版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/mpk_no1/article/details/72510677
本文主要介绍一个Word2vec和Doc2vec应用示例:用Word2vec做词的相似度计算和用Doc2vec做句子的相似度计算。
该示例主要包含两部分:
1.训练Word2vec模型和Doc2vec模型;
2.用训练好的Word2vec模型和Doc2vec模型分别进行词相似度计算和句子相似度计算。
本例中采用的数据是13万多本中文科技图书的一级目录标题,将图书目录标题按行存储,每行是一个标题,用中文分词工具HanLP进行分词。分词结果如下如所示:

将分词的结果传入Word2vec模型和Doc2vec模型训练词的word2vec和目录标题的doc2vec。Word2vec模型和Doc2vec模型训练使用的Java版本实现的,可以从我的GitHub上获取(Java版本Word2vec和doc2vec)。
训练好Word2vec模型和Doc2vec模型之后,就可以将模型加载进内存中,然后对输入的词语计算跟它最相近的TOP10个词(按降序排序),对输入的标题计算跟它最相近的TOP10个标题(按降序排序)。
相似度计算公式采用的是余弦相似度:

下面是词相似度计算的例子:

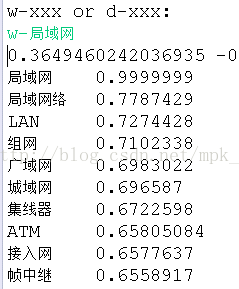
从上图中可以看出,词的相似度计算结果还是可以的,一般都能找到有一定关系的词语。
下面是标题相似度计算的例子:

从图中可以看出,标题相似度的例子并不太好,分析原因:一则可能是语料库不够大;二则图书目录标题太短,分词之后一般只有几个词语,这样将每一个标题当做一个文档训练得到的Doc2vec的效果就不够好。这方面还有很大改进空间。
具体代码可以到我的GitHub上获取,欢迎fork和star。地址:点击打开链接