图是一种以网络形式相互连接的节点,图是一种与树有些相似的数据结构,图通常有一个固定的形状, 这是由物理或抽象的问题所决定的。图包含由边连接的顶点。
类型,无向图,有向图(边有方向,通常用箭头表示)
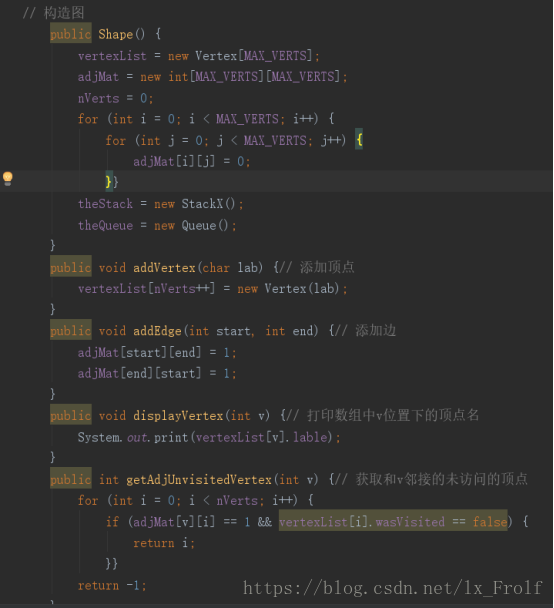
图可以用两种形式表示,邻接矩阵,邻接表,邻接矩阵或邻接表提供了关于当前顶点的位置信息,当前 顶点通过边与哪些顶点相连。
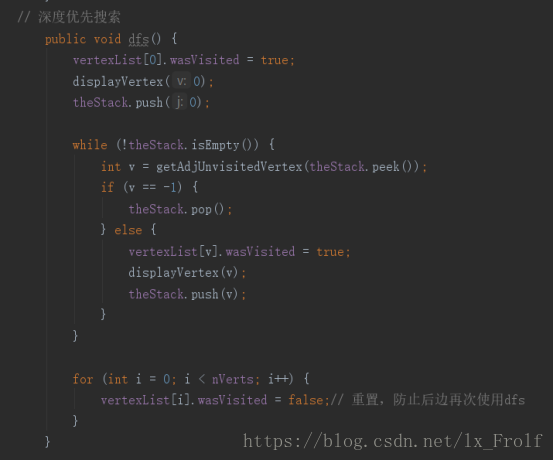
深度优先搜索 在搜索到尽头的时候,深度优先搜索使用栈标记下一步的走向。 栈的内容就是从起始顶点到各个顶点访问的整个过程,从起始顶点出发访问下一个顶点时,就把这个顶 点入栈,回到起始顶点时,出栈。深度优先算法要得到距离起始点远的顶点,然后在不能继续前进的 时候返回。
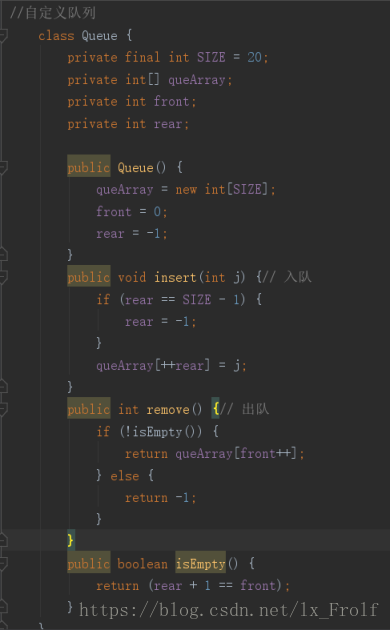
广度优先搜索 在广度优先搜索中,算法要尽可能的靠近起始点,它首先访问起始顶点的所有邻接点,然后在访问较远 的区域,用队列实现。
算法要点: 从一个顶点开始,把它放入树的集合中,然后重复做下面的事情:
1.找到从新的顶点到其他顶点的所有边,这些顶点不能在树的集合中。把这些边放入优先级队列。
2.找出权值小的边,把它和它所到达的顶点放入树的集合中。 重复,直到所有顶点都在树的集合中。
效率 如果使用邻接矩阵,各种算法大约需要O(VV)时间级,V是顶点的数量。因为这些算法几乎都遍历了一遍 所有顶点,具体方法是在邻接矩阵中扫描每一行,依次查看每条边。即邻接矩阵的每个单元,一共有VV 个单元都被扫描过。对于规模大的矩阵O(V*V)时间级的性能并不好。如果图是密集的,性能就很难提高。 然而对于稀疏的图来说,使用邻接表的方法代替邻接矩阵,可以提高性能,因为这样不用浪费时间来检 索邻接矩阵中没有边的单元。
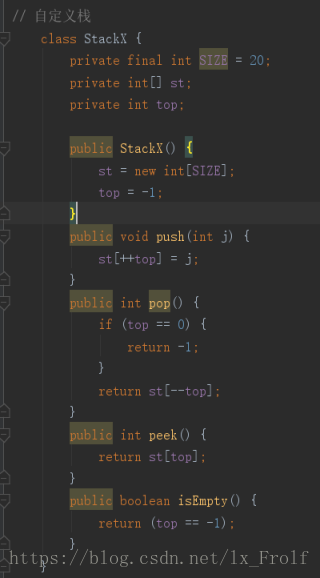
实战
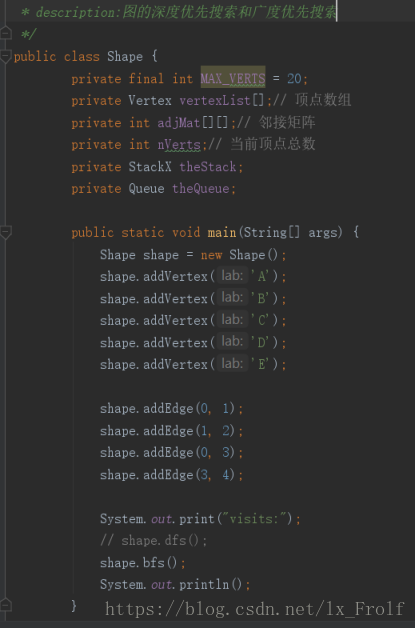
实现广度和深度优先搜索 :