一. 什么是TF-IDF
TF-IDF(Term Frequency-Inverse Document Frequency, 词频-逆文件频率).
是一种用于资讯检索与资讯探勘的常用加权技术。TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
上述引用总结就是, 一个词语在一篇文章中出现次数越多, 同时在所有文档中出现次数越少, 越能够代表该文章.
这也就是TF-IDF的含义.
词频 (term frequency, TF) 指的是某一个给定的词语在该文件中出现的次数。这个数字通常会被归一化(一般是词频除以文章总词数), 以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词频,而不管该词语重要与否。)
但是, 需要注意, 一些通用的词语对于主题并没有太大的作用, 反倒是一些出现频率较少的词才能够表达文章的主题, 所以单纯使用是TF不合适的。权重的设计必须满足:一个词预测主题的能力越强,权重越大,反之,权重越小。所有统计的文章中,一些词只是在其中很少几篇文章中出现,那么这样的词对文章的主题的作用很大,这些词的权重应该设计的较大。IDF就是在完成这样的工作.
公式:
TFw=在某一类中词条w出现的次数该类中所有的词条数目
逆向文件频率 (inverse document frequency, IDF) IDF的主要思想是:如果包含词条t的文档越少, IDF越大,则说明词条具有很好的类别区分能力。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到。
公式:
IDF=log(语料库的文档总数包含词条w的文档数+1),分母之所以要加1,是为了避免分母为0
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
TF−IDF=TF∗IDF
二. 一个实例
参考: http://www.ruanyifeng.com/blog/2013/03/tf-idf.html
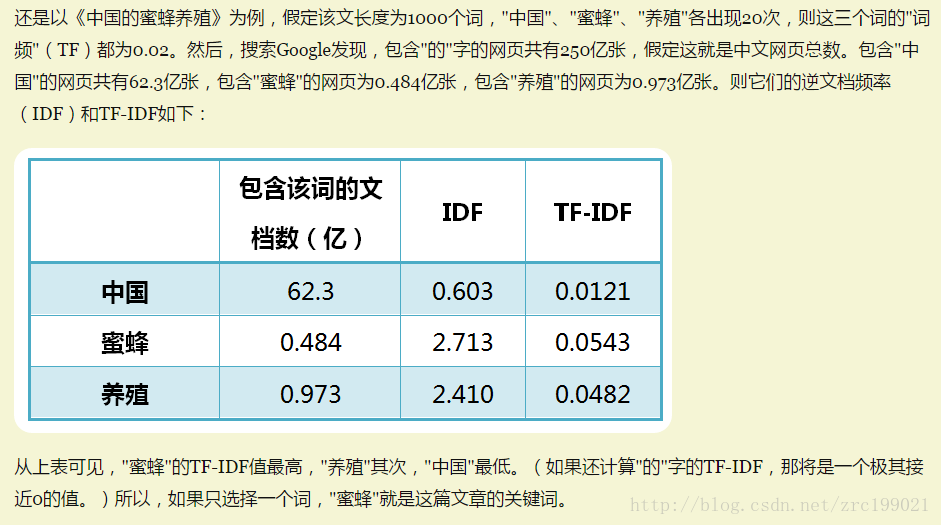
三. Spark 中 TF-IDF 的实现
1. 基于spark1.4.1 ml算法包的TF-IDF算法
// 参考自spark官网教程 http://spark.apache.org/docs/latest/ml-features.html#tf-idf
// In the following code segment, we start with a set of sentences.
// We split each sentence into words using Tokenizer. For each sentence (bag of words),
// we use HashingTF to hash the sentence into a feature vector. We use IDF to rescale
// the feature vectors; this generally improves performance when using text as features. // Our feature vectors could then be passed to a learning algorithm.
import org.apache.spark.{SparkContext, SparkConf}
import org.apache.spark.ml.feature.{Tokenizer,HashingTF, IDF}
import org.apache.spark.mllib.linalg.{Vectors, Vector}
// 创建实例数据
val sentenceData = sqlContext.createDataFrame(Seq(
(0, "Hi I heard about Spark"),
(0, "I wish Java could use case classes"),
(1, "Logistic regression models are neat")
)).toDF("label", "sentence")
// scala> sentenceData.show
// +-----+--------------------+
// |label| sentence|
// +-----+--------------------+
// | 0|Hi I heard about ...|
// | 0|I wish Java could...|
// | 1|Logistic regressi...|
// +-----+--------------------+
//句子转化成单词数组
val tokenizer = new Tokenizer().setInputCol("sentence").setOutputCol("words")
val wordsData = tokenizer.transform(sentenceData)
// scala> wordsData.show
// +-----+--------------------+--------------------+
// |label| sentence| words|
// +-----+--------------------+--------------------+
// | 0|Hi I heard about ...|ArrayBuffer(hi, i...|
// | 0|I wish Java could...|ArrayBuffer(i, wi...|
// | 1|Logistic regressi...|ArrayBuffer(logis...|
// +-----+--------------------+--------------------+
// hashing计算TF值,同时还把停用词(stop words)过滤掉了. setNumFeatures(20)表最多20个词
val hashingTF = new HashingTF().setInputCol("words").setOutputCol("rawFeatures").setNumFeatures(20)
val featurizedData = hashingTF.transform(wordsData)
// scala> featurizedData.show
// +-----+--------------------+--------------------+--------------------+
// |label| sentence| words| rawFeatures|
// +-----+--------------------+--------------------+--------------------+
// | 0|Hi I heard about ...|ArrayBuffer(hi, i...|(20,[5,6,9],[2.0,...|
// | 0|I wish Java could...|ArrayBuffer(i, wi...|(20,[3,5,12,14,18...|
// | 1|Logistic regressi...|ArrayBuffer(logis...|(20,[5,12,14,18],...|
// +-----+--------------------+--------------------+--------------------+
val idf = new IDF().setInputCol("rawFeatures").setOutputCol("features")
val idfModel = idf.fit(featurizedData)
val rescaledData = idfModel.transform(featurizedData)
// 提取该数据中稀疏向量的数据,稀疏向量:SparseVector(size,indices,values)
// rescaledData.select("features").rdd.map(row => row.getAs[linalg.Vector](0)).map(x => x.toSparse.indices).collect
rescaledData.select("features", "label").take(3).foreach(println)
// [(20,[5,6,9],[0.0,0.6931471805599453,1.3862943611198906]),0]
// [(20,[3,5,12,14,18],[1.3862943611198906,0.0,0.28768207245178085,0.28768207245178085,0.28768207245178085]),0]
// [(20,[5,12,14,18],[0.0,0.5753641449035617,0.28768207245178085,0.28768207245178085]),1]
// 其中,20是标签总数,下一项是单词对应的hashing ID.最后是TF-IDF结果2.基于RDD的MLlib包中的TF_IDF算法
//参考: http://spark.apache.org/docs/1.4.1/mllib-feature-extraction.html#tf-idfark.mllib.feature.HashingTF
//进阶参考
//http://blog.csdn.net/jiangpeng59/article/details/52786344
import org.apache.spark.mllib.linalg.Vector
val sc: SparkContext = ...
// Load documents (one per line).
val documents: RDD[Seq[String]] = sc.textFile("...").map(_.split(" ").toSeq)
val hashingTF = new HashingTF()
val tf: RDD[Vector] = hashingTF.transform(documents)
tf.cache()
val idf = new IDF().fit(tf)
val tfidf: RDD[Vector] = idf.transform(tf)四. 参考
http://blog.csdn.net/google19890102/article/details/29369793
http://www.ruanyifeng.com/blog/2013/03/tf-idf.html
http://www.cnblogs.com/rausen/p/4142838.html
http://blog.csdn.net/jiangpeng59/article/details/52786344