一、模糊系统
模糊控制系统分类
1 按信号的时变特性分类
(1)恒值模糊控制系统
系统的指令信号为恒定值,通过模糊控制器消除外界对系统的扰动作用,使系统的输出跟踪输入的恒定值。也称为“自镇定模糊控制系统”,如温度模糊控制系统。
(2)随动模糊控制系统
系统的指令信号为时间函数,要求系统的输出高精度、快速地跟踪系统输入。也称为“模糊控制跟踪系统”或“模糊控制伺服系统”。


3 按静态误差是否存分类
(1)有差模糊控制系统
将偏差的大小及其偏差变化率作为系统的输入为有差模糊控制系统。
(2)无差模糊控制系统
引入积分作用,使系统的静差降至最小。
4 按系统控制输入变量的多少分类
控制输入个数为1的系统为单变量模糊控制系统,控制输入个数>1的系统为多变量模糊控制系统。
二、模糊控制器
在确定性控制系统中,根据控制器输出的个数,可分为单变量控制系统和多变量控制系统。在模糊控制系统中也可类似地划分为单变量模糊控制和多变量模糊控制。
1、单变量模糊控制器
在单变量模糊控制器(Single Variable Fuzzy Controller—SVFC)中,将其输入变量的个数定义为模糊控制的维数。
(1)一维模糊控制器 如图4-5(a)所示,一维模糊控制器的输入变量往往选择为受控量和输入给定的偏差量E。由于仅仅采用偏差值,很难反映过程的动态特性品质,因此,所能获得的系统动态性能是不能令人满意的。这种一维模糊控制器往往被用于一阶被控对象。

(2)二维模糊控制器 如图4-5(b)所示,二维模糊控制器的两个输入变量基本上都选用受控变量和输入给定的偏差E和偏差变化EC,由于它们能够较严格地反映受控过程中输出变量的动态特性,因此,在控制效果上要比一维控制器好得多,也是目前采用较广泛的一类模糊控制器。

(3)三维模糊控制器 如图4-5(c)所示,三维模糊控制器的三个输入变量分别为系统偏差量E、偏差变化量EC和偏差变化的变化率ECC。由于这些模糊控制器结构较复杂,推理运算时间长,因此除非对动态特性的要求特别高的场合,一般较少选用三维模糊控制器。
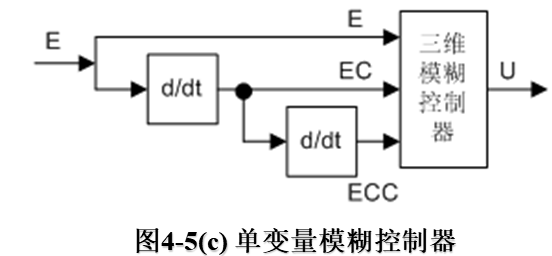
模糊控制系统所选用的模糊控制器维数越高,系统的控制精度也就越高。但是维数选择太高,模糊控制规律就过于复杂,这是人们在设计模糊控制系统时,多数采用二维控制器的原因。
2、多变量模糊控制器
一个多变量模糊控制器(Multiple Variable Fuzzy Controller)系统所采用的模糊控制器,具有多变量结构,称之为多变量模糊控制器。如图4-6所示。
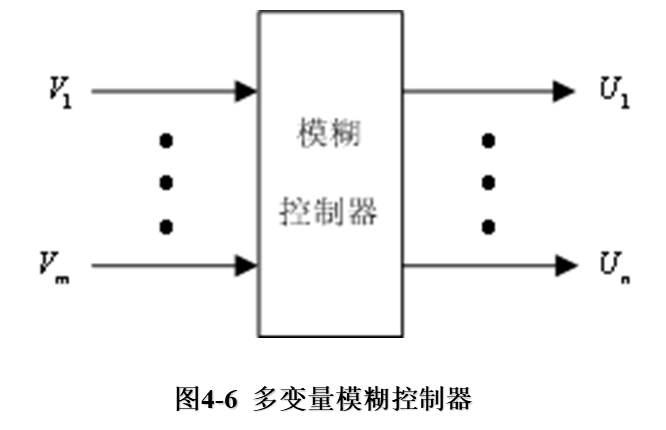
要直接设计一个多变量模糊控制器是相当困难的,可利用模糊控制器本身的解耦特点,通过模糊关系方程求解,在控制器结构上实现解耦,即将一个多输入-多输出(MIMO)的模糊控制器,分解成若干个多输入-单输出(MISO)的模糊控制器,这样可采用单变量模糊控制器方法设计。
三、模糊控制器的设计
模糊控制器的设计步骤
模糊控制器最简单的实现方法是将一系列模糊控制规则离线转化为一个查询表(又称为控制表)。这种模糊控制其结构简单,使用方便,是最基本的一种形式。
1、模糊控制器的结构
单变量二维模糊控制器是最常见的结构形式。
2、定义输入输出模糊集
对误差E、误差变化EC及控制量u的模糊集及其论域定义如下:
E、EC和u的模糊集均为:{NB,NM,NS,ZO,PS,PM,PB}
E、EC的论域均为:{-3,-2,-1,0,1,2,3}
u的论域为:{-4.5,-3,-1.5,0,1,3,4.5}
3、 定义输入输出隶属函数
模糊变量误差E、误差变化EC及控制量u的模糊集和论域确定后,需对模糊语言变量确定隶属函数,确定论域内元素对模糊语言变量的隶属度。
4 、建立模糊控制规则
根据人的经验,根据系统输出的误差及误差的变化趋势来设计模糊控制规则。模糊控制规则语句构成了描述众多被控过程的模糊模型。
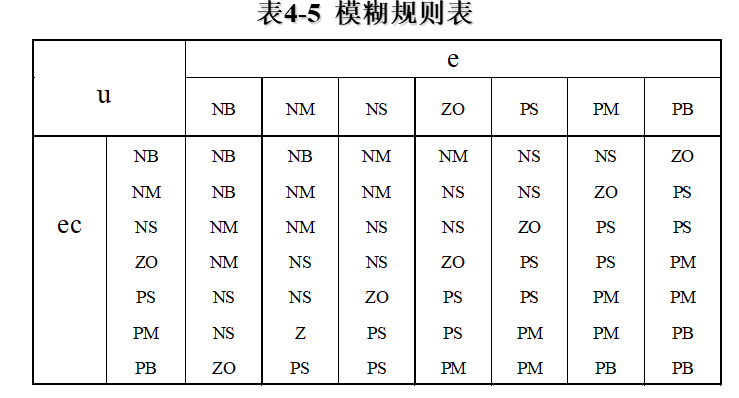
5、 建立模糊控制表
模糊控制规则可采用模糊规则表4-5来描述,共49条模糊规则,各个模糊语句之间是或的关系,由第一条语句所确定的控制规则可以计算出u1。同理,可以由其余各条语句分别求出控制量u2,…,u49,则控制量为模糊集合U可表示为 :
![]()
6 模糊推理
模糊推理是模糊控制的核心,它利用某种模糊推理算法和模糊规则进行推理,得出最终的控制量。
7 反模糊化
通过模糊推理得到的结果是一个模糊集合。但在实际模糊控制中,必须要有一个确定值才能控制或驱动执行机构。将模糊推理结果转化为精确值的过程称为反模糊化。常用的反模糊化有三种:
(1)最大隶属度法
选取推理结果模糊集合中隶属度最大的元素作为输出值,即:
![]()
如果在输出论域V中,其最大隶属度对应的输出值多于一个,则取所有具有最大隶属度输出的平均值,即:
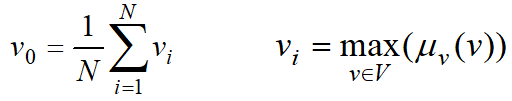
N为具有相同最大隶属度输出的总数。
最大隶属度法不考虑输出隶属度函数的形状,只考虑最大隶属度处的输出值。因此,难免会丢失许多信息。它的突出优点是计算简单。在一些控制要求不高的场合,可采用最大隶属度法。
(2) 重心法
为了获得准确的控制量,就要求模糊方法能够很好的表达输出隶属度函数的计算结果。重心法是取隶属度函数曲线与横坐标围成面积的重心为模糊推理的最终输出值,即:
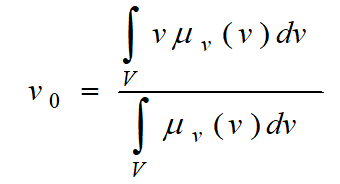
对于具有m个输出量化级数的离散域情况:
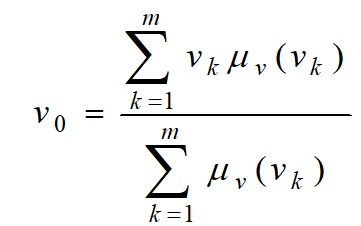
与最大隶属度法相比较,重心法具有更平滑的输出推理控制。即使对应于输入信号的微小变化,输出也会发生变化。
(3)加权平均法
工业控制中广泛使用的反模糊方法为加权平均法,输出值由下式决定:
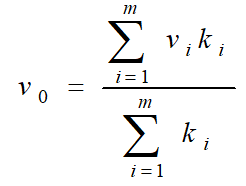
其中系数ki的选择根据实际情况而定。不同的系数决定系统具有不同的响应特性。当系数ki取隶属度μv(vi)时,就转化为重心法。
反模糊化方法的选择与隶属度函数形状的选择、推理方法的选择相关
Matlab提供五种解模糊化方法:(1)centroid:面积重心法;(2)bisector:面积等分法;(3)mom:最大隶属度平均法;(4)som最大隶属度取小法;(5)lom:大隶属度取大法;
在Matlab中,可通过setfis()设置解模糊化方法,通过defuzz()执行反模糊化运算。
