
List
有序、可重复。
1.ArrayList
是用数组实现的(顺序表),查询速度快,但是在中间添加/删除元素慢,会导致数据移位。线程不安全。
ArrayList有2个构造函数,一个是默认无参的,一个是传入数组大小的。
在JavaEffect书中明确提到,如果预先能知道或者估计所需数据项个数的,需要传入initialCapacity。
因为如果使用无参的构造函数,会首先把EMPTY_ELEMENTDATA赋值给elementData。
然后根据插入个数于当前数组size比较,不停调用Arrays.copyOf()方法,扩展数组大小。造成性能浪费。
2.Vector
是线程安全版的ArrayLsit,它的每个方法都是synchronized方法。
3.Stack
继承Vector。栈。先进后出。
4.LinkedList
是双向数据链表,添加/删除元素快,查询慢,要从头到尾一个一个的找。
Set
无序、不重复。
1.HashSet
底层数据结果是hashmap。线程不安全。
将对象存储在HashSet之前,要确保重写hashCode()方法和equals()方法,这样才能比较对象的值是否相等,确保集合中没有储存相同的对象。如果不重写上述两个方法,那么将使用下面方法默认实现:
public boolean add(Object obj)方法用在Set添加元素时,如果元素值重复时返回 "false",如果添加成功则返回"true"

加到HashSet中的元素实际上是放到map的key里面。
散列表的内部结构

2.LinkedHashSet
继承HashSet。有序。内部使用的是LinkHashMap。
但是它同时使用链表维护元素的次序。这样使得元素看起 来像是以插入顺 序保存的,也就是说,当遍历该集合时候,LinkedHashSet将会以元素的添加顺序访问集合的元素。
LinkedHashSet在迭代访问Set中的全部元素时,性能比HashSet好,但是插入时性能稍微逊色于HashSet。
3.TreeSet
TreeSet是使用二叉树的原理对新add()的对象按照指定的顺序排序(升序、降序),最终调用的是TreeMap的put方法,每增加一个对象都会进行排序,将对象插入的二叉树指定的位置。
有序集合。TreeSet支持两种排序方法:自然排序和定制排序。TreeSet默认采用自然排序。
自然排序
自然排序使用要排序元素的CompareTo(Object obj)方法来比较元素之间大小关系,然后将元素按照升序排列。
Java提供了一个Comparable接口,该接口里定义了一个compareTo(Object obj)方法,该方法返回一个整数值,实现了该接口的对象就可以比较大小。
obj1.compareTo(obj2)方法如果返回0,则说明被比较的两个对象相等,如果返回一个正数,则表明obj1大于obj2,如果是 负数,则表明obj1小于obj2。
如果我们将两个对象的equals方法总是返回true,则这两个对象的compareTo方法返回应该返回0
定制排序
自然排序是根据集合元素的大小,以升序排列,如果要定制排序,应该使用Comparator接口,实现 int compare(To1,To2)方法
Map
1.TreeMap
红黑树是一种近似平衡的二叉查找树,它能够确保任何一个节点的左右子树的高度差不会超过二者中较低那个的一陪。具体来说,红黑树是满足如下条件的二叉查找树(binary search tree):
-
每个节点要么是红色,要么是黑色。
-
根节点必须是黑色
-
红色节点不能连续(也即是,红色节点的孩子和父亲都不能是红色)。
-
对于每个节点,从该点至null(树尾端)的任何路径,都含有相同个数的黑色节点。
在树的结构发生改变时(插入或者删除操作),往往会破坏上述条件3或条件4,需要通过调整使得查找树重新满足红黑树的条件。

TreeMap的底层使用了红黑树来实现,像TreeMap对象中放入一个key-value 键值对时,就会生成一个Entry对象,这个对象就是红黑树的一个节点,其实这个和HashMap是一样的,一个Entry对象作为一个节点,只是这些节点存放的方式不同。
2.HashMap
由buckets数组+链表组成。无序
线程不安全
初始化大小为16。之后每次扩充,容量变为原来的2倍。
按照key关键字的哈希值hashcode和buckets数组的长度取模查找桶的位置,如果key的哈希值hashcode相同,Hash冲突(也就是指向了同一个桶)则每次新添加的作为头节点,而最先添加的在表尾。

查询时间的复杂度:
O(n) = O(k * n)。如果 hashCode() 方法能把数据分散到桶(bucket)中,那么平均是O(1)。
HashMap可以允许存在一个为null的key和任意个为null的value。
3.HashTable
数组+单向链表
线程安全
Hashtable默认 bucket 容量是 11 ,扩容因子是0.75,容量变为原来的2n+1。
也就是说 如果 现在我们创建一个Hashtable,如果里面有8个数值 ,因为:8>=11*0.75;那么,在添加到第8个数值的时候,Hashtable会扩容。
HashTable中的key和value都不允许为null。
Hashtable比HashMap多提供了elments() 和contains() 两个方法。
elments() 方法继承自Hashtable的父类Dictionnary。elements() 方法用于返回此Hashtable中的value的枚举。
contains()方法判断该Hashtable是否包含传入的value。它的作用与containsValue()一致。事实上,contansValue() 就只是调用了一下contains() 方法。
4.LinkedHashMap
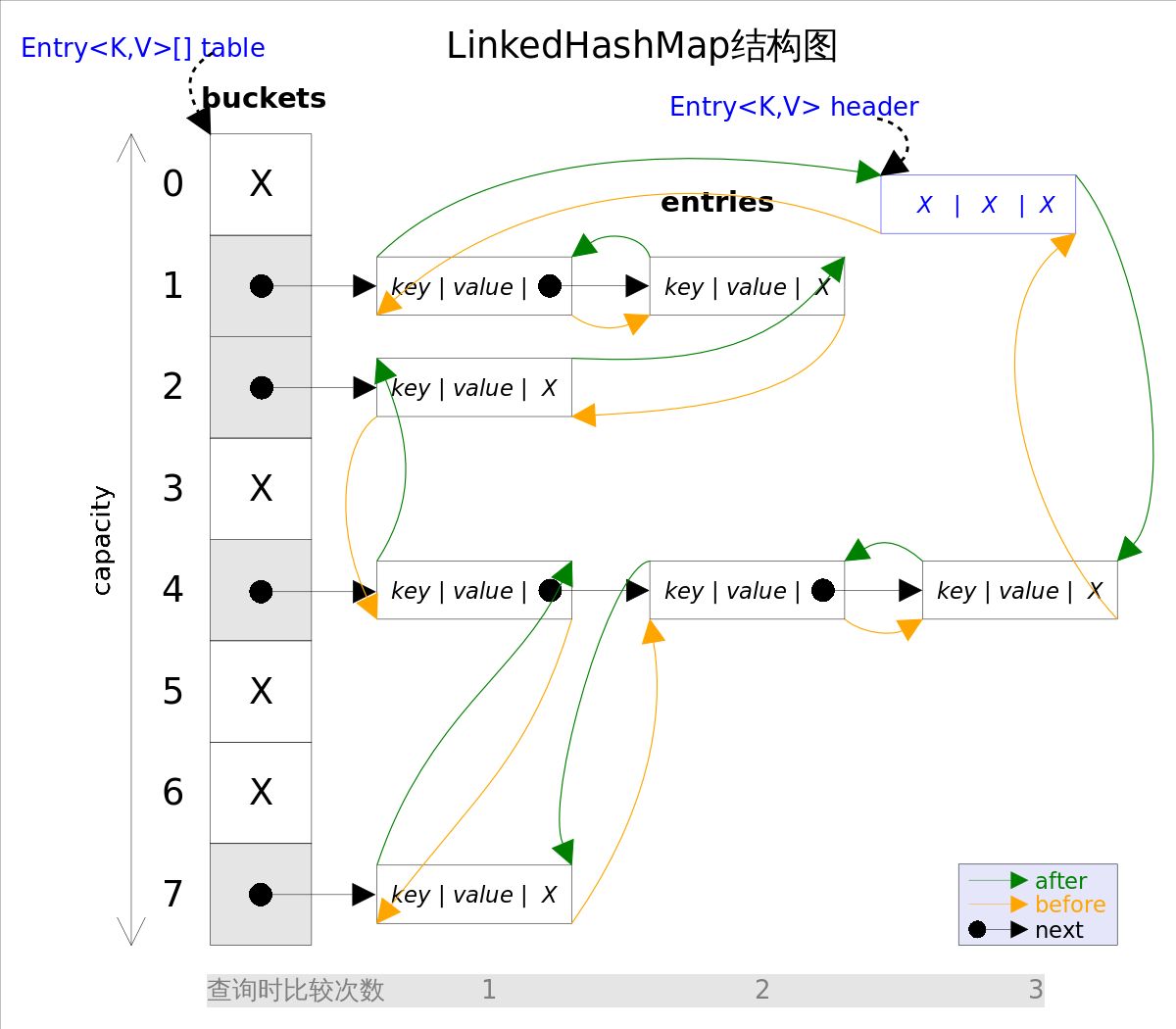
事实上LinkedHashMap是HashMap的直接子类,二者唯一的区别是LinkedHashMap在HashMap的基础上,采用双向链表(doubly-linked list)的形式将所有entry连接起来,这样是为保证元素的迭代顺序跟插入顺序相同。上图给出了LinkedHashMap的结构图,主体部分跟HashMap完全一样,多了header指向双向链表的头部(是一个哑元),该双向链表的迭代顺序就是entry的插入顺序。
除了可以保迭代历顺序,这种结构还有一个好处:迭代LinkedHashMap时不需要像HashMap那样遍历整个table,而只需要直接遍历header指向的双向链表即可,也就是说LinkedHashMap的迭代时间就只跟entry的个数相关,而跟table的大小无关。