综述
本科毕设做的是BM25的算法改进,说实话效果还可以,现在读研遇到新领域,对这一块有了新的想法,于是回顾过来再看看tf-idf相关内容,也是为论文点做铺垫吧。
TF-IDF
1、思路
TF-IDF用词频和逆向文件频率的统计信息来获取词语的得分。
总的来说,TF-IDF是一种统计函数方法,用来评估查询词对于一个文件集或一个语料库中的其中一份文件的重要程度。
明显的,如果一个词在一篇文章中出现的词数越多,那么这个词和这篇文章的相关性越高;如果一个词在在整个文库中,出现在越多的文章中,那这个词的区分度就越低。举个例子吧,比如语料库A中包含了各种主题的文章,“科技”一词在其中一片文章a中频繁出现,那么“科技”就很明显的将文章a和A中的其他文章相区分,那么“科技”对于文章a来说相比于其他词汇就应该能得到更高的分数。
2、公式
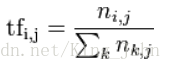
分子代表着第 j 篇文档中词语 i 的词频数;
分母代表着第 j 篇文档中第1-k个(所有)词语的词频数;
通过wordi的频数除以所有总频数,得出频率tf。

分子代表着数据集中文档总数;
分母代表着数据集中包含词 i 的文档总数;
通过两者比,并求取对数,得到idf。
3、idf的信息论解释

【摘自维基百科】
BM25
1、思路
BM25, and its newer variants, e.g. BM25F (a version of BM25 that can take document structure and anchor text into account), represent state-of-the-art TF-IDF-like retrieval functions used in document retrieval.
其实可以说就是tfidf经过一些优化之后得到了BM25.
idf的思想没有变,用另外一条公式替代了tf。
2、公式
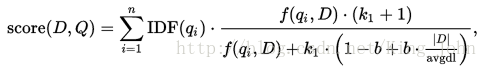
qi是查询词序列中第 i 个词;
IDF(qi)是qi的idf值;
f(qi,D)是qi在文档D中的词频;
k1是取之于[1.2,2.0]之间的常量;
b是一般取值为0.75的常量;
|D|是文档D的长度;
avgdl是语料库中文档的平均长度。