介绍:
Siamese网络是一种相似性度量方法,当类别数多,但每个类别的样本数量少的情况下可用于类别的识别、分类等。传统的用于区分的分类方法是需要确切的知道每个样本属于哪个类,需要针对每个样本有确切的标签。而且相对来说标签的数量是不会太多的。当类别数量过多,每个类别的样本数量又相对较少的情况下,这些方法就不那么适用了。其实也很好理解,对于整个数据集来说,我们的数据量是有的,但是对于每个类别来说,可以只有几个样本,那么用分类算法去做的话,由于每个类别的样本太少,我们根本训练不出什么好的结果,所以只能去找个新的方法来对这种数据集进行训练,从而提出了siamese网络。siamese网络从数据中去学习一个相似性度量,用这个学习出来的度量去比较和匹配新的未知类别的样本。这个方法能被应用于那些类别数多或者整个训练样本无法用于之前方法训练的分类问题。
原理:
主要思想是通过一个函数将输入映射到目标空间,在目标空间使用简单的距离(欧式距离等)进行对比相似度。在训练阶段去最小化来自相同类别的一对样本的损失函数值,最大化来自不同类别的一堆样本的损失函数值
给定一组映射函数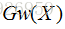
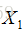
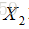
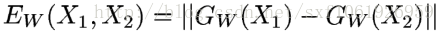
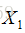
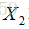
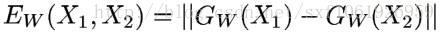
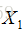
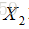
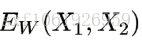
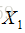
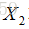
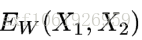
最终思想:
其实讲了这么多,主要思想就是三点:
1、输入不再是单个样本,而是一对样本,不再给单个的样本确切的标签,而且给定一对样本是否来自同一个类的标签,是就是0,不是就是1
2、设计了两个一模一样的网络,网络共享权值W,对输出进行了距离度量,可以说l1、l2等。
3、针对输入的样本对是否来自同一个类别设计了损失函数,损失函数形式有点类似交叉熵损失:
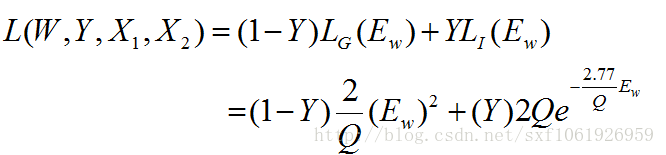
最后使用获得的损失函数,使用梯度反传去更新两个网络共享的权值W。