目录
什么是Ernie-3.0?
Ernie-3.0 是百度推出的一款大型预训练语言模型。与以往的BERT和GPT等模型不同,Ernie-3.0是一种"知识增强"的预训练模型,能够理解并使用多种类型的知识,包括词汇语义、实体关系、事件事实等。因此,Ernie-3.0在许多NLP任务上都表现出了强大的性能。
解压文件
In [4]
!unzip -oq /home/aistudio/data/data32015/Dataset.zip更新nlp版本
In [ ]
# !pip install --upgrade paddlenlp数据基本处理
利用paddlenlp.datasets中的 DatasetBuilder函数对数据进行处理
最后数据变成了[{'text_a': 'data', 'label': label},……] 的格式
In [5]
from paddlenlp.datasets import DatasetBuilderIn [6]
class NewsData(DatasetBuilder):
SPLITS = {
'train': './Dataset/train.txt', # 训练集
'dev': './Dataset/validation.txt', # 验证集
'test': './Dataset/test.txt'
}
def _get_data(self, mode, **kwargs):
filename = self.SPLITS[mode]
return filename
def _read(self, filename):
"""读取数据"""
with open(filename, 'r', encoding='utf-8') as f:
for line in f:
if line == '\n':
continue
data = line.strip().split("\t") # 以'\t'分隔各列
label, text_a = data
text_a = text_a.replace(" ", "")
if label in ['0', '1']:
yield {"text_a": text_a, "label": label} # 此次设置数据的格式为:text_a,label,可以根据具体情况进行修改
def get_labels(self):
return label_list # 类别标签In [7]
# 定义数据集加载函数
def load_dataset(name=None,
data_files=None,
splits=None,
lazy=None,
**kwargs):
reader_cls = NewsData # 加载定义的数据集格式
print(reader_cls)
if not name:
reader_instance = reader_cls(lazy=lazy, **kwargs)
else:
reader_instance = reader_cls(lazy=lazy, name=name, **kwargs)
datasets = reader_instance.read_datasets(data_files=data_files, splits=splits)
return datasetsIn [8]
# 加载训练和验证集
label_list = ['0', '1']
train_ds, dev_ds, text_t = load_dataset(splits=['train', 'dev', 'test'])<class '__main__.NewsData'>
展示数据
In [9]
train_ds[:5][{'text_a': '死囚爱刽子手女贼爱衙役我们爱你们难道还有别的选择没想到胡军除了蓝宇还有东宫西宫我个去阿兰这样真他nia恶心爱个P分明只是欲',
'label': 1},
{'text_a': '其实我对锦衣卫爱情很萌因为很言情小说可惜女主角我要不是这样被乔花去偷令牌青龙吃醋想出箭那里萌到让我想起雏菊里郑大叔徐子珊吴尊真是可怕他们完全不是电影料还有脱脱这个名字想要雷死观众导演到底想什么剧情混乱老套无趣对白更是白痴失望',
'label': 1},
{'text_a': '两星半小明星本色出演老演员自己发挥基本上王力宏表演指导上没有什么可发挥地方整体结构失衡情节讨巧也一众观众喜欢原因使得这部电影王力宏演唱会一样不停处女作却体现不出王力宏个人风格不能说成功相对来说周董处女作更像电影一些',
'label': 1},
{'text_a': '神马狗血编剧神马垃圾导演女猪脚无胸无人胃口一干男猪脚基情四射毫无演技虽然很多电影比你更烂但你掌握这么多资源拍成这样不给丫一颗星我胸闷',
'label': 1},
{'text_a': 'Feb半顆星我們家說這是一部從開始第十二分鐘我開始打哈欠一直最後迫不及待離場商業氣息無比濃重看不得植入廣告三秒狗屎大好河山背景電影順便坐前面落寞大叔合著鬍水我留下深刻印象我不明白為上觀眾如此配合',
'label': 1}]
模型介绍
文心大模型 ERNIE 3.0 作为百亿参数知识增强的大模型,除了从海量文本数据中学习词汇、结构、语义等知识外,还从大规模知识图谱中学习。 基础上通过在线蒸馏技术得到的轻量级模型,模型结构与 ERNIE 2.0 保持一致,相比 ERNIE 2.0 具有更强的中文效果。
通过在线蒸馏技术将模型尽可能减少损失的情况下对模型大小进行压缩,使得模型的尺寸更加符合各类使用场景。
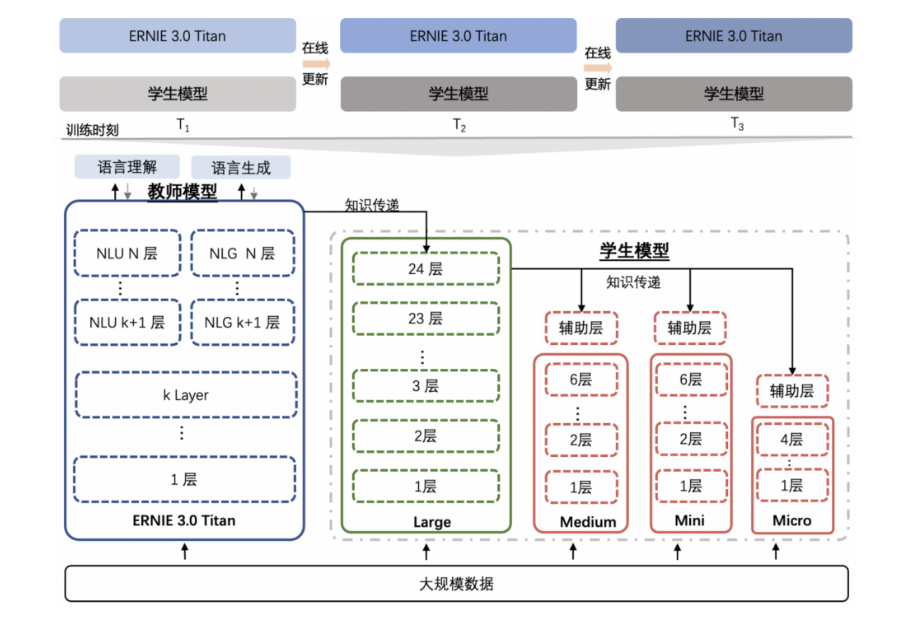
上图为在线模型蒸馏技术。 本文中使用的是经过蒸馏后的ernie-3.0-medium模型,在保证进度和性能的前提下尽可能的减少我们模型的大小与尺寸,同时加快我们的预测速度。

通过测试数据,可以非常清晰的看到在模型的效果和质量上比同类型模型效果更好
参考文献及有关地址:
GitHub地址:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/ernie-3.0
ERNIE-Tiny: A Progressive Distillation Framework for Pretrained Transformer Compression
《解析全球最大中文单体模型鹏城-百度·文心技术细节》:解析全球最大中文单体模型鹏城-百度·文心技术细节 | 机器之心
ernie-3.0-medium-zh模型导入
导入ernie-3.0-medium-zh模型及其分词器等内容
定义最大字长,语段批次大小等
In [1]
import os
import paddle
import paddlenlpIn [2]
from paddlenlp.transformers import AutoModelForSequenceClassification, AutoTokenizer
model_name = "ernie-3.0-medium-zh"
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_classes=2)
tokenizer = AutoTokenizer.from_pretrained(model_name)[2023-05-10 00:09:36,053] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.modeling.ErnieForSequenceClassification'> to load 'ernie-3.0-medium-zh'. [2023-05-10 00:09:36,058] [ INFO] - Downloading https://bj.bcebos.com/paddlenlp/models/transformers/ernie_3.0/ernie_3.0_medium_zh.pdparams and saved to /home/aistudio/.paddlenlp/models/ernie-3.0-medium-zh 100%|██████████| 320029/320029 [00:06<00:00, 52211.78it/s] [2023-05-10 00:09:51,259] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load 'ernie-3.0-medium-zh'. [2023-05-10 00:09:51,263] [ INFO] - Downloading https://bj.bcebos.com/paddlenlp/models/transformers/ernie_3.0/ernie_3.0_medium_zh_vocab.txt and saved to /home/aistudio/.paddlenlp/models/ernie-3.0-medium-zh [2023-05-10 00:09:51,266] [ INFO] - Downloading ernie_3.0_medium_zh_vocab.txt from https://bj.bcebos.com/paddlenlp/models/transformers/ernie_3.0/ernie_3.0_medium_zh_vocab.txt 100%|██████████| 182k/182k [00:00<00:00, 19.0MB/s] [2023-05-10 00:09:51,374] [ INFO] - tokenizer config file saved in /home/aistudio/.paddlenlp/models/ernie-3.0-medium-zh/tokenizer_config.json [2023-05-10 00:09:51,377] [ INFO] - Special tokens file saved in /home/aistudio/.paddlenlp/models/ernie-3.0-medium-zh/special_tokens_map.json
In [ ]
from functools import partial
from paddlenlp.data import Stack, Tuple, Pad
from utils import convert_example, create_dataloader
# 模型运行批处理大小
batch_size = 32
max_seq_length = 128
trans_func = partial(
convert_example,
tokenizer=tokenizer,
max_seq_length=max_seq_length)
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # segment
Stack(dtype="int64") # label
): [data for data in fn(samples)]
train_data_loader = create_dataloader(
train_ds,
mode='train',
batch_size=batch_size,
batchify_fn=batchify_fn,
trans_fn=trans_func)
dev_data_loader = create_dataloader(
dev_ds,
mode='dev',
batch_size=batch_size,
batchify_fn=batchify_fn,
trans_fn=trans_func)
模型预训练
In [ ]
import paddlenlp as ppnlp
import paddleIn [ ]
from paddlenlp.transformers import LinearDecayWithWarmup
# 训练过程中的最大学习率
learning_rate = 5e-6
# 训练轮次
epochs = 10 #3
# 学习率预热比例
warmup_proportion = 0.3
# 权重衰减系数,类似模型正则项策略,避免模型过拟合
weight_decay = 0.01
num_training_steps = len(train_data_loader) * epochs
lr_scheduler = LinearDecayWithWarmup(learning_rate, num_training_steps, warmup_proportion)
optimizer = paddle.optimizer.AdamW(
learning_rate=lr_scheduler,
parameters=model.parameters(),
weight_decay=weight_decay,
apply_decay_param_fun=lambda x: x in [
p.name for n, p in model.named_parameters()
if not any(nd in n for nd in ["bias", "norm"])
])
criterion = paddle.nn.loss.CrossEntropyLoss()
metric = paddle.metric.Accuracy()In [ ]
# checkpoint文件夹用于保存训练模型
# !mkdir /home/aistudio/checkpointIn [ ]
import matplotlib.pyplot as plt
Batch=0
Batchs=[]
all_train_accs=[]
def draw_train_acc(Batchs, train_accs):
title="training accs"
plt.title(title, fontsize=24)
plt.xlabel("batch", fontsize=14)
plt.ylabel("acc", fontsize=14)
plt.plot(Batchs, train_accs, color='green', label='training accs')
plt.legend()
plt.grid()
plt.show()
all_train_loss=[]
def draw_train_loss(Batchs, train_loss):
title="training loss"
plt.title(title, fontsize=24)
plt.xlabel("batch", fontsize=14)
plt.ylabel("loss", fontsize=14)
plt.plot(Batchs, train_loss, color='red', label='training loss')
plt.legend()
plt.grid()
plt.show()In [ ]
import paddle.nn.functional as F
from utils import evaluate
global_step = 0
for epoch in range(1, epochs + 1):
for step, batch in enumerate(train_data_loader, start=1):
input_ids, segment_ids, labels = batch
logits = model(input_ids, segment_ids)
loss = criterion(logits, labels)
probs = F.softmax(logits, axis=1)
correct = metric.compute(probs, labels)
metric.update(correct)
acc = metric.accumulate()
global_step += 1
if global_step % 10 == 0 :
print("global step %d, epoch: %d, batch: %d, loss: %.5f, acc: %.5f" % (global_step, epoch, step, loss, acc))
Batch += 10
Batchs.append(Batch)
all_train_loss.append(loss)
all_train_accs.append(acc)
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.clear_grad()
evaluate(model, criterion, metric, dev_data_loader)
model.save_pretrained('/home/aistudio/checkpoint')
tokenizer.save_pretrained('/home/aistudio/checkpoint')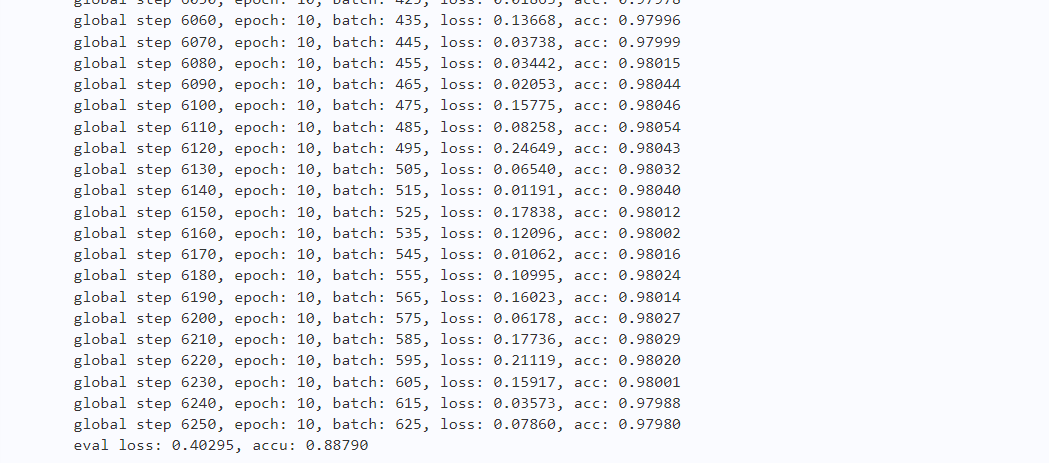
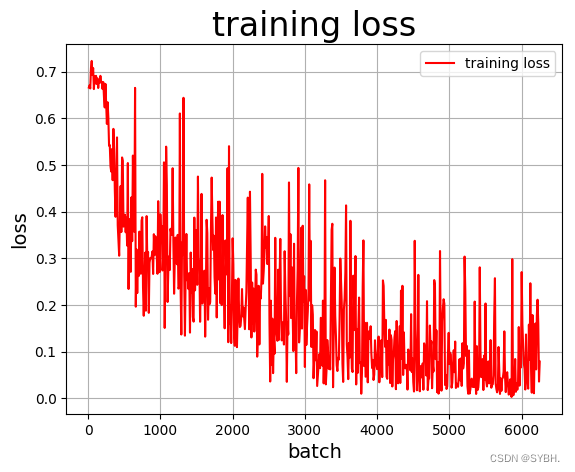
训练效果可视化展示(训练集)
In [ ]
draw_train_acc(Batchs,all_train_accs)
draw_train_loss(Batchs,all_train_loss)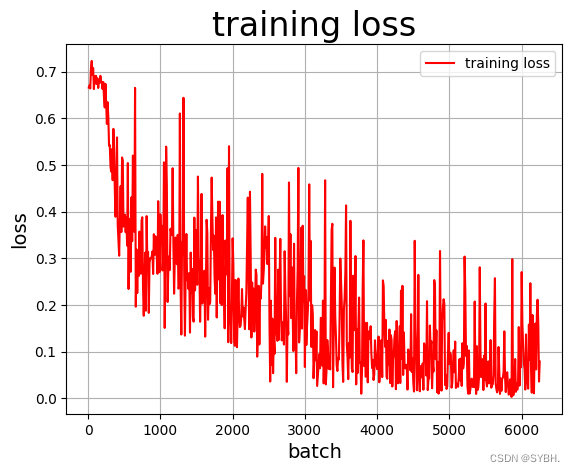
<Figure size 640x480 with 1 Axes>
<Figure size 640x480 with 1 Axes>
模型结果预测
In [10]
for i in text_t:
print(i)
break{'text_a': '如果我无聊时网上乱逛偶尔看到这部电影我可能会给它打四星但是TNND姐是花大洋去电影院看姐在电影院睡着姐现在非常心疼电影票钱一部无聊至极电影', 'label': 1}
In [11]
# 加载在验证集上效果最优的一轮的模型参数
import os
import paddle
params_path = 'checkpoint/model_state.pdparams'
if params_path and os.path.isfile(params_path):
# 加载模型参数
state_dict = paddle.load(params_path)
model.set_dict(state_dict)
print("Loaded parameters from %s" % params_path)In [ ]
from utils import predict
batch_size = 32
data = text_t
label_map = {0: '0', 1: '1'}
results = predict(
model, data, tokenizer, label_map, batch_size=batch_size)
for idx, text in enumerate(data):
print('Data: {} \t Lable: {}'.format(text, results[idx]))效果展示
