前言
Hadoop是Apache软件基金会旗下的一个开源分布式计算平台。
- 大数据 基础概念
- 大数据 Centos基础
- 大数据 Shell基础
- 大数据 ZooKeeper
- 大数据 Hadoop介绍、配置与使用
- 大数据 Hadoop之HDFS
- 大数据 MapReduce
- 大数据 Hive
- 大数据 Yarn
- 大数据 MapReduce使用
- 大数据 Hadoop高可用HA
介绍
Hadoop是Apache软件基金会旗下的一个开源分布式计算平台。以Hadoop分布式文件系统HDFS(Hadoop Distributed File System,)和MapReduce(Google MapReduce的开源实现)为核心的Hadoop为用户提供了系统底层细节透明的分布式基础架构。HDFS的高容错性、高伸缩性等优点允许用户将Hadoop部署在低廉的硬件上,形成分布式系统;MapReduce分布式编程模型允许用户在不了解分布式系统底层细节的情况下开发并行应用程序。所以用户可以利用Hadoop轻松地组织计算机资源,从而搭建自己的分布式计算平台,并且可以充分利用集群的计算和存储能力,完成海量数据的处理。
Hadoop的优势
- 高可靠性。Hadoop按位存储和处理数据的能力值得人们信赖。
- 高扩展性。Hadoop是在可用的计算机集簇间分配数据完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
- 高效性。Hadoop能够在节点之间动态地移动数据,以保证各个节点的动态平衡,因此其处理速度非常快。
- 高容错性。Hadoop能够自动保存数据的多份副本,并且能够自动将失败的任务重新分配。
Hadoop的重要组件
HDFS和MapReduce是Hadoop的两大核心。
| 组件 | 说明 |
|---|---|
HDFS |
分布式文件系统 |
MapReduce |
分布式运算程序开发框架。MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。映射Map、化简Reduce的概念和它们的主要思想都是从函数式编程语言中借鉴而来的。 |
Hive |
基于大数据技术(文件系统+运算框架)的SQL数据仓库工具。它提供了一些用于对Hadoop文件中的数据集进行数据整理、特殊查询和分析存储的工具。 |
HBase |
基于Hadoop的分布式海量数据库。HBase是一个分布式的、面向列的开源数据库,该技术来源于Google论文《Bigtable:一个结构化数据的分布式存储系统》。HBase主要用于需要随机访问、实时读写的大数据Big Data。 |
ZooKeeper |
分布式协调服务基础组件。ZooKeeper是一个为分布式应用所设计的开源协调服务。它主要为用户提供同步、配置管理、分组和命名等服务,减轻分布式应用程序所承担的协调任务。 |
Mahout |
基于mapreduce/spark/flink等分布式运算框架的机器学习算法库 |
Oozie |
工作流调度框架 |
Sqoop |
数据导入导出工具 |
Flume |
日志数据采集框架 |
Pig |
Pig是一个对大型数据集进行分析、评估的平台。Pig最突出的优势是它的结构能够经受住高度并行化的检验,这个特性使得它能够处理大型的数据集。 |
HDFS
介绍
HDFS采用了主从Master/Slave结构模型,一个HDFS集群是由一个NameNode和若干个DataNode组成的。其中NameNode作为主服务器,管理文件系统的命名空间和客户端对文件的访问操作;集群中的DataNode管理存储的数据。HDFS允许用户以文件的形式存储数据。从内部来看,文件被分成若干个数据块,而且这若干个数据块存放在一组DataNode上。NameNode执行文件系统的命名空间操作,比如打开、关闭、重命名文件或目录等,它也负责数据块到具体DataNode的映射。DataNode负责处理文件系统客户端的文件读写请求,并在NameNode的统一调度下进行数据块的创建、删除和复制工作。
NameNode是所有HDFS元数据的管理者,用户需要保存的数据不会经过NameNode,而是直接流向存储数据的DataNode。
HBase
| 角色 | 职责 |
|---|---|
| 主服务器 | 管理整个集群的所有域,监控每台服务器的运行情况。 |
| 域服务器 | 接受来自服务器的分配域,处理客户端的域读写请求并回写映射文件等。 |
| 客户端 | 查找用户域所在的域服务器地址信息。 |
MapReduce
介绍
MapReduce是一种并行编程模式,利用这种模式软件开发者可以轻松地编写出分布式并行程序。
MapReduce框架是由一个单独运行在主节点的JobTracker和运行在每个集群从节点的TaskTracker共同组成的。主节点负责调度构成一个作业的所有任务,这些任务分布在不同的从节点上。主节点监控它们的执行情况,并且重新执行之前失败的任务;从节点仅负责由主节点指派的任务。当一个Job被提交时,JobTracker接收到提交作业和其配置信息之后,就会将配置信息等分发给从节点,同时调度任务并监控TaskTracker的执行。
HDFS and MapReduce
HDFS和MapReduce共同组成了Hadoop分布式系统体系结构的核心。HDFS在集群上实现了分布式文件系统,MapReduce在集群上实现了分布式计算和任务处理。HDFS在MapReduce任务处理过程中提供了对文件操作和存储等的支持,MapReduce在HDFS的基础上实现了任务的分发、跟踪、执行等工作,并收集结果,二者相互作用,完成了Hadoop分布式集群的主要任务。
Hadoop应用
- 数据服务基础平台
- 用户画像
- 网站点击流日志数据挖掘
Hadoop配置
直接从搭建环境开始吧~
O(∩_∩)O哈哈~
免密登录访问
参见【大数据 zookeeper】——免密登录配置部分。
配置Java环境
参见【Linux安装常用软件】——
Ctrl+F搜索JDK关键字,按照对应教程配置环境。
同步时间
- 先下载同步工具:
yum install -y ntpdate - 同步网络时间:
ntpdate time.nist.gov - 调整硬件时间:
hwclock -w- 执行成功后, 查看系统硬件时间(不出意外的话,现在date和hwclock现实的时间均为internet时间)。
配置Hadoop
好啦,准备工作完成了,我们要开始搭建环境了。
O(∩_∩)O哈!
下载Hadoop
配置环境
- 解压
Hadoop:tar -zxvf hadoop-2.6.5.tar.gz - 移动到
opt:mv hadoop-2.6.5/ /opt/ - 改名:
mv hadoop-2.6.5 hadoop
Hadoop配置
目录结构说明
| 文件夹 | 说明 |
|---|---|
bin |
Hadoop的一些操作命令。 |
etc |
配置文件。 |
include |
语言本地库。 |
lib |
本地库。 |
libexec |
|
sbin |
系统管理启动的命令。 |
share |
文档和相关的jar包。 |
官方文档,建议一看:Apache Hadoop Document
hadoop-env.sh
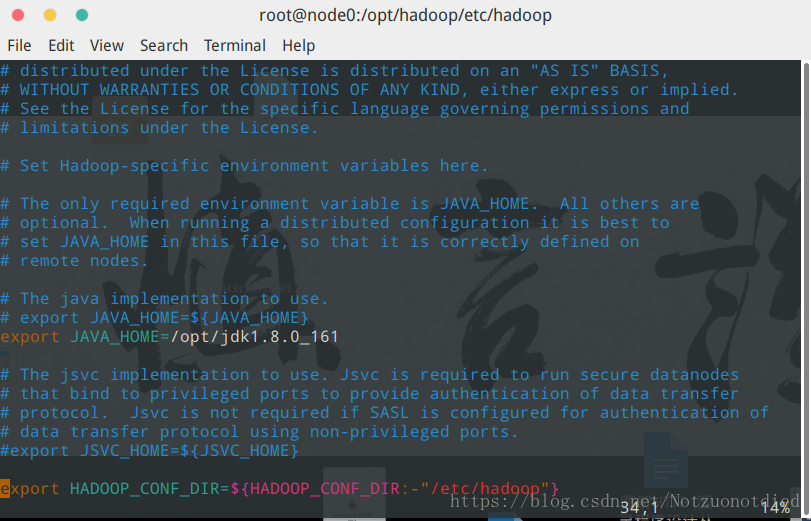
在./etc/hadoop/中,找到hadoop-env.sh,使用vim hadoop-env.sh打开,修改export JAVA_HOME={JAVA_HOME}为export JAVA_HOME=/opt/jdk1.8.0_161(注意,根据实际的JDK路径配置哈~)
core-site.xml
在<configuration></configuration>中增加以下内容:
fs.defaultFS指定Hadoop所使用的文件系统schema(URI),HDFS的老大NameNode的地址。- 说明:
node0需要在/etc/hosts中配置。 - 增加一个IP地址别名,后面配置使用。
vim /ect/hosts- 说明:IP地址 别名
192.168.80.8 node0192.168.80.9 node1192.168.80.10 node2192.168.80.11 node3
- 说明:
hadoop.tmp.dir指定hadoop运行时产生文件的存储目录。/opt/hadoopData目录需要自行创建。
<configuration>
<!-- 指定 HADOOP 所使用的文件系统 schema ( URI ),
HDFS 的老大( NameNode )的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node0:9000</value>
</property>
<!-- 指定 hadoop 运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoopData</value>
</property>
</configuration>
hdfs-site.xml
node0配置请看本文章的core-site.xml跳转中的内容。
<configuration>
<!-- 指定 HDFS 副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>node0:50090</value>
</property>
</configuration>
slaves
说明:这个是用于配置
DataNode结点的,在本教程中,我配置了三个DataNode,所以我的文件内容如下:
node1、node2、node3配置请看本文章的core-site.xml跳转中的内容。
node1
node2
node3
分发到其他结点
使用scp指令分发到其他几个结点。
node1、node2、node3配置请看本文章的core-site.xml跳转中的内容。
scp -r /opt/hadoop/ root@node1:/opt/
scp -r /opt/hadoop/ root@node2:/opt/
scp -r /opt/hadoop/ root@node3:/opt/
Hadoop使用
启动
- 启动方式
./sbin/start-all.sh。
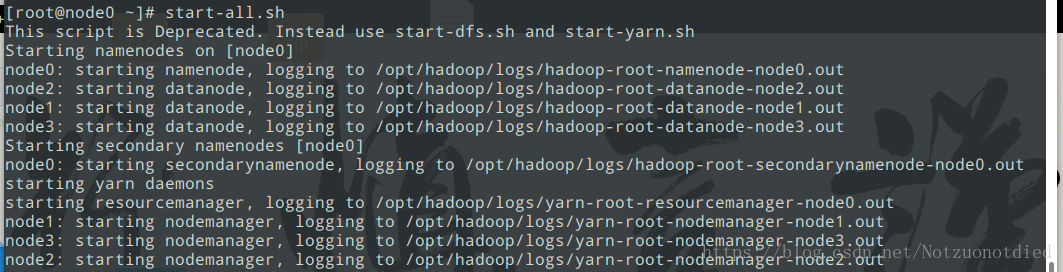
- 如果
yarn启动不了,就需要先关闭所有结点./sbin/stop-all.sh,再NameNode上执行./sbin/start-dfs.sh,在其中一个DataNode上执行./sbin/start-yarn.sh。
NameNode上jps结果:
6163 NameNode
6308 SecondaryNameNode
6510 Jps
DataNode上jps结果:
3763 ResourceManager
3859 NodeManager
3381 DataNode
3903 Jps
- 可以在浏览器上访问:http://node0:50070,可视化展示具体信息。
- 注意:
node0配置请看本文章的core-site.xml跳转中的内容。
- 注意:
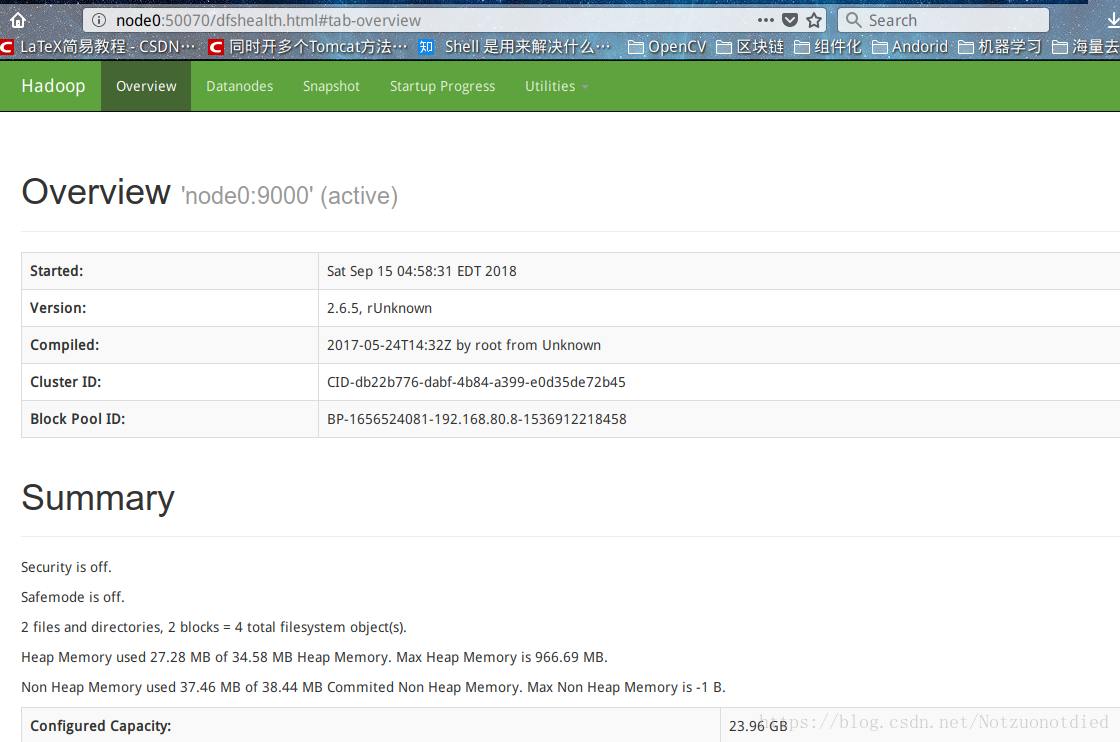
- 可以使用
jps【JDK自带的一个指令,位于./bin/jps】查看当前启动的java进程。
启动成功的
jps输出信息如下:
NameNode结点JPS信息
1747 Jps
1292 SecondaryNameNode
1149 NameNode
DataNode结点JPS信息
1376 Jps
1057 DataNode
Hadoop之HDFS
- 上传
jdk-8u161-linux-x64.tar.gz到根目录下:hadoop fs -put jdk-8u161-linux-x64.tar.gz /
- 打开http://node0:50070/explorer.html#/,在输入框中输入
/,可以查看根目录下的内容
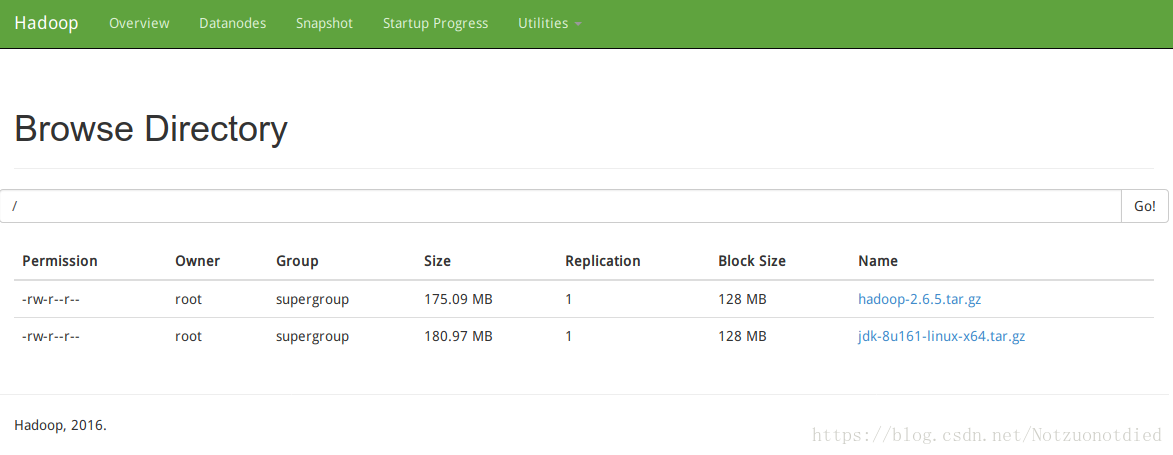
- 也可以去文章前面配置的存储路径
/opt/hadoopData查看。yum -y install treecd /opt/hadoopDatatree
在
DataNode node1里面tree出来的结果。
[root@node1 hadoopData]# tree
.
├── dfs
│ └── data
│ ├── current
│ │ ├── BP-1656524081-192.168.80.8-1536912218458
│ │ │ ├── current
│ │ │ │ ├── dfsUsed
│ │ │ │ ├── finalized
│ │ │ │ │ └── subdir0
│ │ │ │ │ └── subdir0
│ │ │ │ │ ├── blk_1073741825
│ │ │ │ │ └── blk_1073741825_1001.meta
│ │ │ │ ├── rbw
│ │ │ │ └── VERSION
│ │ │ ├── dncp_block_verification.log.curr
│ │ │ ├── dncp_block_verification.log.prev
│ │ │ └── tmp
│ │ └── VERSION
│ └── in_use.lock
└── nm-local-dir
├── filecache
├── nmPrivate
└── usercache
14 directories, 8 files
在
DataNode node3里面tree出来的结果。
[root@node3 hadoopData]# tree
.
├── dfs
│ └── data
│ ├── current
│ │ ├── BP-1656524081-192.168.80.8-1536912218458
│ │ │ ├── current
│ │ │ │ ├── dfsUsed
│ │ │ │ ├── finalized
│ │ │ │ │ └── subdir0
│ │ │ │ │ └── subdir0
│ │ │ │ │ ├── blk_1073741826
│ │ │ │ │ └── blk_1073741826_1002.meta
│ │ │ │ ├── rbw
│ │ │ │ └── VERSION
│ │ │ ├── dncp_block_verification.log.curr
│ │ │ ├── dncp_block_verification.log.prev
│ │ │ └── tmp
│ │ └── VERSION
│ └── in_use.lock
└── nm-local-dir
├── filecache
├── nmPrivate
└── usercache
14 directories, 8 files
存放原理
- node1情况:
[root@node1 subdir0]# ls -lh
total 130M
-rw-r--r-- 1 root root 128M Sep 14 05:23 blk_1073741825
-rw-r--r-- 1 root root 1.1M Sep 14 05:23 blk_1073741825_1001.meta
- node3情况:
[root@node3 subdir0]# ls -lh
total 54M
-rw-r--r-- 1 root root 53M Sep 14 05:23 blk_1073741826
-rw-r--r-- 1 root root 424K Sep 14 05:23 blk_1073741826_1002.meta
- 上传文件大小
[root@node0 ~]# ls -lh
total 181M
-rw-r--r-- 1 root root 181M Sep 15 07:16 jdk-8u161-linux-x64.tar.gz
我们可以看出
,拆分出来的块的大小相加刚好等于原来的大小。我们也可以验证一下,将分布在node1和node3的两个meta块直接用cat命令合并,再尝试解压即可。
- 将
node1的meta放到node0的/root/下。scp blk_1073741825 root@node0:/root/
- 将
node3的meta放到node0的/root/下。scp blk_1073741826 root@node0:/root/
- 在
node0中进行合并- 注意:块是连续的,所以要按照编号拼接。
cat blk_1073741825 > jdk.tar.gzcat blk_1073741826 >> jdk.tar.gzls -lh jdk.tar.gz-rw-r--r-- 1 root root 181M Sep 15 07:22 jdk.tar.gz
tar -zxvf jdk.tar.gz,解压成功,O(∩_∩)O哈哈~
- 在HDFS的存储中,所有的文件都是按照块的形式进行分隔的(块的大小是可以配置的。)
Hadoop指令
- 查看根目录下的内容
hadoop fs -ls 路径
- 上传文件
hadoop fs -put 文件 路径
- 查看文件内容
hadoop fs -cat 存储的文件的路径及名称hadoop fs -cat /a.txt
- 下载文件
hadoop fs -get 存储的文件的路径及名称 下载到指定路径hadoop fs -get /jdk-8u161-linux-x64.tar.gz /tmp
- 在
HDFS中创建文件夹hadoop fs -mkdir -p /hello/world
Hadoop示例
- 创建数据文件夹
hadoop fs -mkdir -p /data/input
- 创建文件夹
hadoop fs -mkdir -p /data/input
- 上传文件
hadoop fs -put novel.txt /data/input
- 执行
jarcd /opt/hadoop/share/hadoop/mapreduce/hadoop jar hadoop-mapreduce-examples-2.6.5.jar wordcount /data/input /data/output
执行结果
- 执行成功将会输出以下信息:
18/09/15 08:33:59 INFO client.RMProxy: Connecting to ResourceManager at node1/192.168.80.9:8032
18/09/15 08:34:02 INFO input.FileInputFormat: Total input paths to process : 1
18/09/15 08:34:03 INFO mapreduce.JobSubmitter: number of splits:1
18/09/15 08:34:04 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1537014830845_0001
18/09/15 08:34:05 INFO impl.YarnClientImpl: Submitted application application_1537014830845_0001
18/09/15 08:34:05 INFO mapreduce.Job: The url to track the job: http://node1:8088/proxy/application_1537014830845_0001/
18/09/15 08:34:05 INFO mapreduce.Job: Running job: job_1537014830845_0001
18/09/15 08:34:30 INFO mapreduce.Job: Job job_1537014830845_0001 running in uber mode : false
18/09/15 08:34:30 INFO mapreduce.Job: map 0% reduce 0%
18/09/15 08:34:50 INFO mapreduce.Job: map 100% reduce 0%
18/09/15 08:35:04 INFO mapreduce.Job: map 100% reduce 100%
18/09/15 08:35:05 INFO mapreduce.Job: Job job_1537014830845_0001 completed successfully
18/09/15 08:35:05 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=5172
FILE: Number of bytes written=224841
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=5209
HDFS: Number of bytes written=5118
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=17907
Total time spent by all reduces in occupied slots (ms)=10738
Total time spent by all map tasks (ms)=17907
Total time spent by all reduce tasks (ms)=10738
Total vcore-milliseconds taken by all map tasks=17907
Total vcore-milliseconds taken by all reduce tasks=10738
Total megabyte-milliseconds taken by all map tasks=18336768
Total megabyte-milliseconds taken by all reduce tasks=10995712
Map-Reduce Framework
Map input records=6
Map output records=6
Map output bytes=5142
Map output materialized bytes=5172
Input split bytes=103
Combine input records=6
Combine output records=6
Reduce input groups=6
Reduce shuffle bytes=5172
Reduce input records=6
Reduce output records=6
Spilled Records=12
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=223
CPU time spent (ms)=2260
Physical memory (bytes) snapshot=235151360
Virtual memory (bytes) snapshot=4155752448
Total committed heap usage (bytes)=136302592
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=5106
File Output Format Counters
Bytes Written=5118
ResourceManage启动失败将会出现以下错误:
18/09/15 08:29:09 INFO client.RMProxy: Connecting to ResourceManager at node1/192.168.80.9:8032
18/09/15 08:29:11 INFO ipc.Client: Retrying connect to server: node1/192.168.80.9:8032. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
- 解决方案:
- 在
NameNode结点上./sbin/stop-all.sh - 然后在
NameNode上启动./sbin/start-dfs.sh - 在任意一个
DataNode上启动./sbin/start-yarn.sh。
- 在
启动成功的
jps输出信息如下:
NameNode结点JPS信息
1747 Jps
1292 SecondaryNameNode
1149 NameNode
DataNode结点JPS信息
1376 Jps
1057 DataNode
执行结果查看
- 使用命令查看输出的内容
hadoop fs -ls /data/output/
[root@node0 mapreduce]# hadoop fs -ls /data/output/
Found 2 items
-rw-r--r-- 1 root supergroup 0 2018-09-15 12:16 /data/output/_SUCCESS
-rw-r--r-- 1 root supergroup 1481 2018-09-15 12:16 /data/output/part-r-00000
- 查看文本内容
hadoop fs -cat /data/output/part-r-00000
Always 1
Dream 1
Have 1
...省略
附录
- 《Hadoop实战(第2版)》陆嘉恒著
- Hadoop架构