Hadoop 之 HDFS 及安装
HDFS
推荐书籍 Hadoop 权威指南第四版 中文 PDF 网盘下载 免费 点击下载
概念
-
当数据集的大小超过一台独立的计算机的存储能力的时候,这个时候就有必要对文件进行分区(partiiton)存储在若干台计算集上。管理网络中跨多台计算机存储的文件系统,叫做分布式文件系统(Distribute FileSystem)。该系统架构于网络之上,势必会引入网络编程的复杂性,因此分布式文件系统比普通磁盘文件系统更为复杂,比如说:必须要容忍因为节点故障且不会引起数据丢失。
-
Hadoop 自带一个称为HDFS分布式文件系统(
Hadoop Distribute FileSuystem)。HDFS 以流式数据访问模式来存储超大文件,运行与商用硬件集群上。 -
超大文件:在这里指的是具有几百MB、几百GB、甚至几百TB大小的文件。
-
流式数据访问模式:一次写入,多次读取是最高效的设计模式。
-
低时间延迟的数据访问:要求低延迟的数据访问的应用,例如几十毫秒,不适合在HDFS上运行。(HDFS是为高吞吐量优化的,这可能会以提高时间延迟为代价)
-
大量小文件:
多用户写入,任意修改文件:HDFS中的文件写入只支持单写入者,而且写入者只以“追加”的方式在文件末尾写数据,不支持多个写入者,也不支持在任意位置修改数据。
HDFS的概念
- 数据块(block):默认128MB。
- namenode 和 datenode
- 块缓存:
- 联邦HDFS: viewfs://URI
存儲模型:字节
-
文件线性切割成块(Block):偏移量Offset(byte)(Block切割字符的下标)
-
Block分散存储在集群节点上
-
单一文件Block块大小一致,不同文件的Block块大小可以不一致。
Block可以设置副本数,副本(数据的可靠性。可用性)分散在集群不同的节点中。 -
副本数不可以超过节点数量 -
文件上传可以设置Block大小和副本数量
-
已上传的Block副本数可以调整,大小不变
-
只支持一次写入(append追加在文件末尾),多次读写,同一时刻只允许有一个写入者
架构模型
- 文件元数据MataData,文件数据
- (从)数据本身(Block数据)存储在DateNode:多节点
- (主)元数据(文件名、大小、块信息等)存储在namenode:单节点
- DataNode 和NameNode保持心跳,提交Block列表信息
- HdfsClient和NameNode交换元数据信息
- HdfsClient和DataNode交换Block数据

NameNode(NN)
- 基于内存存储:不会和磁盘发生交换
只存在内存中- 持久化(运行是单向落在磁盘中,重启的时候读回来,具体方法后面)
- NameNode主要功能
- 接收客户端的读写功能
- 收集DateNode汇报的Block信息
- NamoNode保存的metaData信息包括
- Block块列表(偏移量)(持久化存储的信息),位置信息(数据存储的位置)
- 副本的存储位置(由DataNode(心跳)上报)
- 文件大小,时间
- NameNode持久化
- NameNode的metadata信息会在启动会加载到内存
matadata存储到磁盘的名称为fsimage
Block块信息不会保存到fsimage
edits(editsLog)记录对metadata的操作日志
(合并fsimage 和 editsLog ,缩短集群恢复的时间)
DataNode(DN)
- 本地磁盘存储数据(Block),文件形式
同时存储Block的元数据信息
启动DN时会向NN汇报block信息
通过向NN发送心跳保持与其联系(3秒一次),如果NN十分钟没有收到DN的心跳,认为其已经lost,会copy其上的block到其他DN
SecondaryNameNode(SNN)(1.x)
- 它不是NN的备份(但是可以做备份),它的主要工作是帮助NN合并editslog,减少NN启动时间
- SNN执行合并时机
根据配置文件设置的时间间隔<fs.checkpoint.period>,默认3600秒
根据配置文件设置的edits log 大小,fs.checkpoint.size,默认大小64MB

Block的副本放置策略
- 第一个副本放置在上传文件的DN上,
- 第二个副本放置在与第一个副本不同的机架的节点上
- 第三个副本放置在与第二个副本相同的机架上不同节点上HDFS写流程
HDFS读流程
open–>getBlockLocationInfo–>read
HDFS安装
环境:CentOS-6.10-x86_64-minimal.iso
JDK:jdk-8u171-linux-x64.tar.gz
Hadoop:hadoop-2.6.0.tar.gz
1、首先安装上传下载功能,root 账号登陆后执行以下命令:
yum install -y lrzsz
2、mkdir -p /usr/local/java
3、cd /usr/local/java/
4、rz -e + Enter 选择路径下 jdk-8u171-linux-x64.tar.gz 或者 rz -be + Enter 选择路径下 jdk-8u171-linux-x64.tar.gz
5、tar -zxvf jdk-8u171-linux-x64.tar.gz
6、pwd (复制当前路径)
7、vim /etc/profile
8、JAVA_HOME=/usr/local/java/jdk1.8.0_181
JRE_HOME=/usr/local/java/jdk1.8.0_181/jre
CLASSPATH=.:$JAVA_HOME:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib:$JAVA_HOME/lib/dt.jar
PATH=$JAVA_HOME/bin:
export PATH JAVA_HOME CLASSPATH
9、 source /etc/profile
10、java -version 验证是否安装成功
-----------------------------华丽的分割线----------------------------
--------------------------Hadoop的伪分布式安装----------------------------
1、上传hadoop安装包
rz -e + enter 选择路径下 hadoop-2.6.0.tar.gz
2、 tar xf hadoop-2.6.0.tar.gz
3、 vim /etc/profile
HADOOP_HOME=/usr/local/hadoop-2.6.0
PATH=$JAVA_HOME/bin:$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
4、 免秘钥
ssh -keygen -t dsa -P '' -f ~/.ssh/id_dsa.pub
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
scp ~/.ssh/authorized_keys root@node2:`pwd`(分发到其他节点)
5、 在hadoop配置文件中二次配置JAVA_HOME(远程调用,不会调用/etc/profile 配置文件)
配置/usr/local/hadoop-2.6.0/etc/hadoop/ 下所有evn.sh结尾的文件
export JAVA_HOME=/usr/local/java/jdk1.8.0_181/
6、 vim /usr/local/hadoop-2.6.0/etc/hadoop/core-site.xml:
<!--指定NN启动位置-->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
<!--localhost 换成当前节点名称: node1-->
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/var/hadoop/local</value>
<!--不存在则自己创建-->
</property>
</configuration>
7、 vim /usr/local/hadoop-2.6.0/etc/hadoop/hdfs-site.xml
<!--副本数量不可超过节点数,不写默认3个,会一直报错-->
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.secondary.address</name>
<value>node1:50090</value>
</property>
</configuration>
8、 core-site.xml
hadoop.tmp.dir 存储临时文件,系统空间不足会自己删除
9、 hdfs-site.xml
dfs.namenode.name.dir 默认file://${hadoop.tmp.dir}/dfs/name
dfs.datanode.data.dir 默认file://${hadoop.tmp.dir}/dfs/data
这样就会出现问题,所以要更改core-site.xml中的hadoop.tmp.dir文件存储路径
10、 vim slaves
node1
11、 格式化文件系统
$bin/hdfs namenode -format <!--****format 不是formate****-->
12、 启动hdfs
$sbin/ start-dfs.sh
13、 hdfs集群web页面
node1:50070
14、 常用命令
hdfs + enter
hdfs dfs + enter
hdfs dfs -ls + hdfs 路径
hdfs dfs -put + 本地文件路径 + hdfs 路径
hdfs dfs -get + hdfs 路径
hdfs dfs -cat + hdfs 路径
hdfs dfs -mkdir /user(家目录)/root(用户)/这后面才是你自己的目录
hdfs dfs -tail + hdfs 路径
hdfs dfs -du + hdfs 路径/文件名
hdfs dfs -rm + hdfs 路径/文件名(删除文件)
+ hdfs 路径/(删除文件夹)
--------------------------------------------------------------
-------------------------完全分布式-----------------------------
--------------------------------------------------------------
<!--`约定 node1 为NN启动节点,node2为SNN节点,node2,node3,node4为DN节点`-->
1、 JAVA_HOME
2、 免秘钥
ssh -keygen -t dsa -P '' -f ~/.ssh/id_dsa.pub
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
(各个几点都追加到~/.ssh/authorized_keys,然后统一分发,这样可以做到集群免秘钥)
cat authorized_keys
scp ~/.ssh/authorized_keys root@node2:`pwd`(分发到其他节点)
scp ~/.ssh/authorized_keys node2:`pwd`
验证: ssh node2
3、 vim /usr/local/hadoop-2.6.0/etc/hadoop/core-site.xml:
<!--指定NN启动位置-->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:9000</value>
<!--localhost 换成当前节点名称: node1-->
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/var/hadoop/full</value>
<!--不存在则自己创建-->
</property>
</configuration>
4、 vim /usr/local/hadoop-2.6.0/etc/hadoop/hdfs-site.xml
<!--副本数量不可超过节点数,不写默认3个,会一直报错-->
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.address</name>
<value>node2:50090</value>
</property>
</configuration>
5、 vim slaves(修改的是DN节点)
node2
node3
node4
6、 直接将node1配置好的分发到集群其他节点上
scp -r /usr/local/hadoop-2.6.0/ node2:/usr/local/
scp -r /usr/local/hadoop-2.6.0/ node3:/usr/local/
scp -r /usr/local/hadoop-2.6.0/ node4:/usr/local/
7、 在node1上格式化
hdfs dfs -format
8、 在node1上启动hdfs
start-dfs.sh
9、 验证是否启动成功!!!
jps
node1: NN
node2: SNN DN
node3: DN
node4: DN
Notice:
hdfs 默认端口8020 运行namenode
Hadoop2.x
产生背景
- Hadoop1.0 中HDFS和 MapReduce 在高可用和扩展性方面存在问题
- HDFS存在的问题
NameNode单点故障,难以应用于在线场景NameNode压力过大,且内存受限,影响系统扩展性。
- MapReduce存在的问题
JobTracker访问压力过大,影响系统扩展性难以支持除MapReduce外的其他计算框架,如Storm、Spark等
模型
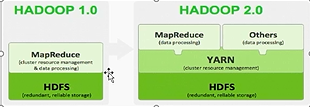
- Hadoop 2.x 由HDFS / YARN / MR 三个分支组成
- HDFS: NN Federation(联邦)(解决单点故障)、HA(解决单点压力)
- 2.X只支持2个节点的HA,3.X实现了一主多从
- MR: 运行在Yarn上的MR
- 离线计算,基于磁盘I/O计算
- Yarn:
资源调度系统
Hadoop 2.x

- HA的实现方式(NFS/JN集群)/ ZK集群-ZKFC 及其搭建方式
后续补充
- HA搭建
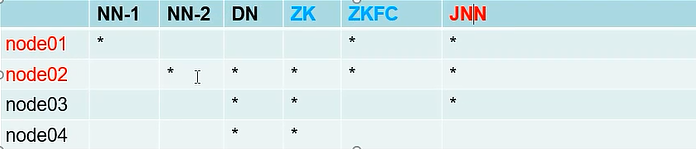
官网:点击跳转
<!--只需要在前面安装的基础上修改某些配置即可,建议:CP一份做备份-->
<!--删除secondary.nn-->
1. vim hdfs-site.xml
<property>
<name>dfs.nameservices</name>
<value>hacluster</value>
<!--hacluster这个值很关键-->
</property>
<property>
<name>dfs.ha.namenodes.hacluster</name>
<value>nn1,nn2</value>
</property>
<!--逻辑到物理的映射start-->
<property>
<name>dfs.namenode.rpc-address.hacluster.nn1</name>
<value>node1:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.hacluster.nn2</name>
<value>node2:8020</value>
</property>
<!--页面start-->
<property>
<name>dfs.namenode.http-address.hacluster.nn1</name>
<value>node1:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.hacluster.nn2</name>
<value>node2:50070</value>
</property>
<!--jn start-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node1:8485;node2:8485;node3:8485/hacluster</value>
</property>
<!--jn edits save dir start-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/var/hadoop/journal/node/local/data</value>
<!--这个值根据自己习惯定义即可-->
</property>
<!--故障切换实现方式-->
<property>
<name>dfs.client.failover.proxy.provider.hacluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/.ssh/id_rsa</value>
<!--这个找对应自己秘钥位置-->
</property>
<!--zk 自动化-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
2. vim core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://hacluster</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>node2:2181,node3:2181,node4:2181</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/var/hadoop/tmp/</value>
<!--这个目录一点要更改-->
</property>
3. 搭建ZK集群
zookeeper-3.4.6.jar
//1
tar -zxvf zookeeper-3.4.6.jar /usr/local/software/
//2
cp zoo_sample.cfg zoo.cfg
//3
vim zoo.cfg
dataDir=/usr/local/software/zookeeper/data
server.1=192.168.*.2:2888:3888
server.2=192.168.*.3:2888:3888
server.3=192.168.*.4:2888:3888
:wq
//4
cd /usr/local/software/zookeeper/data
echo 1 > myid
(!!! 后两个节点 echo 2 > myid|echo 3 > myid !!!)
//5 分发
//6 启动
zkServer.sh start (每个节点都要启动)
zkServer.sh status
leader(1个)
follower(2个)
zkCli.sh + enter 验证
quit 退出
4. 启动
hadoop-daemon.sh start journalnode(每台都启动)
jps 查看状态
hdfs namenode -format (在node1格式化)
//node1执行
hadoop-daemon.sh start namenode
//node2执行
hdfs namenode -bootstrapStandby
//zkFC格式化 node1执行
$HADOOP_HOME/bin/hdfs zkfc -formatZK
start-dfs.sh
jps 查看
<!--打开页面 node1:50070 ,linux 执行kill -9 11000(namenode) 验证是否成功 node2 变成 active ,然后在 node1 执行 hadoop-daemon.sh start namenode node1 变成stanyby 恭喜成功 -->
$HADOOP_HOME/sbin/hadoop-daemon.sh --script $HADOOP_HOME/bin/hdfs start zkfc
- 联邦 HDFS Federation实现及其搭建方式
后续补充