1. shallow NN 浅层神经网络

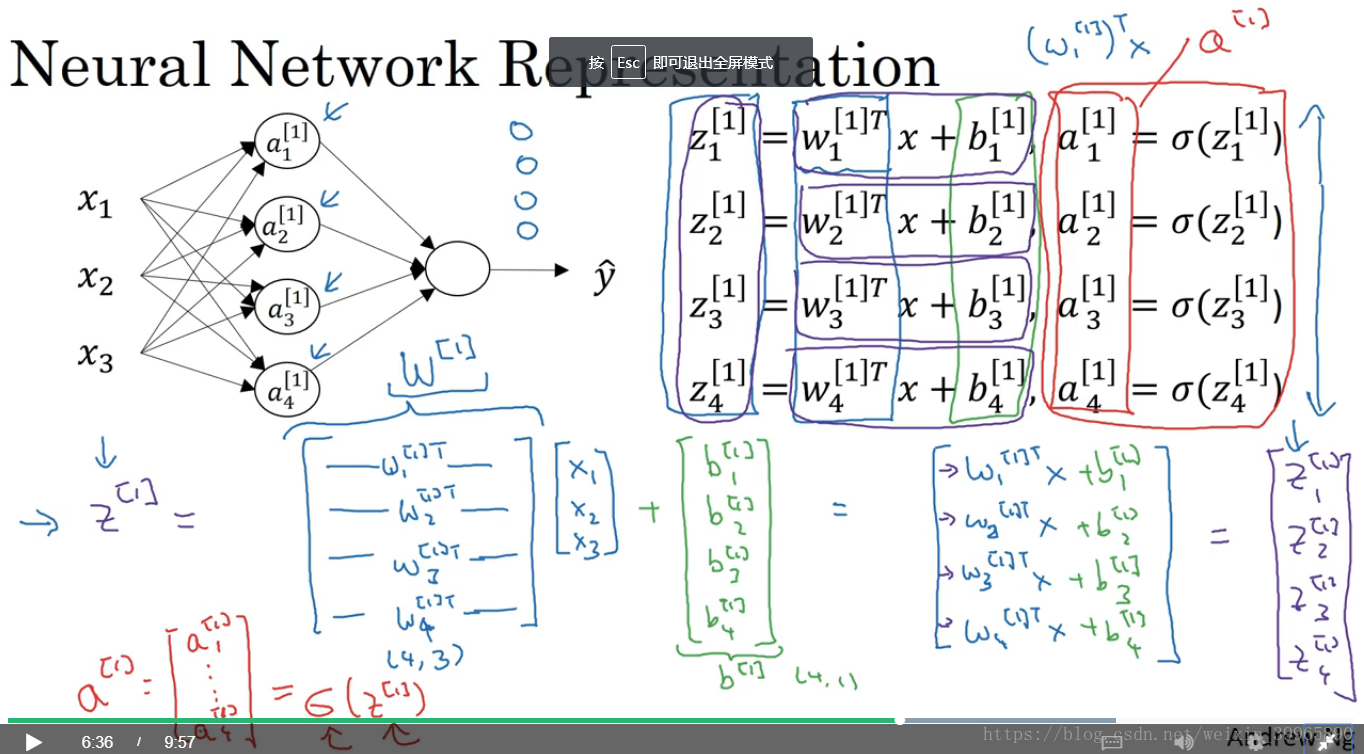
2. 为什么需要activation function?
如下图所示,如果不用激活函数,那么我们一直都在做线性运算,对于复杂问题没有意义。linear 其实也算一类激活函数,但是一般只用在机器学习的回归问题,例如预测房价等。
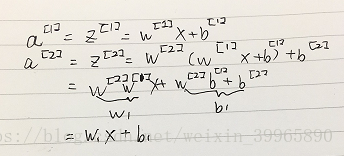
3. activation function激活函数的选取:
tanh 基本上任何时候都比sigmoid 效果好,因为它使得结果均值趋近于0,便于下一层的计算。除非是binary classification,y是在[0,1]之间,否则永远不要用sigmoid。因为tanh好得多。
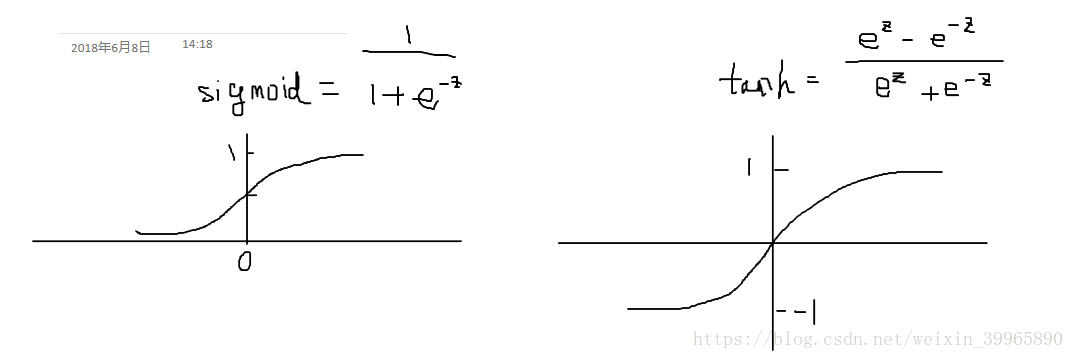
除此之外,还有ReLu, 上一part说过。在别的算法中,当不知道用什么激活函数的时候,吴恩达老师往往会选择ReLu. 但是对于NN, sigmoid和tanh往往是更好的选择,可以让NN很快跑完。还有Leaky ReLu, 0.01那个值可变。

4. 深度学习中因为可调节的参数太多了,所以往往会造成很多不确定性,除此之外还要结合实际数据类型等等。如果不确定,最好的办法就是try them all。
5. NN 的 back propagation(激活函数微分)
sigmoid和tanh的求导:

然后是ReLU和leaky ReLU的:

6. NN的gradient descent:


7. 初始化为0不可行(结果会让每层unit一样),需要random initialization. 因为我们有激活函数,所以并不希望初始值过大影响结果。对于shallow NN,都乘个0.01什么的都是可以接受的。但是对于deep NN, 就需要给初始参数乘不同的常数了。
8. 向量

9. 什么是深度神经网络?
shallow和deep的概念是相对的,指hidden layer较多的神经网络。big 和 small也是相对的,指units较多和较少。
10. matrix dimension是个重点,一定不能弄错。因为我们要用到for loop做前馈。
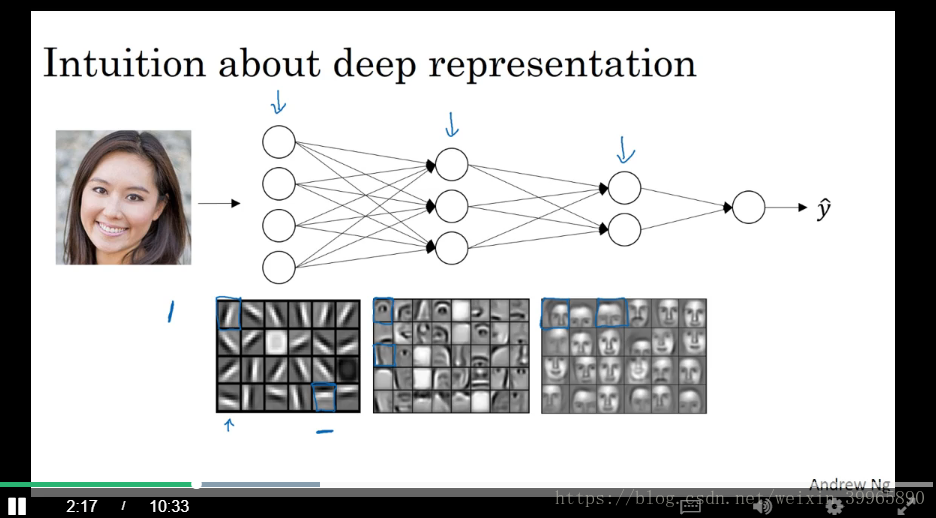
11. 为什么深度NN在图像识别上效果很好呢?
如下图所示,我们需要识别人脸,deep NN能够帮我们更好分工。第一层用于鉴别图像的边缘,第二层用于识别眼睛、鼻子、嘴巴,第三层将识别到的东西组合在一起,最后输出我们想要的面部。这一过程在CNN中更加有意义。大致过程就是让前面的层学习比较低级的feature,后面的层进行高级处理。深度神经网络的工作就比较像人脑了,从边缘开始识别,然后慢慢建立系统检测更复杂的事物。
12. 除了图像、语音识别,deep NN在电子电路的门运算中也比shallow更有效。
13. 但是deep learning这个概念已经被滥用了,不再单指有许多隐藏层的NN;deep NN也常常被滥用(但我们依然需要很深的NN),隐藏层太多,overfit严重。
14. 对于deep NN, 我们需要有block意识来计算forward和back propagation:
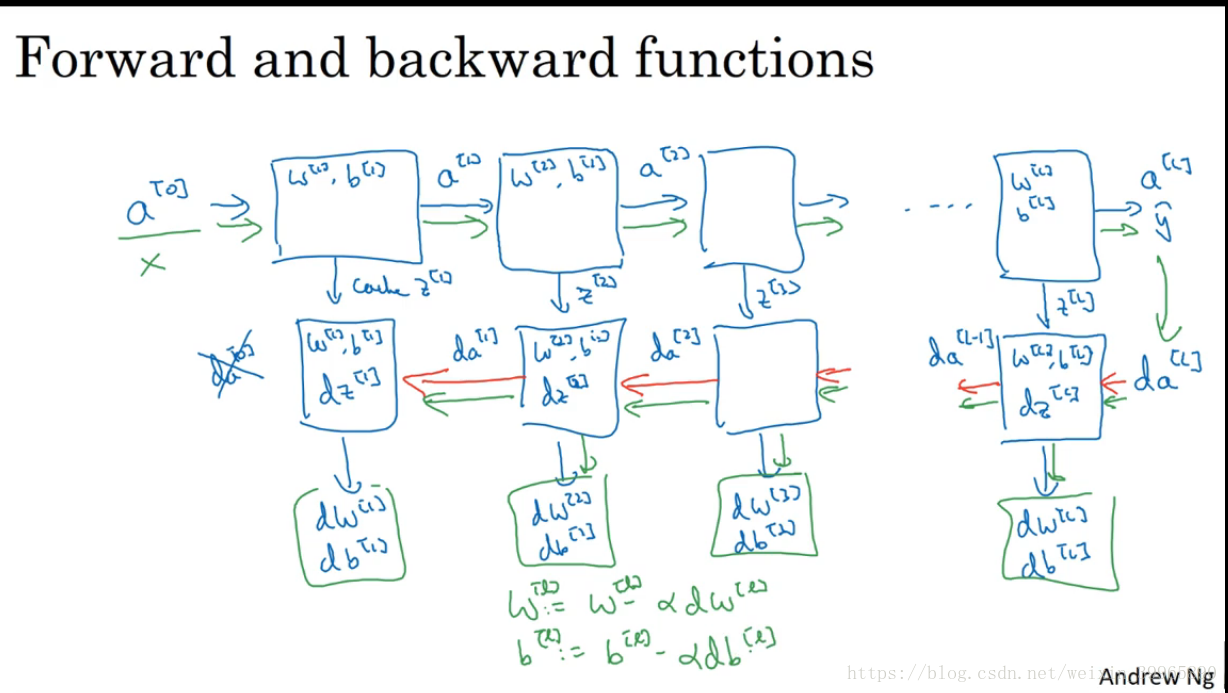

15. parameters vs. hyperparameters
parameters: W, b
hyperparameters: learning rate, iteration numbers, hidden layers, hidden units, choices of activation functions
hyperparameters control parameters, so we call them hyper~
python 代码:
1. keepdims = True, keepdims主要用于保持矩阵的二维特性
>>> import numpy as np
>>> a = np.array([[1,2],[3,4]])
>>> a
array([[1, 2],
[3, 4]])
>>> b = np.sum(a, axis = 1, keepdims = True)
>>> c = np.sum(a, axis = 1)
>>> b
array([[3],
[7]])
>>> c
array([3, 7])2. 矩阵运算
np.dot()是矩阵乘法
np.multiply()与*同,element-wise 元素相乘