Tf-idf
特征抽取:从原始数据中抽取特征
Tf-idf:词频-逆向文件频率。是一种在文本挖掘中广泛使用的特征向量化方法,它可以提现一个文档中词语在语料库中的重要程度
词语:用t表示
文档:用d表示
语料库:用D表示
•Transformer:翻译成转换器,是一种可以将一个DataFrame转换为另一个DataFrame的算法。比如一个模型就是一个 Transformer。它可以把 一个不包含预测标签的测试数据集 DataFrame 打上标签,转化成另一个包含预测标签的 DataFrame。技术上,Transformer实现了一个方法transform(),它通过附加一个或多个列将一个DataFrame转换为另一个DataFrame。
•Estimator:翻译成估计器或评估器,它是学习算法或在训练数据上的训练方法的概念抽象。在 Pipeline 里通常是被用来操作 DataFrame 数据并生产一个 Transformer。从技术上讲,Estimator实现了一个方法fit(),它接受一个DataFrame并产生一个转换器。
词频TF(t,d): 词语t在文档中出现的次数的频率, HashingTF 是一个Transformer,在文本处理中,接收词条的集合然后把这些集合转化成固定长度的特征向量。这个算法在哈希的同时会统计各个词条的词频。
文件频率DF(t,D):包含词t的文档个数IDF是一个Estimator,在一个数据集上应用它的fit()方法,产生一个IDFModel。 该IDFModel 接收特征向量(由HashingTF产生),然后计算每一个词在文档中出现的频次。IDF会减少那些在语料库中出现频率较高的词的权重。
如果只使用词频来衡量重要性,很容易过度强调在文档中经常出现,却没有太多实际信息的词语,比如说"a","the"以及“of”,如果一个词语经常出现在语料库中,意味着它并不是很好的对文档进行分区,TF-IDF就是在数值化文档信息,衡量词语提供多少信息以及分区文档
逆向文件频率IDF(t,D)=log((D+1)/(DF(t,D)+1) )
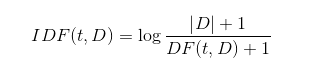
此处时D 是语料库中总的文档数,公式中使用log函数,档次出现在所有文档种时候,它的IDF值就为0,加1是为了避免分母为0的情况
IF-IDF度量值表示:
TFIDF(t,d,D)=TF(t,d)* IDF(t,D)
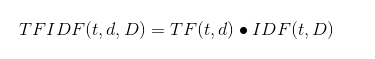
log的底数实际上可以随便取,因为最后我们只关心相对大小。容易发现,如果单词越普遍,它的IDF越小,极端情况是DF(t)=N时,IDF(t)=0,从下面的式子能看出,这实际上就起到了stop list的效果。把这两项结合起来,对单词t和文档d,定义TF-IDF(t,d) = TF(t,d) * IDF(t)。直观来解释就是:一个单词在一篇文档中出现次数越多,它的权重越大;
举个例子:
假如有一篇文章,词语数量=100 ,但是词语“机器学习"出现了3次,那么“机器学习"一词在该文件中的词频就是3/100=0.03。如果“机器学习"一词在999份文件中出现过,并且文件总数为9999999份的话,逆向文件频率就是log((9999999+1)/(999+1))=4以10为底),最后的TF-IDF值就是0.03*4-0.12
package TFIDNDemo
import org.apache.spark.ml.feature.{HashingTF, IDF, IDFModel, Tokenizer}
import org.apache.spark.sql.{DataFrame, SQLContext}
import org.apache.spark.{SparkConf, SparkContext}
/**
* @Author: zxl
* @Date: 2019/1/2 15:28
* @Version 1.0
*/
object mlDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName(this.getClass.getName)
.setMaster("local[*]")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
val sData = sqlContext.createDataFrame(Seq(
(0,"hi i ha aaa"),
(1,"i wish java could use case classes"),
(2,"logistic regression models are neat")
)).toDF("label","sentence")
// 把句子进行切分成每个单词
val tokenizer = new Tokenizer().setInputCol("sentence").setOutputCol("words")
val wordData = tokenizer.transform(sData)
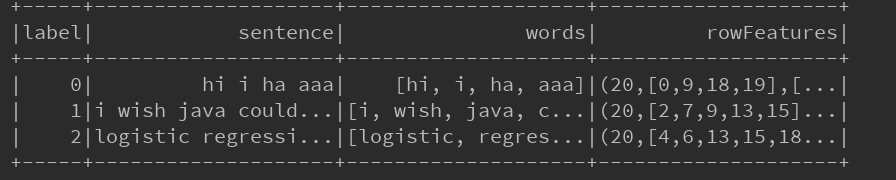
wordData.show()
//HashingTF的transform()方法把句子哈希成特征向量
// setNumFeatures(20) 设置 特征值,相当于相量的维数,这个值必须超过 文本中单词的个数最大的一个
// (20,[0,9,18,19],[...| [] 是稀疏向量,是TF的一个权重
val hashingTF = new HashingTF().setInputCol("words").setOutputCol("rowFeatures")
.setNumFeatures(20)
val featurizedData = hashingTF.transform(wordData)
// TF值(单词在 文本中出现的次数)
//分词序列被变换成一个稀疏特征向量,其中每个单词都被散列成了一个不同的索引值,特征向量在某一维度上的值即该词汇在文档中出现的次数。
featurizedData.show()
val idf = new IDF().setInputCol("rowFeatures").setOutputCol("features")
// 一般模型计算完了会保存到hdfs中,为了以后数据 的加载模型计算
val idfModel: IDFModel = idf.fit(featurizedData)
val rescaledData: DataFrame = idfModel.transform(featurizedData)
rescaledData.select("features","label").take(3).foreach(println)
//[(20,[0,9,18,19],[0.6931471805599453,0.28768207245178085,0.28768207245178085,0.6931471805599453]),0]
// 在0 的idf-idf是0.6931471805599453,除了0、9、18、19 之外的都是0
}
}