#_*_ coding:utf-8 _*_ #识别中文注释的意思 import urllib.request #导入urllib包中的request模块,主要是获取网页内容 def load_page(url): #定义下载网页内容的函数 ''' 发送url请求 返回url请求的静态html页面 ''' # user_agent ="Mozilla/5.0 (Windows NT 10.0; …) Gecko/20100101 Firefox/60.0" #模拟浏览器的代理 # header = {"User-Agent":user_agent} #请求头为一个dict类型 response = urllib.request.urlopen(url) #向服务器发送网页内容request,请求并获得服务器的反馈内容 html = response.read() #反馈的内容读取放置到response实例化对象中 return (html) #函数返回网页内容 def write_to_file(file_name,txt): #定义写入文件的函数 ''' 将txt文本存入到file_name ''' print("正在存储文件" + file_name) #字符串相加 # 1 打开文件 f = open(file_name,'w') #以write方式打开文件,文件有内容则清除再写入,文件没有则新增,没指定目录则放在当前目录 # 2 读写文件 f.write(str(txt)) #把网页内容写入文件 # 3 关闭文件 f.close() #关闭文件,不然占内存 def tieba_spider(url,begin_page,end_page): #定义爬虫函数,参数个数看函数体需要 ''' 贴吧小爬虫的方法 ''' for i in range(begin_page,end_page + 1): #循环爬取用户指定网页页码范围 # i = 1, pn = 0 ,根据网址找出规律:https://tieba.baidu.com/f?kw=lol&ie=utf-8&pn=0 # i = 2, pn = 50 ,根据网址找出规律:https://tieba.baidu.com/f?kw=lol&ie=utf-8&pn=50 # i = 3, pn = 100 ,根据网址找出规律:https://tieba.baidu.com/f?kw=lol&ie=utf-8&pn=100 # ... pn = 50 * (i - 1) #找出页码跟i的规律 #组成一个完整url my_url = url +str(pn) #网页的通用写法 #print“请求的地址:” #print my_url html = load_page(my_url) #以网页为参数调用下载内容的函数 # print("=====第%d页====="%(i)) # print(html) # print("================") file_name = str(i)+".html" #定义文件名的写法 write_to_file(file_name,html) #以文件名和网页为参数调用写入文件的函数 if __name__ == '__main__': #限本包内使用 url = input("请输入贴吧的url地址:") #请求用户输入贴吧通用网页前缀 #print url begin_page =int(input("请输入起始页数:")) #请求用户输入起始页码 end_page = int(input("请输入最终页数:")) #请求用户输入结束页码 tieba_spider(url,begin_page,end_page) #创建爬虫并开始执行
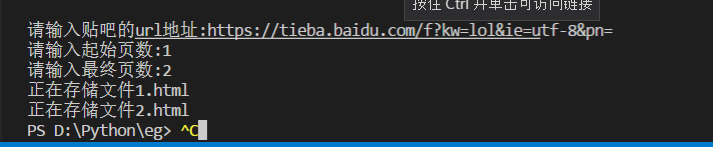

在当前目录下新增了两个html文件,这就是第一页和第一页百度贴吧的内容。
注意:注释不要用Tab键当空格用,会报错。本文并没有用请求头。