原文:Recommendation System Algorithms
今天,许多公司使用大数据来制定超级相关的推荐系统和增长收入。 在各种推荐算法中,数据科学家需要根据业务的限制和要求选择最好的算法。
为简化此任务, Statsbot 团队准备了现有的主要推荐系统算法的概述。
Collaborative filtering
协同过滤(CF)及其改进是最常用的推荐算法之一。 即使数据科学家初学者也可以使用它来构建他们的个人电影推荐系统,例如简历项目 a resume project。
当我们想向用户推荐某些东西时,最合乎逻辑的是找到具有相似兴趣的人,分析他们的行为,并向用户推荐相同的项目。 或者我们可以看看类似于用户以前购买的产品,并推荐像它们这样的产品。
这是CF中的两种基本方法:基于用户的协同过滤和基于项目的协同过滤。
两种方法的推荐系统都有两个步骤:
- 了解数据库中有多少用户/产品与给定的用户/产品相似。
- 考虑到与此类似的用户/产品的总权重,评估其他用户/产品以预测用户将给予该产品的评分。
这个算法中“相似”是什么意思呢
我们拥有的数据是每个用户的偏好向量(矩阵R的行)和用户对每个产品的评分(矩阵R的列)。
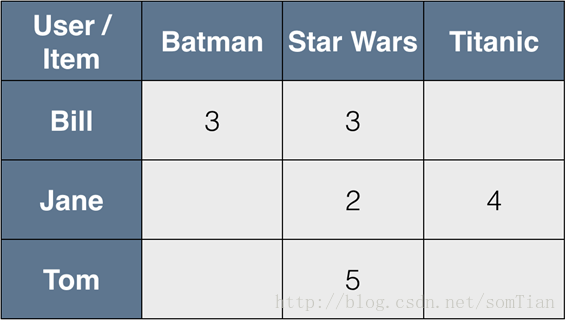
首先,我们只留下我们知道的两个向量中的值的元素。
例如,如果我们想比较Bill和Jane,我们注意到到Bill没有看过Titanic,Jane没有看Batman,所以我们只能通过Star Wars来衡量他们的相似度。 所有人都看了Star Wars。

最流行的测量相似度的技术是余弦相似性 cosine similarity或用户/项目向量之间的相关性correlations。 最后一步是根据相似程度采用加权算术平均值weighted arithmetic mean填充表中的空单元格。
Matrix decomposition for recommendations
下一个流行的方法是矩阵分解。 这是一个非常优雅的推荐算法,因为通常,当涉及到矩阵分解时,我们并没有过多思考什么项目将停留在所得到的矩阵的列和行中。 但是使用这个推荐方法,我们清楚地看到,u是第i个用户的兴趣向量,v是第j个电影的参数向量。
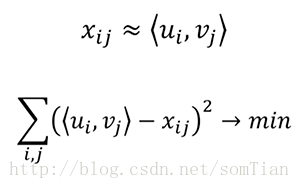
所以我们可以用u和v的点积来估计x(第i个用户对第j个电影的评分)。我们用已知的分数构建这些向量,并使用它们来预测未知的评分。
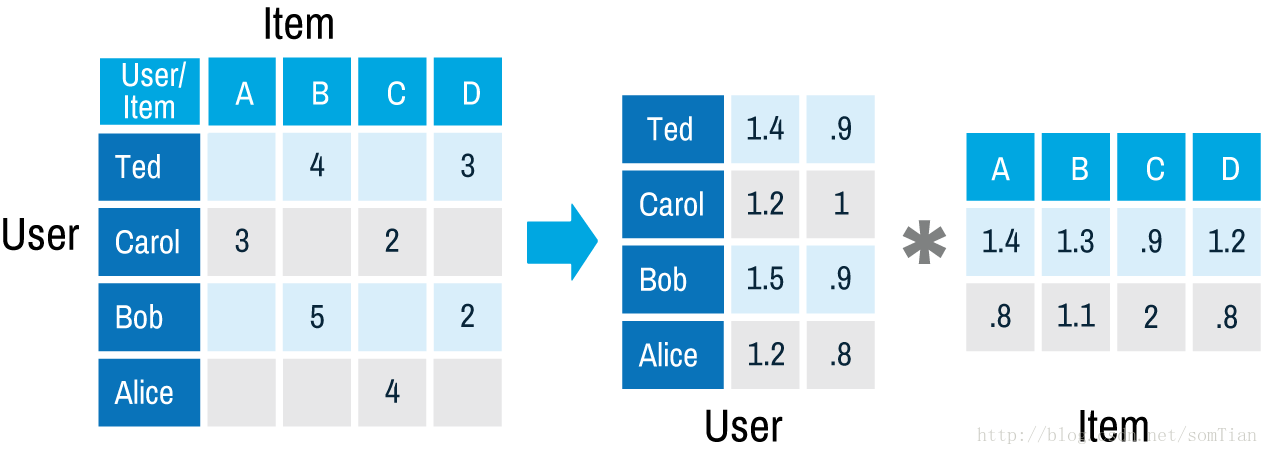
例如,在矩阵分解之后,Item A 的向量是(1.4; .8),Ted的向量是(1.4; .9),现在我们可以通过计算(1.4;.9)和(1.4; .8)的点积来计算A-Ted的评分,结果,我们得到2.68的评分。
Clustering
以前的推荐算法相当简单,适用于小型系统。 直到现在,我们仍然把推荐问题作为有监督的机器学习任务。 现在是应用无监督的方法来解决问题的时候了。
想象一下,我们正在建立一个大的推荐系统,此时协同过滤和矩阵分解会花费很长的时间。 因此我们的第一个想法是聚类。
在业务开始时,系统缺少用户以前的评分,此时聚类将是最好的方法。
但是分开来看,聚类性能有点弱,因为我们事实上所做的是识别用户组,并给这个组中的每个用户推荐相同的项目。 当我们有足够的数据时,最好使用聚类作为缩减协作过滤算法中相关邻居选择的第一步。 它还可以提高复杂的推荐系统的性能。
根据属于群组的客户的偏好,每个群将被分配给典型的偏好。 每个群中的客户将收到在群级别计算的推荐。
Deep learning approach for recommendations
在过去十年中,神经网络已经取得了巨大的飞跃。 今天,它们应用广泛,正在逐渐取代传统的ML方法。 我想向您展示YouTube如何使用深度学习方法。
毫无疑问,由于大规模,动态语料库和各种不可观察的外部因素,为这种服务提出推荐是一项非常具有挑战性的任务。
根据“Deep Neural Networks for YouTube Recommendations”的研究,YouTube推荐系统算法由两个神经网络组成:一个用于候选生成,一个用于排名。 如果你没有足够的时间,我会在这里留下这个研究的快速总结。
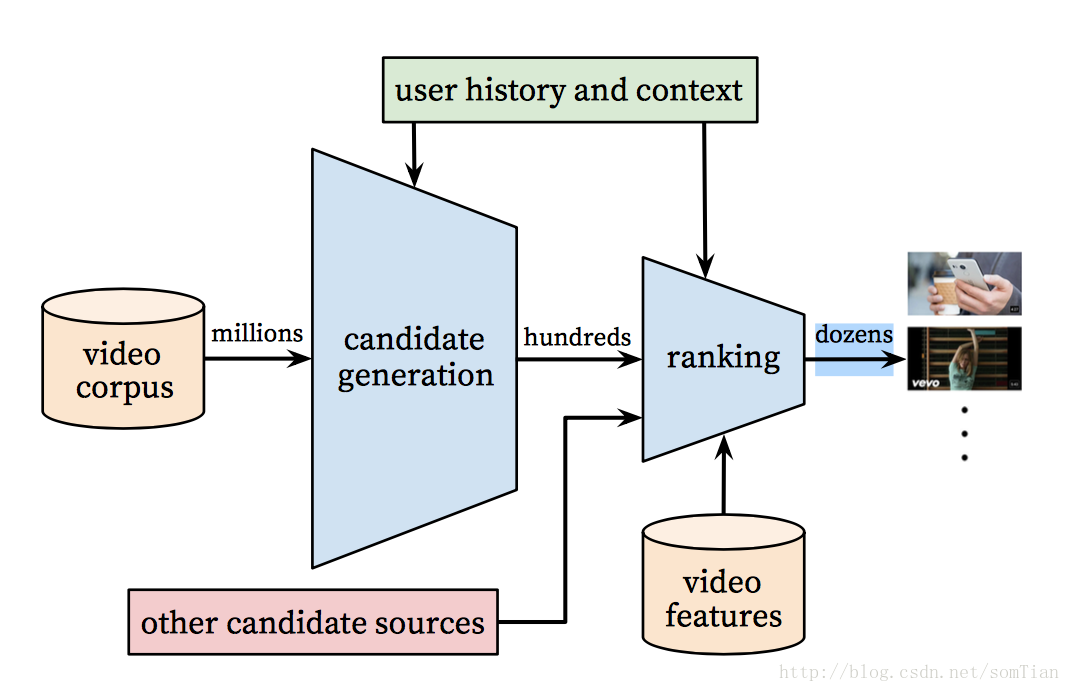
将用户历史的事件作为输入,候选生成网络显着减少视频的数量,并从大型库得到一组最相关的视频。 生成的候选集与预测评分的用户最相关。 该网络的目标只是通过协同过滤提供广泛的个性化。
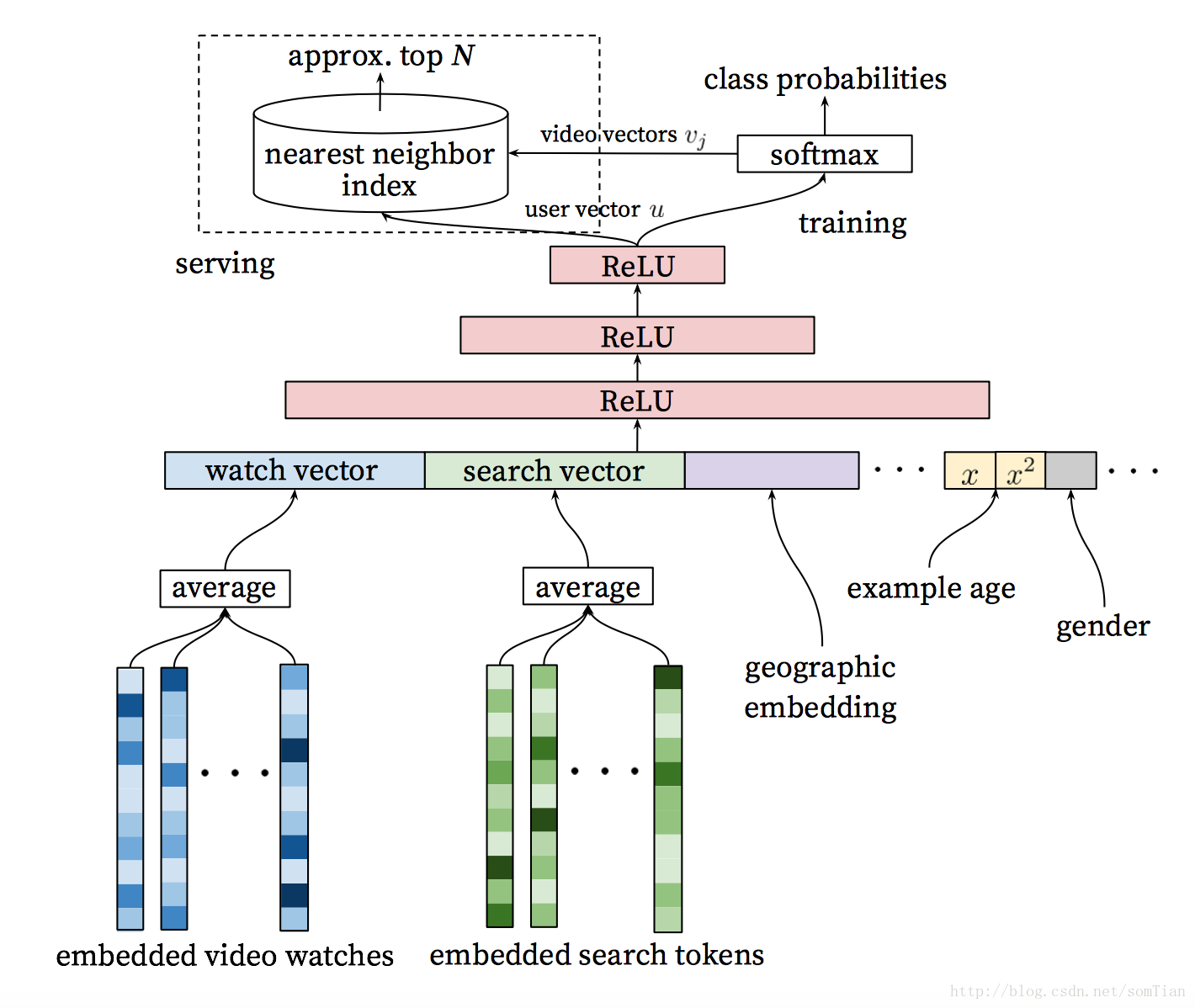
在这一步,我们有更少的与用户类似的候选。 我们的目标是更仔细地分析所有这些,以便我们做出最好的决策。 该任务由排名网络完成,排名网络可以根据使用描述视频的数据和关于用户行为的信息的期望目标函数为每个视频分配分数。 用户评分最高的视频会按照分数排列。
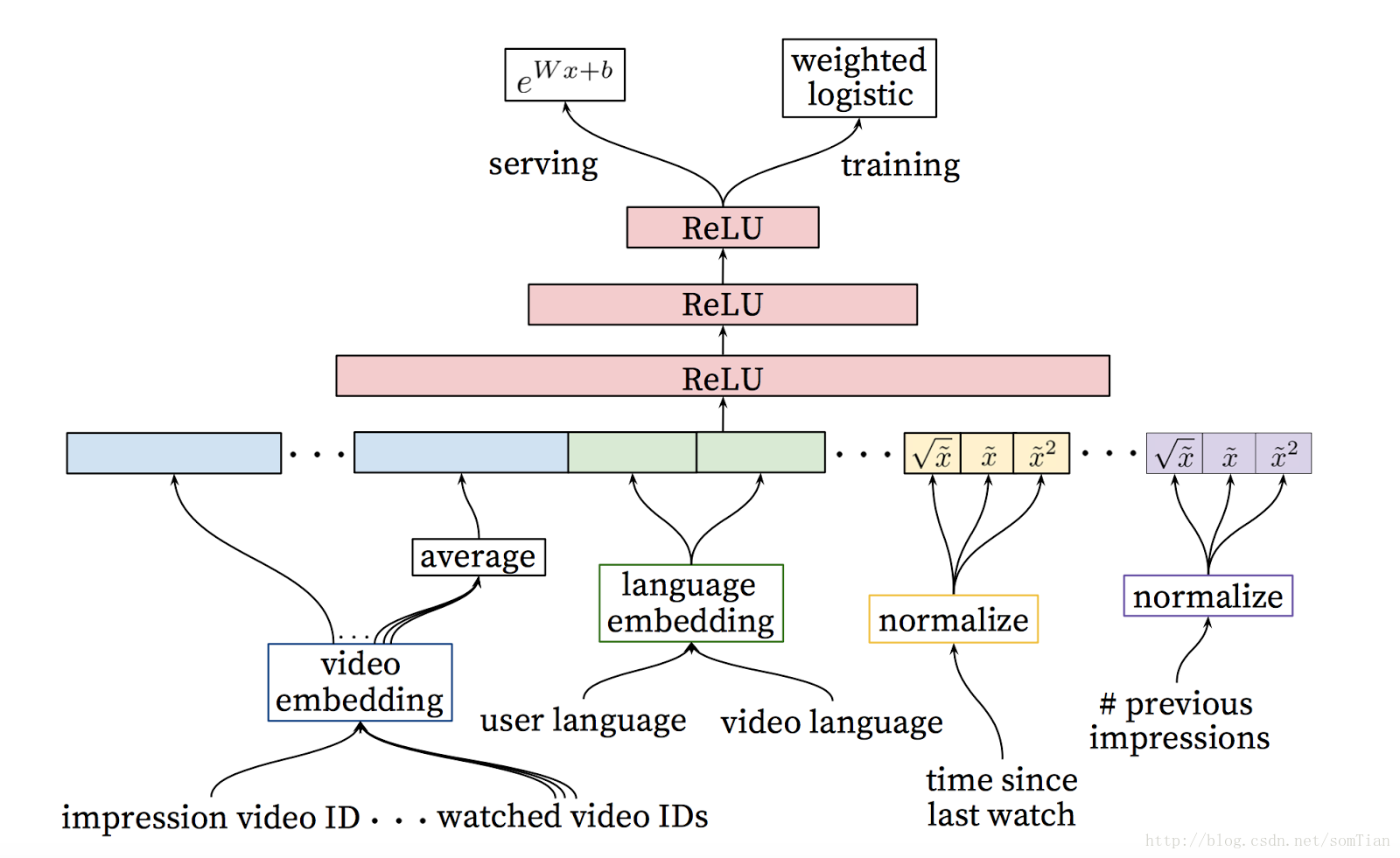
使用两阶段的方法,我们可以从非常大的视频语料库中提供视频推荐,同时仍然确定少数的个性化和吸引用户。 这种设计还使我们能够将由其他来源产生的候选混合在一起。
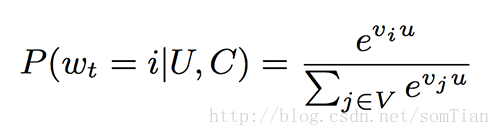
推荐任务是一个极端的多类分类问题,其中预测问题在基于用户(U)和上下文(C)的语料库(V)的数百万个视频类别(i)中的给定时间t精确地分类特定视频观看(wt) 。
Important points before building your own recommendation system
如果你有一个庞大的数据库,并在线进行推荐,最好的办法就是把这个问题分成2个子问题:1)选择N个候选,2)对候选进行排名。
如何衡量模型的质量? 除了标准质量指标之外,还有一些针对推荐问题的指标:Recall @ k和Precision @ k,Average Recall @ k和Average Precision @ k。 可以查看 the great description of metrics for recommendation systems。
如果你正在使用分类算法解决推荐问题,你应该考虑生成负样本。 如果用户购买了推荐商品,您不应将其作为正样本,而将其他商品作为负样本。
考虑算法质量的在线分数和离线评分。 只根据历史数据的训练模型导致原始的推荐,因为算法不会了解新的趋势和偏好。