第一周 机器学习策略_1
这一门课主要介绍了在具体项目实践中会遇到的一些问题以及采取的策略。所截取的图片依然来源于吴恩达老师的相关视频资源。
1. 正交化(Orthogonalization)

Andrew建议机器学习的调参过程应保持正交化。上图所示的机器学习的4个流程,每一步的调试方式举例见蓝色字体。对于每一步的处理应尽量不影响其他步骤。当然你也可以采用例如early stopping这种非正交化的调参方式(因为其一边增加训练误差,一边减少验证误差),但是尽量还是采用正交化的方式进行处理。
2.设置单实数评价指标的目的是为了更有效率地进行决策。例如评价一个二分类器时,存在着查准率和查全率两个指标或者多个指标时,很难判断哪一个分类器更好,此时若采用F1分数(查准率和查全率的调和平均数)这样一个单一实数指标进行判断,效率就很高了。还有一种情况是,如果你需要考虑到多个指标,这在实际应用中也常常出现,那么你可以选择设置一个优化指标,以及多个满足指标来进行筛选。
3. 训练\验证\测试集的划分。应满足验证集和测试集来自于同一个分布(全部数据打散然后随机分配)。百万级别大数据,98-1-1,这个划分在上一门课也提到过。
4. 贝叶斯最优误差:理论可达到的最优误差。在多数情况下,人类能达到的误差极限约等于贝叶斯误差。常利用人类误差近似代替贝叶斯最优误差
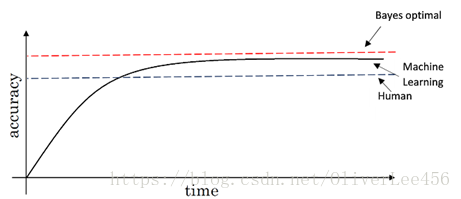
可避免偏差:贝叶斯最优误差和训练误差的差值。
判断方差大小的一个指标:验证误差和训练误差的差值。
二者的权衡,可以理解为偏差与方差的权衡。
感觉这些和之前提到的有些重复,不同之处在于,Andrew在强调,在具体项目之中,常用作比较的基准是人类的误差而不是贝叶斯最优误差。
5. human-level performance 人类水平误差近似估计贝叶斯误差。合理的选择人类水平误差去替代贝叶斯误差,其实是提供了一个判别偏差与方差的基准。计算机在结构化数据方面已经做得比人类更好了,但是人类更擅长于自然感知数据(图像、音频、文本),在这些方面,计算机要超越人类还需要一段路。因此,在许多方面使用人类对于误差的表现来近似代替贝叶斯最优误差也是合理的。
第二周 机器学习策略_2
还是继续讲述在具体项目中会遇到的一些问题,以及一些解决的思路和策略。
1. 误差分析:通过给分类错误的样本进行统计,分析错误的原因以及更占的比重,选择接下来改善的思路。
2. 在训练集中,深度学习对于随机误差(但对于系统性误差就没有那么好的鲁棒性了)有着很强的鲁棒性,有时候对于少量随机标记错误的标签不进行更改在最后的结果上也不会存在较大的问题。如果在dev集上也存在标记错误的情况,这时,将其纳入误差分析中,分析其是否值得花时间去改进。这里Andrew给出了三点建议:
(1) 当对dev集做修改时,同样也应该对test集做修改,这样保证二者来源于同一个分布。
(2)不光检验错误的例子,也应该检验正确的例子。
(3)训练集和验证集/测试集如果在分布上有一点差异是可以接受的,但是必须保证验证集和测试集来源于同一个分布。
3. 快速建立相对简单的第一个原型系统,然后开始迭代。
4. 训练集和开发集/测试集可能会来自于不同的分布,但是这也没有关系。明确项目的目标来分配数据,而不是一味的均分。
5. 当训练集和开发集来自于不同分布,在判断偏差/方差上会有一些不同。具体方法是从训练集中随机抽取一个数据集,叫做训练-开发集(train-dev set)。这个数据集不参与训练,但是参与验证。通过这个数据集的辅助判断,帮助决策。具体参见下图:

人类水平误差约等于贝叶斯误差。可避免误差误差衡量训练集误差和贝叶斯误差的差异;训练-开发误差和训练误差当做方差的参照;开发误差和训练-开发误差的差异衡量数据不匹配的程度(这个还没有系统的方式解决);测试误差和开发误差的差异代表的是开发误差的过拟合程度(若开发集过拟合了,最简单的方式便是增加开发集数据量来解决)。通过分析这些差异,帮助更好的找到问题。
6. 正如上一点提到的数据不匹配的问题,虽然没有系统的方式解决,但是仍然有一些思路给以启发:

有一种方式便是人工合成数据来解决数据不匹配的问题。这是一种很好的办法,但是要注意在人工合成数据的过程中,避免由于选择特定的模式合成数据而导致的神经网络对于这部分数据造成的过拟合问题。
7.迁移学习:一个简单的例子。已经训练好了一个图像识别网络,这时候可以把这个网络应用到放射图像的识别中。此时简单的做法便是在原有网络的基础上(此前的操作也称为预训练,pre-trainning),将网络的最后一层进行修改并初始化权重为0,再利用放射图像进行训练。这个操作也称为微调(fine-tune)。迁移学习应用场景如下所示:

8. 在迁移学习中,涉及到多个任务的学习,但是任务的学习是串行的。并行的多任务学习,也称为多任务学习。多任务学习应用场景:

9. 端到端深度学习(end to end):需要大量的数据使网络表现良好。
