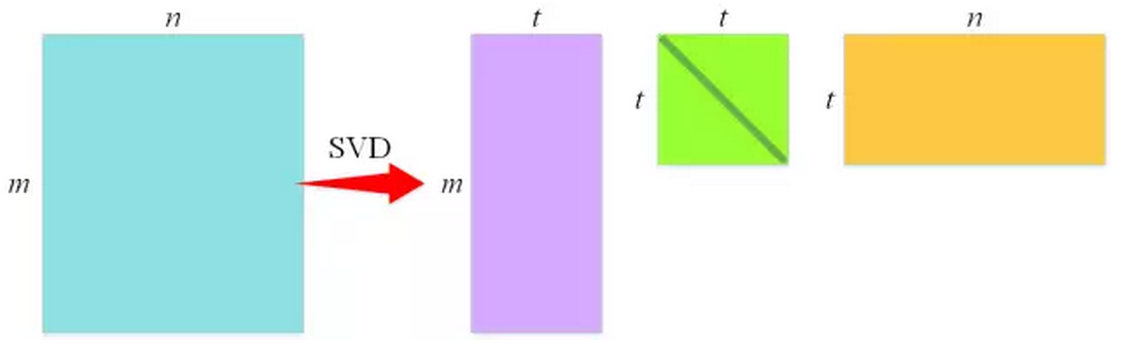
如上图,参数数量从m×n减少到t×(m+n),t远小于min(m,n)。