反向传播算法(Backpropagation algorithm即BP算法)
看了好几篇相关文章,终于大致搞清楚了反向传播时候隐藏层的误差求导到底是怎么算的,,,为了防止遗忘还是记一下。
每一个神经元就像一个苹果一样,用net表示左一半(和它前面一层相关),out表示右一半(和后一层相关)。这两半之间的关系,就是激活函数作用在net上,到右边就是out了。

用实际的例子来理解正向传播比较清楚,反向传播也是根据链式求导不断导导导直到出来和本层输入和输出相关的公式。我都快晕了。。。为方便记忆用2*2*2的三层神经网络说明。
变量说明:i为输入,h为隐藏层,o为输出层,b为偏置(我的理解是就是加一个常数项,但是后面只更新权重,并没去更新这个常数,不知道为啥,有待继续学习...)
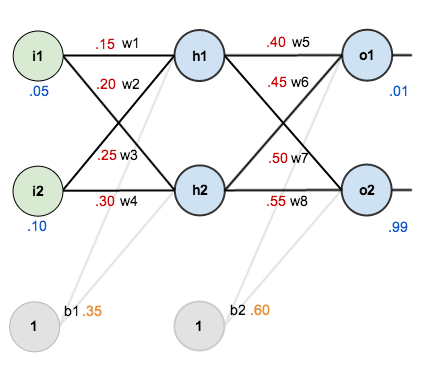
前向传播就是按照:
比如:输入层到隐藏层h:
,
为激活函数,这里假设为sigmoid函数。对于不同的层,加上对应的脚注就好了。然后一直乘上各自权重再加上偏值,一直到最后一层。
主要记录一下反向传播求导:
有两个输出神经元的话,设第一个神经元输出误差损失为E1,第二个为E2。公式就是
一开始不知道为啥要求导,这和误差损失有啥关系,后来看了文末的文章知道了,对谁求导就是看一下它对误差损失带来多大的影响。对所有权重都要求导,看看权重的影响。最后不断更新权重,这就是误差反向传播的目的吧大概。
但是从公式可以看出,误差损失和权重向量并没有直接关系,这可咋办,,,所以就用到了链式求导法则,不断凑合本层所求的神经元相连接的各种函数,直到凑出来和权重有关。但是也不是瞎凑的。。。
因为和误差损失直接相关的是输出层函数,所以要从输出层开始计算权重带来的误差损失然后逐渐往输入方向求(即反向传播)。所有误差损失计算总误差对权重求导,化简后
后面求导为零。
因为和E1相关的权重只有w5和w6。所以只有第三项不一样。
和E2相关的权重有w7和w8。
假设上面四个式子前面两项为一个函数形式简化表达:
至于为啥要简化,,,自己一步一步推导之后发现后面很有用,求权重导数的时候很有规律。。。
直接写结果:
然后后面那一项也有规律,,,
然后求w1-w4权重带来的影响:
同样求导:
这个地方有个小坑,因为把求导链式写出之后,发现这是啥啊,这个误差损失离w1这么远这怎么算啊,还有这个里面的误差损失也不一样,我看了文末的文献之后才明白,原来这里的误差损失是总的损失,是E1和E2两个输出误差损失共同作用的结果。
(1)
(2)
那么问题又来了,这E1和E2和隐藏层隔得这么远这怎么算对它的偏导啊,你让我算输出层的还行,隐藏层咋算。。。
所以这就是链式求导法则的妙处啊。。。就往最后一层输出层的脚标使劲凑就行了。。。链式求导那一层的net对应那一层的out,同一个苹果左右两半下角标要一样。o1对应h1,o2对应h2。并且和E1,E2对应。
突然发现前面两项有点眼熟,就是a1和a2。上式化简代入(1)和(2)中
有点对称的感觉。
最后根据权重更新公式:
一直迭代,直到满足目标为止。
import numpy as np
# "pd" 偏导
#b为偏值
#w为权重
#i为输入数据
#target为目标数据
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def sigmoidDerivationx(y):
return y * (1 - y)
if __name__ == "__main__":
#初始化
b = [0.35, 0.60]#偏值
w = [0.15, 0.2, 0.25, 0.3, 0.4, 0.45, 0.5, 0.55]#权重
i1 = 0.05
i2 = 0.10
target1 = 0.01
target2 = 0.99
alpha = 0.5 #学习速率
numIter = 10000 #迭代次数
for i in range(numIter):
neth1 = i1*w[0] + i2*w[1] + b[0]#正向传播
neth2 = i1*w[2] + i2*w[3] + b[0]
outh1 = sigmoid(neth1)
outh2 = sigmoid(neth2)
neto1 = outh1 * w[4] + outh2 * w[5]
neto2 = outh1 * w[6] + outh2 * w[7]
outo1 = sigmoid(neto1)
outo2 = sigmoid(neto2)
print("Interation:{} target1 is {},output1 is{};target2 is {},output2 is {}".format(i,target1,outo1,target2,outo2))
#反向传播更新权重w5-w8
E1 = (target1 - outo1)**2/2
E2 = (target2 - outo2)**2/2
pdE1outo1 = - (target1 - outo1)
pdE2outo2 = - (target2 - outo2)
pdouto1neto1 = sigmoidDerivationx(outo1)#就是y(1-y)
pdouto2neto2 = sigmoidDerivationx(outo2)
pdneto1w5 = outh1
pdneto1w6 = outh2
pdneto2w7 = outh1
pdneto2w8 = outh2
a1 = pdE1outo1 * pdouto1neto1 #为简化运算将链式求导前两项简化为a函数
a2 = pdE2outo2 * pdouto2neto2
pdE1w5 = a1 * pdneto1w5
pdE1w6 = a1 * pdneto1w6
pdE2w7 = a2 * pdneto2w7
pdE2w8 = a2 * pdneto2w8
#更新w1-w4权重
pdouth1neth1 = sigmoidDerivationx(outh1)#此时为outh1(1-outh1)
pdouth2neth2 = sigmoidDerivationx(outh2)
pdEw1 = (a1*w[5-1] + a2*w[7-1])*pdouth1neth1*i1
pdEw2 = (a1*w[5-1] + a2*w[7-1])*pdouth1neth1*i2
pdEw3 = (a2*w[6-1] + a2*w[8-1])*pdouth2neth2*i1
pdEw4 = (a2*w[6-1] + a2*w[8-1])*pdouth2neth2*i2
w[0] = w[0] - alpha * pdEw1
w[1] = w[1] - alpha * pdEw2
w[2] = w[2] - alpha * pdEw3
w[3] = w[3] - alpha * pdEw4
w[4] = w[4] - alpha * pdE1w5
w[5] = w[5] - alpha * pdE1w6
w[6] = w[6] - alpha * pdE2w7
w[7] = w[7] - alpha * pdE2w8
print("Finally output1 is {}; output2 is {}".format(outo1,outo2))
for j in range(8):
print("{} is : {}.".format("w{}".format(j+1),w[j]))参考来源:
https://mattmazur.com/2015/03/17/a-step-by-step-backpropagation-example/
英文搬运
https://www.cnblogs.com/charlotte77/p/5629865.html
中文搬运