Map框架图
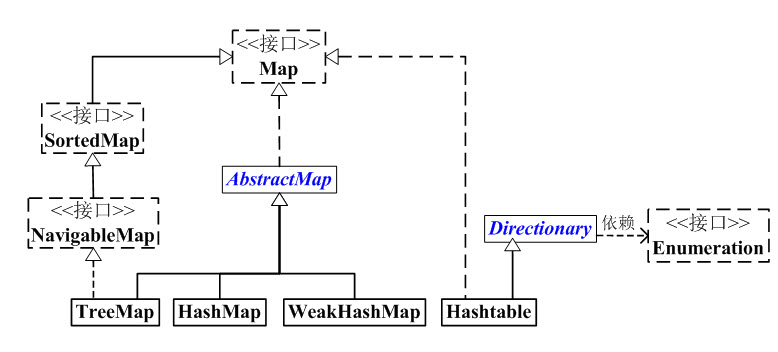
Map概括
- Map是键值对映射的抽象接口
- AbstractMap实现了Map中的大部分接口,减少了Map实现类的重复代码
- HashMap是基于拉链法实现的散列表,一般使用在单线程程序中
- HashTable是基于拉链法实现的散列表,一般使用在多线程程序中
HashMap,HashTable异同
- 共同点
都是散列表,都是基于拉链法实现的
存储的思想是:通过table数组存储,数组的每一个元素都是一个Entry,而一个Entry就是一个单向链表,Entry链表中的每一个节点就保存了KV键值对数据。
添加KV键值对:首先根据Key,通过哈希算法得到哈希值,在计算出数组相对的索引index,然后根据索引值找到table数组中的Entry,再遍历单向链表,将key和链表中的key进行对比,如果已经有存在相同的key了,就用该value取代原value,如果不存在的话,就新建一个KV节点,并且将该节点放在链表的表头位置。
删除键值对:首先根据key计算出哈希值,再计算出索引,根据索引找到Entry,如果节点KV存在,就删除完事了。
我们更多关注的是不同点:
- 1,继承和实现的方式不同
HashMap继承与AbstractMap ,实现了Map,Cloneable,Serializable接口
HashMap继承与Dictionary,实现了Map,Cloneable,Serializable接口
HashMap源代码
public class HashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable { ... }Hashtable源代码
public class Hashtable<K,V>
extends Dictionary<K,V>
implements Map<K,V>, Cloneable, java.io.Serializable { ... }我们可以看出:
1,.1:都实现了Map接口,意味着都是键值对操作,支持添加KV,获取K,获取V,获取map大小,清空map等基础的map操作
实现了Cloneable接口,可以被克隆
实现了Serializable接口,支持序列化,能够通过序列化去传输
1.2:HashMap继承于AbstractMap,而HashTable继承于Dictionary
Dictionary是一个抽象类,直接继承于Object,没有实现任何接口,虽然Dictionary也支持添加KV,获取V,获取大小等基本操作,但是API函数没有Map的多,而且Dictionary一般是通过Enumeration(枚举)去遍历,然而由于实现了Map接口,所以也支持Iterator遍历,
- 2,线程安全不同
HashTable的几乎所有函数都是同步的,即是支持线程安全,支持多线程
HashMap是非同步的,不是线程安全,如果要在多线程中使用HashMap,需要我们额外进行同步处理,对HashMap的同步处理可以使用Collections类提供的synchronizedMap静态方法,或者直接使用JDK 5.0之后提供的java.util.concurrent包里的ConcurrentHashMap类。
- 3,对null值处理的不同
HashMap的键值对都可以为null(null键会放在table[0],而且table[0]处只会容纳一个key为null的值,当有多个key为null的值插入的时候,table[0]会保留最后插入的value。)
HashTable的键值对都不可以为null(抛出空指针异常)
// 将“key-value”添加到HashMap中
public V put(K key, V value) {
// 若“key为null”,则将该键值对添加到table[0]中。
if (key == null)
return putForNullKey(value);
// 若“key不为null”,则计算该key的哈希值,然后将其添加到该哈希值对应的链表中。
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
// 若“该key”对应的键值对已经存在,则用新的value取代旧的value。然后退出!
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
// 若“该key”对应的键值对不存在,则将“key-value”添加到table中
modCount++;
addEntry(hash, key, value, i);
return null;
}
// putForNullKey()的作用是将“key为null”键值对添加到table[0]位置
private V putForNullKey(V value) {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
// recordAccess()函数什么也没有做
e.recordAccess(this);
return oldValue;
}
}
// 添加第1个“key为null”的元素都table中的时候,会执行到这里。
// 它的作用是将“设置table[0]的key为null,值为value”。
modCount++;
addEntry(0, null, value, 0);
return null;
}// 将“key-value”添加到Hashtable中
public synchronized V put(K key, V value) {
// Hashtable中不能插入value为null的元素!!!
if (value == null) {
throw new NullPointerException();
}
// 若“Hashtable中已存在键为key的键值对”,
// 则用“新的value”替换“旧的value”
Entry tab[] = table;
// Hashtable中不能插入key为null的元素!!!
// 否则,下面的语句会抛出异常!
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
V old = e.value;
e.value = value;
return old;
}
}
// 若“Hashtable中不存在键为key的键值对”,
// (01) 将“修改统计数”+1
modCount++;
// (02) 若“Hashtable实际容量” > “阈值”(阈值=总的容量 * 加载因子)
// 则调整Hashtable的大小
if (count >= threshold) {
// Rehash the table if the threshold is exceeded
rehash();
tab = table;
index = (hash & 0x7FFFFFFF) % tab.length;
}
// (03) 将“Hashtable中index”位置的Entry(链表)保存到e中 Entry<K,V> e = tab[index];
// (04) 创建“新的Entry节点”,并将“新的Entry”插入“Hashtable的index位置”,并设置e为“新的Entry”的下一个元素(即“新Entry”为链表表头)。
tab[index] = new Entry<K,V>(hash, key, value, e);
// (05) 将“Hashtable的实际容量”+1
count++;
return null;
}- 4,支持的遍历种类不同
HashMap只支持Iterator(迭代器),HashTable支持Iterator,还支持Enumeration(枚举器)
- 5,通过Iterator遍历的时候,便利顺序不同
HashMap是“从前到后”的遍历数组,再对数组某一项的链表,从表头开始遍历
HashTable是“从后往前”遍历数组,,,,,,,
- 6,容量初始值和增加方式不同
HashMap默认的容量大小是16;增加容量时,每次将容量变为“原始容量x2”。
Hashtable默认的容量大小是11;增加容量时,每次将容量变为“原始容量x2 + 1”。
HashMap的加载因子是0.75,初始容量16
// 默认的初始容量是16,必须是2的幂。
static final int DEFAULT_INITIAL_CAPACITY = 16;
// 默认加载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 指定“容量大小”的构造函数
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}如果超过容量,将容量变为原始容量乘以2
// 新增Entry。将“key-value”插入指定位置,bucketIndex是位置索引。
void addEntry(int hash, K key, V value, int bucketIndex) {
// 保存“bucketIndex”位置的值到“e”中
Entry<K,V> e = table[bucketIndex];
// 设置“bucketIndex”位置的元素为“新Entry”,
// 设置“e”为“新Entry的下一个节点”
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
// 若HashMap的实际大小 不小于 “阈值”,则调整HashMap的大小
if (size++ >= threshold)
resize(2 * table.length);
}HashTable的初始容量为11,加载因子0.75
// 默认构造函数。
public Hashtable() {
// 默认构造函数,指定的容量大小是11;加载因子是0.75
this(11, 0.75f);
}超过容量,变为容量的2倍加1
// 调整Hashtable的长度,将长度变成原来的(2倍+1)
// (01) 将“旧的Entry数组”赋值给一个临时变量。
// (02) 创建一个“新的Entry数组”,并赋值给“旧的Entry数组”
// (03) 将“Hashtable”中的全部元素依次添加到“新的Entry数组”中
protected void rehash() {
int oldCapacity = table.length;
Entry[] oldMap = table;
int newCapacity = oldCapacity * 2 + 1;
Entry[] newMap = new Entry[newCapacity];
modCount++;
threshold = (int)(newCapacity * loadFactor);
table = newMap;
for (int i = oldCapacity ; i-- > 0 ;) {
for (Entry<K,V> old = oldMap[i] ; old != null ; ) {
Entry<K,V> e = old;
old = old.next;
int index = (e.hash & 0x7FFFFFFF) % newCapacity;
e.next = newMap[index];
newMap[index] = e;
}
}
}- 7,添加kv时候的哈希算法不同
HashMap添加元素时,是使用自定义的哈希算法。
Hashtable没有自定义哈希算法,而直接采用的key的hashCode()。
- 8,部分API不同
Hashtable支持contains(Object value)方法,而且重写了toString()方法;
而HashMap不支持contains(Object value)方法,没有重写toString()方法。