论文:Fully Convolutional Networks for Semantic Segmentation
一、语义分割
这部分主要参考:FCN
图像语义分割的意思就是机器自动分割并识别出图像中的内容,比如给出一个人骑摩托车的照片,机器判断后应当能够生成右侧图,红色标注为人,绿色是车(黑色表示back ground)。

图像的语义分割另外还有一种示例级别(instance level)的图像语义分割,该类问题不仅需要对不同语义物体进行图像分割,同时还要求对同一语义的不同个体进行分割(例如需要对图中出现的九把椅子的像素用不同颜色分别标示出来)。
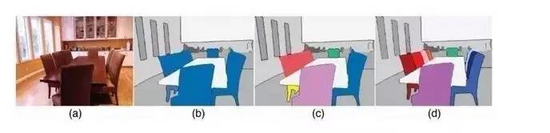
语义分割需要解决的一个问题是位置和语义的tension(翻译成矛盾感觉不太准确,或者均衡?),位置对应着局部信息,而语义对应着全局信息。
二、FCN简介
FCN是图像语义分割的开山之作,这是一篇发表在2015 CVPR上的一篇论文,拿到了当年的best paper honorable mention。
传统的基于CNN的语义分割方法:为了对一个像素分类,使用该像素周围的一个图像块作为CNN的输入用于训练和预测。这种方法有几个缺点:一是存储开销很大。例如对每个像素使用的图像块的大小为15x15,然后不断滑动窗口,每次滑动的窗口给CNN进行判别分类,因此则所需的存储空间根据滑动窗口的次数和大小急剧上升。二是计算效率低下。相邻的像素块基本上是重复的,针对每个像素块逐个计算卷积,这种计算也有很大程度上的重复。三是像素块大小的限制了感知区域的大小。通常像素块的大小比整幅图像的大小小很多,只能提取一些局部的特征,从而导致分类的性能受到限制。
本文提出了全卷积网络(FCN)的概念,针对语义分割训练一个端到端,点对点的网络,达到了state-of-the-art。这是第一次训练端到端的FCN 用于像素级的预测;也是第一次用监督预训练的方法训练分割网络。这种FCN能够从任意尺寸的输入图片中得到一个密集型的输出。相比于其它分割网络,这种方法十分高效,不用使用一些复杂的运算,比如patchwise traing。这种方法也没有采用常见分割网络所使用的一些预处理和后处理方法,比如超像素,proposals以及条件随机场等。
三、FCN架构
FCN网络模型如何实现的:
- 将一个用于分类的卷积网络(比如VGG16)转换为全卷积的,也就是将全连接层进行卷积化,得到一个热图(heatmap)
- 通过上采样,或者说反卷积(deconvolution)将热图恢复到输入图片的尺寸得到pixelwise predictions。然后以最大概率为依据逐个像素进行分类。loss就是所有像素上的softmax loss之和。
- 添加skip connections来将浅层精细的语义信息和深层粗糙的语义信息融合起来。也就是解决上面提到的“位置和语义的tension”
下面就围绕这三部分进行详细的解释。
1、分类器的卷积化
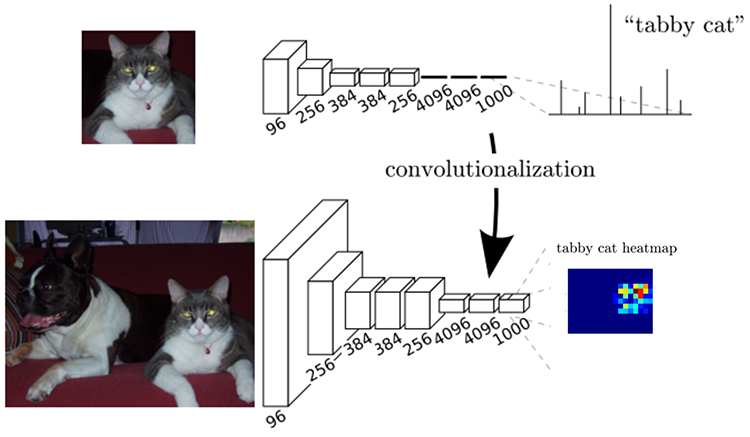
先看论文中给的这张图。上面是一个分类网络(有些像VGG16,但是每一层的通道数对应不上,不太重要不管它),其中画实线的部分是两个输出维度为4096的全连接层接一个输出维度为1000的全连接层,最后接softmax层,得到1000类各自的概率。举例说明:
假设一个卷积神经网络的固定输入是 224x224x3 的图像,一系列的卷积层和下采样层将图像数据变为尺寸为 7x7x512 的特征图。
最后一个卷积层输出(7,7,512)特征图 FC4096 长度为4096的向量 FC4096 长度为4096的向量 FC1000 长度为1000的向量 softmax 预测结果
下面是将三个全连接层进行卷积化后的全卷积网络。
如何进行卷积化的呢?先将最后的分类层去掉,再将全连接层用同样维度的覆盖整个输入区域的卷积代替,继续举例说明:
假设输入图片还是 224x224x3 的图像
最后一个卷积层输出(7,7,512)特征图 (4096,7,7)conv (1,1,4096)特征图 (4096,1,1)conv (1,1,4096)特征图 (1000,1,1)conv(1,1,1000) 这里最后的softmax层要去掉。
假设输入图片是 500x500x3 的图像
最后一个卷积层输出(22,22,512)特征图 (4096,7,7)conv (16,16,4096)特征图 (4096,1,1)conv (16,16,4096)特征图 (1000,1,1)conv(16,16,1000) 热图 。可看下图(根据VGG16绘制)
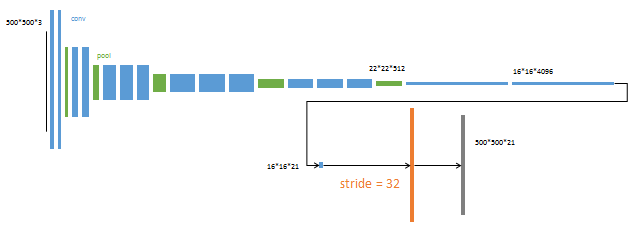
上面这张图前面部分作者说是基于AlexNet的,但看网络结构分明是VGG16,但对于VGG16,500*500的输入最后一个池化层的输出不可能是22*22,AlexNet才是。所以前半部分不管它。弄懂全连接层怎么转换为卷积层的就好。具体来说:
对于VGG16:
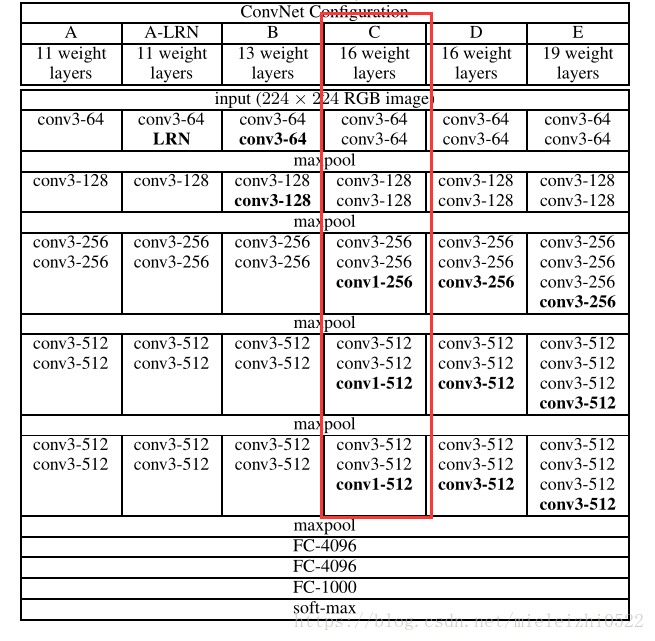
将第一个全连接层转换为4096个7*7的卷积层;其它的全连接层转换为1*1的卷积层。
对于AlexNet:

将第一个全连接层转换为2048个13*13的卷积层,其余全连接层也是1*1。论文中第3页提到的“500*500的输入图片得到10*10的输出可以验证这一点”:500*500----->((5个卷积层,3个最大池化层)22*22-------->(13*13的卷积层)10*10
进行这样转化的意义:
1、保留了二维信息,可以适应不同尺寸的输入图片。全连接层先是把一个多维的特征图拉伸成了一个向量,再进行全连接的操作,这样就丧失了原特征图的二维信息。
2、节省了计算。卷积操作“权重共享”的特性
2、上采样(去卷积)

通过上采样实现从heatmap到pixelwise prediction的转换。
那么上采样是如何实现的呢?通过增添去卷积层实现的。
最后一层的去卷积层固定为双线性插值,这种方法不涉及可训练参数,这也是为什么该模型精度不太好的原因
中间层的去卷积层采用双线性插值进行初始化,但是它是可训练的。
PS:这里的 最后一层的去卷积层 和 中间层的去卷积层 含义看这张图

图中的2*conv7,4*conv指的就是中间层的去卷积,而最后的32*,8*,16*指的 最后一层的去卷积层。
————————————————————————————————————————————————
下面稍微仔细讲一下 。参考 FCN于反卷积(Deconvolution)、上采样(UpSampling)
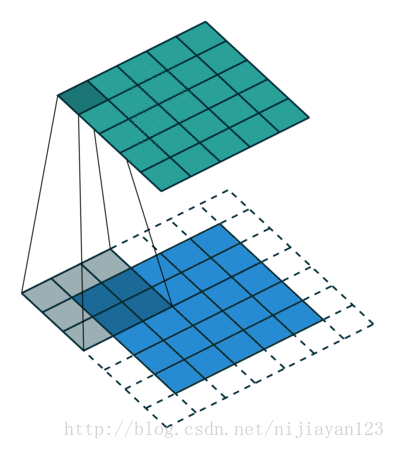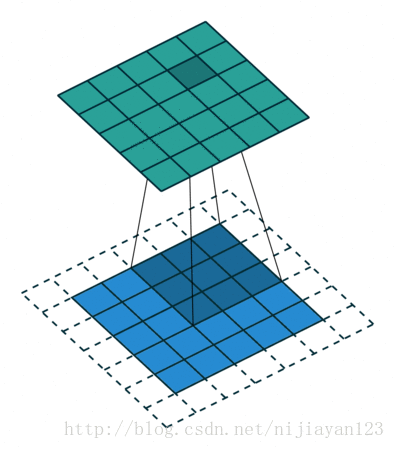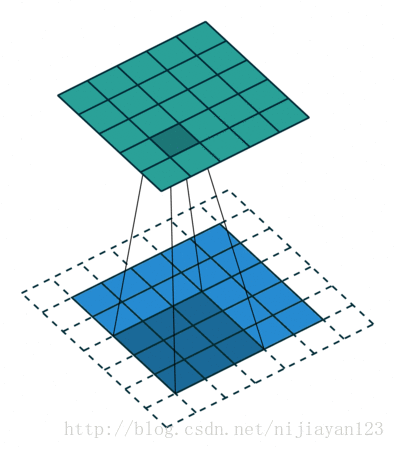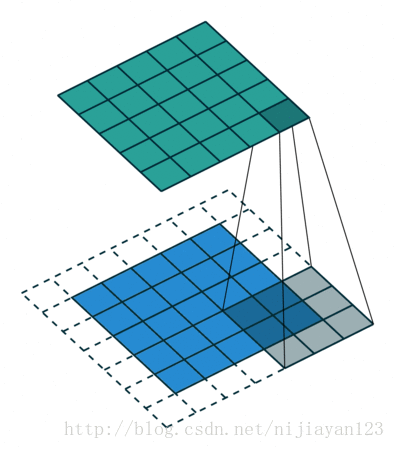
说这个问题之前先说一下卷积操作,卷积操作其实可以分成三种操作
1、valid
滑动步长为S,图片大小为N1xN1,卷积核大小为N2xN2,卷积后图像大小:(N1-N2)/S+1 x (N1-N2)/S+1
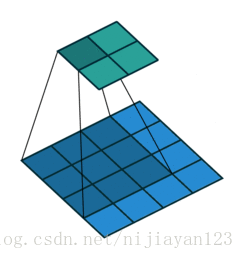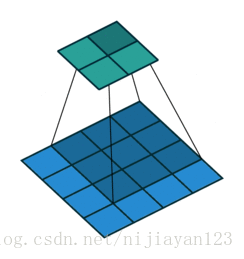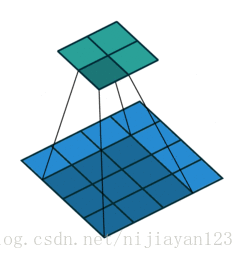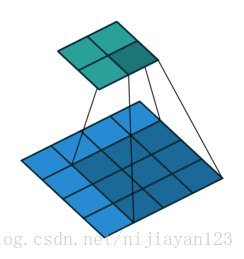
2、 full
滑动步长为1,图片大小为N1xN1,卷积核大小为N2xN2,卷积后图像大小:N1+N2-1 x N1+N2-1 如下图
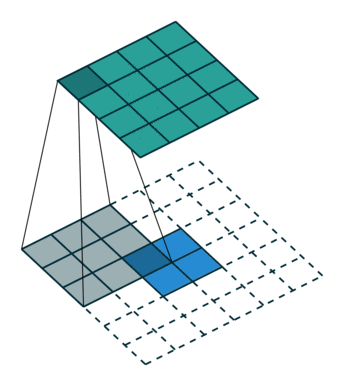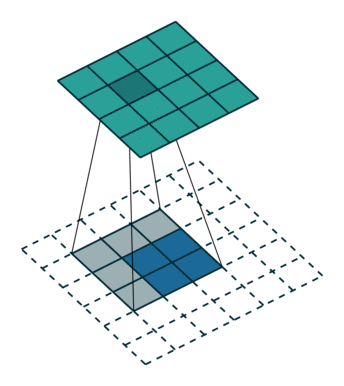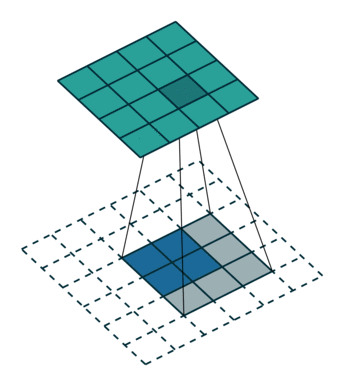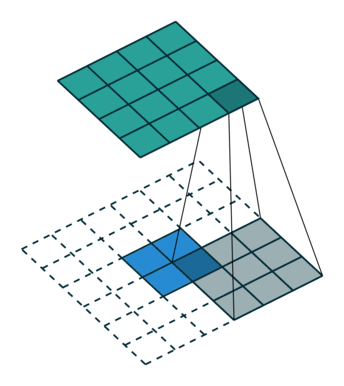
图中蓝色为原图像,白色为对应卷积所增加的padding,通常全部为0,绿色是卷积后图片。图6的卷积的滑动是从卷积核右下角与图片左上角重叠开始进行卷积,滑动步长为1,卷积核的中心元素对应卷积后图像的像素点。可以看到卷积后的图像是4X4,比原图2X2大了,我们还记1维卷积大小是n1+n2-1,这里原图是2X2,卷积核3X3,卷积后结果是4X4,与一维完全对应起来了。其实这才是完整的卷积计算,其他比它小的卷积结果都是省去了部分像素的卷积。下面是WIKI对应图像卷积后多出部分的解释:
Kernel convolution usually requires values from pixels outside of the image boundaries. There are a variety of methods for handling image edges. padding的设置方法(其实这里的full卷积就是常说的反卷积的一种)
论文中采用的去卷积操作应该就是双线性插值进行初始化,然后再进行全卷积操作。
3、same 操作
滑动步长为1,图片大小为N1xN1,卷积核大小为N2xN2,卷积后图像大小:N1xN1 如下图所示
关于反卷积操作还有更多的内容有待学习:比如先反池化再进行卷积的的反卷积是怎么回事。
反卷积是怎么训练的?
下一篇论文阅读笔记详细写这个。
3、skips连接(deep jet)
作用:连接底层信息到高层信息,从而提升精度。
具体操作:以FCN-16s为例,FCN-32s可据此类推。
- 先将pool4 层后面接一个1*1conv层来修改特征图的通道数以匹配conv7输出的的通道数(21)。
- 将conv7的输出图进行2倍的上采样(上文提到的全卷积操作),若尺寸不匹配会进行crop的操作。然后与第一步的操作求和。
- 对求和结果再进行16倍的上采样,这里采用双线性插值。
效果:

问题:论文中提到没有再进一步地叠加原因,我还没有看明白……
四、FCN训练
网络采用了带监督的预训练方法进行训练。可参考:FCN的学习和理解
训练过程分为四个阶段,也体现了作者的设计思路,值得研究。
第1阶段
以经典的分类网络为初始化。最后两级是全连接(红色),参数弃去不用。
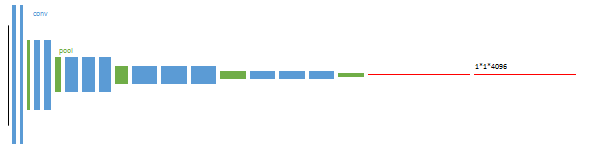
第2阶段
从特征小图(16*16*4096)预测分割小图(16*16*21),之后直接升采样为大图。
反卷积(橙色)的步长为32,这个网络称为FCN-32s。
这一阶段使用单GPU训练约需3天。
第3阶段
升采样分为两次完成(橙色×2)。
在第二次升采样前,把第4个pooling层(绿色)的预测结果(蓝色)融合进来。使用跳级结构提升精确性。
第二次反卷积步长为16,这个网络称为FCN-16s。
这一阶段使用单GPU训练约需1天。
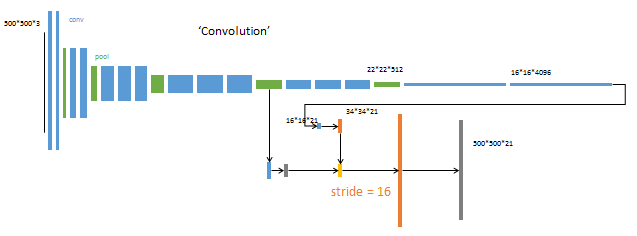
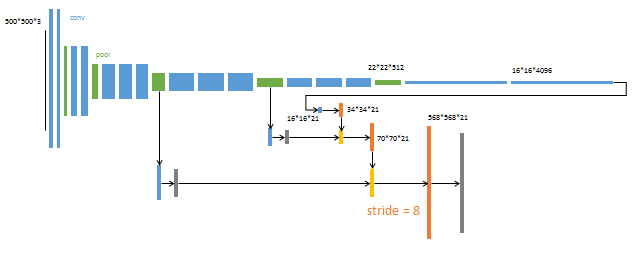
第4阶段
升采样分为三次完成(橙色×3)。
进一步融合了第3个pooling层的预测结果。
第三次反卷积步长为8,记为FCN-8s。
这一阶段使用单GPU训练约需1天。
五、语义分割的评价指标

本文主要提出了四个用于语义分割或者场景解析的评价指标,分别是像素准确率PA,平均像素准确率MPA,平均交并比mIOU,带权重的交并比freuquency weighted IU。其中mIOU是最常用的一个评价指标。
PA:在一次迭代中(若采用minibatch就是一个batch_size),所有判断正确的像素个数除以所有像素的个数。
MPA:PA除以类别的个数。
mIOU:顾名思义,针对二元分割问题,图中橙色部分像素的个数除以红橙黄三个部分像素的总个数就是交并比IOU。对于多元分割,把各个类别的交并比加起来再除以总的类别个数就是mIOU。
freuquency weighted IU:添加了权重,具体的作用不清楚。

六、实验尝试
作者还做了很多实验来尝试提升网络性能,很多都没有效果。这部分挺有意思的。
- 作者尝试了减少最后一层的池化层的步长到1,可是这导致池化层后面的卷积层卷积核感受野很大。这样增大了计算量,这么大感受野的卷积核很难学习。作者也试过了用更小的过滤器来调整池化层上面的层,可是效果也不好。
- 作者也尝试了 shift and stitch trick,但是代价太大,性价比还不如层融合。得不偿失。
- 添加了一些训练数据,提升了mIOU
- 尝试了patch sampling,块抽样,发现相比于全图训练并没有带来更快地收敛。

- 尝试通过修改损失值的权重或者采样loss来实现平衡训练集(class balance),发现虽然数据集的类很不平衡,其中四分之三都是背景,但是类平衡并不能带来性能的提升。
- 作者还尝试了数据增强,也并没有带来显著地提升。
七、弊端
-
是得到的结果还是不够精细。进行8倍上采样虽然比32倍的效果好了很多,但是上采样的结果还是比较模糊和平滑,对图像中的细节不敏感。
-
是对各个像素进行分类,没有充分考虑像素与像素之间的关系。忽略了在通常的基于像素分类的分割方法中使用的空间规整(spatial regularization)步骤,缺乏空间一致性。
参考:全卷积网络 FCN 详解