需求:将豆瓣电影的评论爬取出来,用词云的方式对其进行分析
步骤分析:
1). 分析网站的源码
2). 通过url获取电影名和电影id
3). 获取指定的电影的评论
4). 数据的清洗,去除一些不需要的信息
5). 进行词云的分析
-
分析网站的源码
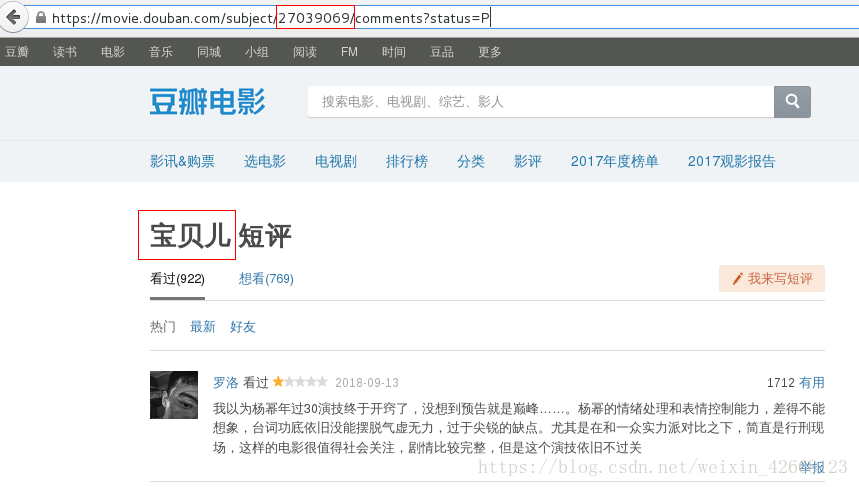
通过源码分析,豆瓣电影是靠电影名称和电影的id来区分每个电影的,想要获取各个电影的影评,需要先获取上面两个信息
比如说《宝贝儿》这部电影,它的id就是:27039069
通过不同的id号,来访问不同的电影影评 -
通过url获取电影名和电影id
import requests
from bs4 import BeautifulSoup
url='https://movie.douban.com/cinema/nowplaying/xian/'
# 1)获取页面信息
response=requests.get(url)
content=response.text
# print(content)
# 2)分析页面,获取id和电影名
soup=BeautifulSoup(content,'html.parser')
# 先找到所有的电影信息对应的li标签
nowplaying_movie_list=soup.find_all('li',class_='list-item')
# 存储所有的电影信息(名称和id)
movies_info=[]
for item in nowplaying_movie_list:
nowplaying_movie_dict = {}
nowplaying_movie_dict['title']=item['data-title']
nowplaying_movie_dict['id']=item['id']
movies_info.append(nowplaying_movie_dict)
print(movies_info)
执行结果:
将每个电影的名称和id放在一起

- 获取指定的电影的评论
import requests
from bs4 import BeautifulSoup
import threading
def get_info(id,pageNum):
# 根据页数确定start的值
start=20*(pageNum-1)
url='https://movie.douban.com/subject/%s/comments?start=%s&limit=20&sort=new_score&status=P' %(id,start)
# 2)爬取评论信息的网页内容
content=requests.get(url).text
# 3)通过bs4分析网页
soup=BeautifulSoup(content,'html.parser')
commentsList=soup.find_all('span',class_='short')
comments=''
for commentTag in commentsList:
comments+=commentTag.text
print(comments)
id = '27039069'
threads=[]
for pageNum in range(1,10):
get_info(id,pageNum)
t=threading.Thread(target=get_info,args=(id,pageNum))
threads.append(t)
t.start()
[thread.join() for thread in threads]
执行结果:
通过多线程来爬取电影的影评,将提取到的内容存入对应的文件中,以背后面的分析

- 数据的清洗,去除一些不需要的信息
import re
with open('./27039069.txt')as f:
comments=f.read()
pattern=re.compile(r'([\u4e00-\u9fa5]+|[a-zA-Z]+)')
deal_comments=re.findall(pattern,comments)
newComments=''
for item in deal_comments:
newComments+=item
print(newComments)
执行结果:
将评论中的表情或者特殊字符去掉,只留下文字与英文,作词云分析

- 进行词云的分析
做词云分析时,这里需要两个特殊的模块
import wordcloud
import jieba
将数据进行分离,再统计数据的数量,根据数量自动设置字体的大小
import jieba
import wordcloud
import numpy
from PIL import Image
result=jieba.lcut(open('./27039069.txt').read())
imageObj=Image.open('./image.jpg')
cloud_mask=numpy.array(imageObj)
wc=wordcloud.WordCloud(
background_color='snow',
mask=cloud_mask,
font_path='./msyh.ttf',
min_font_size=5,
max_font_size=50,
width=260,
height=260,
)
wc.generate(','.join(result))
wc.to_file('./ciyun.png')
执行结果:
这样一部电影的词云分析就完成了,其实挺好看的
