前言
PS:树型结构是一种重要的非线性数据结构,教科书上一般都是树与二叉树,由此可见,树和二叉树是有区别和联系的,网上有人说二叉树是树的一种特殊形式,但经过查资料,树和二叉树没有一个肯定的说法,但唯一可以肯定都是树型结构。但是按照定义来看二叉树并不是树的一种特殊形式(下面解释)。树型数据结构的作用可以表示数据元素之间一对多的关系,一个公司里的各个部门都可以用树形来表示。
二叉树不是树的一种特殊情形,主要差别:
- 树中结点的最大度数没有限制,而二叉树结点的最大度数为2;
- 树的结点无左、右之分,而二叉树的结点有左、右之分。
二叉树类型
(1)完全二叉树 ——若设二叉树的高度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第h层有叶子结点,并且叶子结点都是从左到右依次排布,这就是完全二叉树。
(2)满二叉树 ——除了叶结点外每一个结点都有左右子叶且叶子结点都处在最底层的二叉树。
(3)平衡二叉树——平衡二叉树又被称为AVL树(区别于AVL算法),它是一棵二叉排序树,且具有以下性质:它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。
二叉树的链式
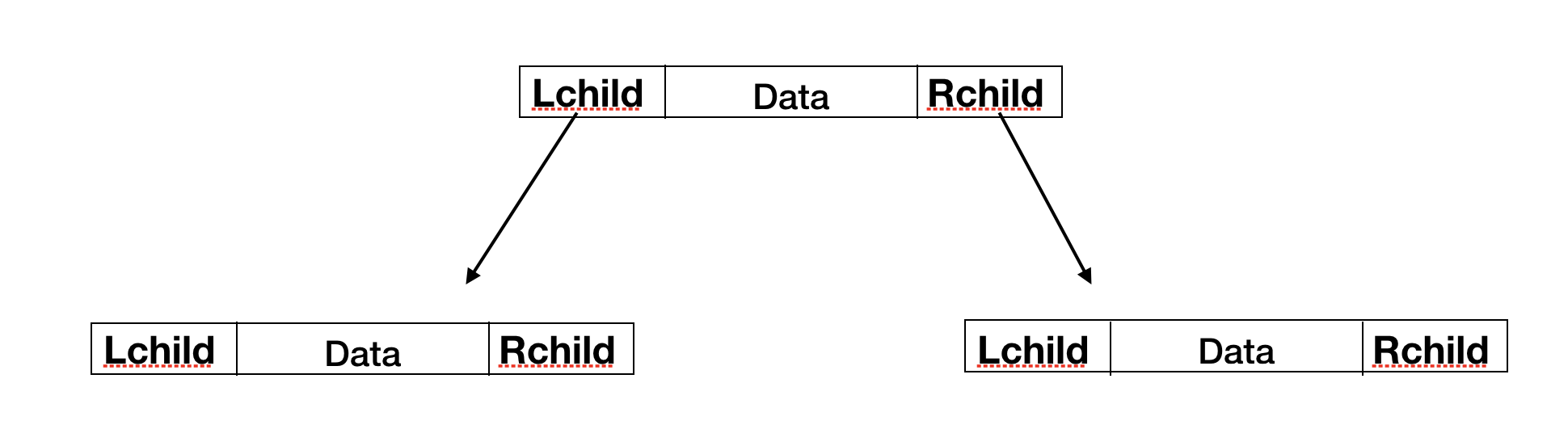
1:结构体
typedef struct twoCha {
char data;
struct twoCha *Lchild, *Rchild;//左右孩子结点
} twoCha, *twoChaL;
2:创建二叉树
当我们在键盘上敲了一行的char类型数据,可以按照一定的结构储存在计算机上,就要写一个算法,二叉树分左右孩子,所以,如果没有左(右)孩子就输入一个空格或者#,代表空。如果有左(右)孩子就新建一个结点,来存放该结点的数据data。

int createTwo(twoChaL &tL) {
char ch;
scanf("%c",&ch);
if (ch == '#')
{
tL = NULL;
return 0;
}
else
{
tL= (twoChaL)malloc(sizeof(twoCha));
if (tL == NULL)
{
printf("错误tl=NULL\n");
return 0;
}
else
{
tL->data = ch;
createTwo(tL->Lchild);
createTwo(tL->Rchild);
}
}
return 0;
}
3:递归遍历
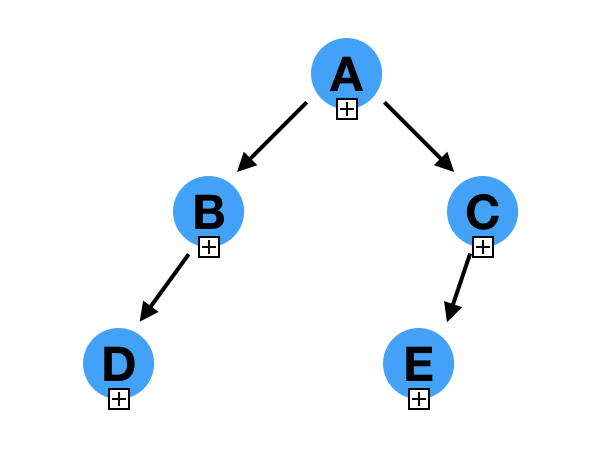 画的不好,凑活着看吧。
画的不好,凑活着看吧。
我们以这个二叉树为例子,来分析他的遍历形式,遍历分为三种
- 先序遍历 -- 根左右 -- ABDCE
- 中序遍历 -- 左根右 -- DBAEC
- 后序遍历 -- 左右根 -- DBECA
void diGuiBianLi(twoChaL &tL,int xl)
{
if (tL == NULL)
{
return;
}
else
{
if(xl == 1){
//先序遍历
printf("%c ",tL->data);
diGuiBianLi(tL->Lchild,xl);
diGuiBianLi(tL->Rchild,xl);
}else if(xl == 2){
//中序遍历
diGuiBianLi(tL->Lchild,xl);
printf("%c ",tL->data);
diGuiBianLi(tL->Rchild,xl);
}
else if(xl == 3){
//后序遍历
diGuiBianLi(tL->Lchild,xl);
diGuiBianLi(tL->Rchild,xl);
printf("%c ",tL->data);
}
}
}
递归的代码非常少,但是一开始接触 理解起来还是比较难的,当然,你一旦理解后,那就非常简单了。递归的思想就是把一个大问题分成多个类似的小问题解决。
4:叶子个数
方法:查找一个结点没有左右孩子,就是叶子结点。可以定义一个static int count变量,如果该结点没有左右结点那么就让count++;
int leafCount(twoChaL &tL)
{
static int count;
if (tL != NULL)
{
if (tL->Lchild == NULL && tL->Rchild == NULL)
{
count++;
}
leafCount(tL->Lchild);
leafCount(tL->Rchild);
}
return count;
}
5:深度
方法:看结点的左孩子和右孩子哪一个更长,当深入到最低结点时,左右孩子比较,谁大谁加一(相等左孩子加一)。
int treeDeep(twoChaL &tL)
{
int deep = 0;
if (tL != NULL)
{
int leftdeep = treeDeep(tL->Lchild);
int rightdeep = treeDeep(tL->Rchild);
deep = leftdeep >= rightdeep?leftdeep+1:rightdeep+1;
}
return deep;
}
6:非递归遍历
这里以中序为例,利用栈的知识点(顺序栈),首先把根节点进栈,然后依次左孩子进栈,直到左孩子为NULL时结束,但是NULL也是入栈的,然后再把NULL出栈,下一步就是把栈顶元素取出并打印,再把该栈顶元素的右孩子进栈,不管右孩子是不是NULL都要入栈,入栈之前把栈顶元素弹栈。
定义栈的data域,要用结点的结构体
int top = -1;
//栈
void push(twoChaL *a,twoChaL elem){
a[++top]=elem;
}
//弹栈函数
void pop(){
if (top==-1) {
return ;
}
top--;
}
//拿到栈顶元素
twoChaL getTop(twoChaL *a){
return a[top];
}
void zhongXu2(twoChaL Tree){
//顺序栈
twoChaL a[100];
twoChaL p;
push(a, Tree);//根结点进栈
while (top!=-1) {//top!=-1说明栈内不为空
while ((p=getTop(a)) &&p){//取栈顶元素,且不能为NULL
push(a, p->Lchild);//将该结点的左孩子进栈,如果没有左孩子,NULL进栈
}
pop();//跳出循环,栈顶元素肯定为NULL,将NULL弹栈
/*
//测试数据,主要观察栈中NULL出栈后,还有什么在栈中(栈顶),
if(a[top]){
printf(" 跳出循环 %c\n",a[top]->data);
}*/
if (top!=-1) {
p=getTop(a);//取栈顶元素
pop();//栈顶元素弹栈
printf("%c ",p->data);
push(a, p->Rchild);//将p指向的结点的右孩子进栈
}
}
}
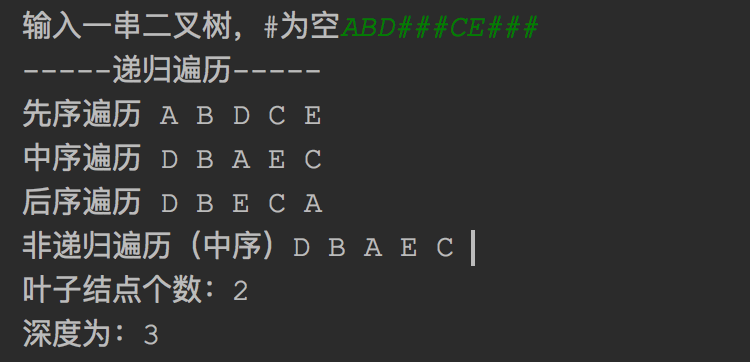
结果图: