Attention-based Model其实就是一个相似性的度量,当前的输入与目标状态越相似,那么在当前的输入的权重就会越大,说明当前的输出越依赖于当前的输入。严格来说,Attention并算不上是一种新的model,而仅仅是在以往的模型中加入attention的思想,所以Attention-based Model或者Attention Mechanism是比较合理的叫法,而非Attention Model。
没有attention机制的encoder-decoder结构通常把encoder的最后一个状态作为decoder的输入(可能作为初始化,也可能作为每一时刻的输入),但是encoder的state毕竟是有限的,存储不了太多的信息,对于decoder过程,每一个步骤都和之前的输入都没有关系了,只与这个传入的state有关。attention机制的引入之后,decoder根据时刻的不同,让每一时刻的输入都有所不同。

深度解析:
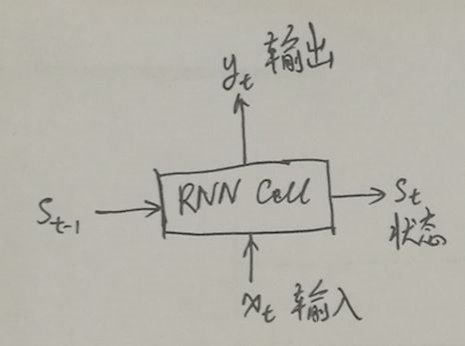
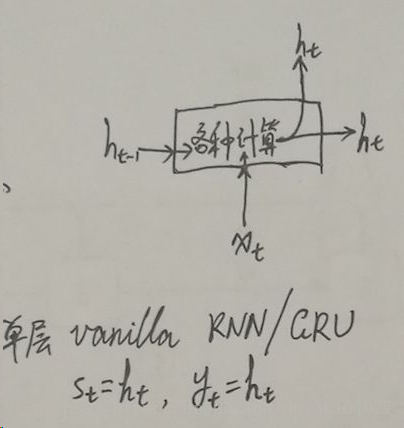
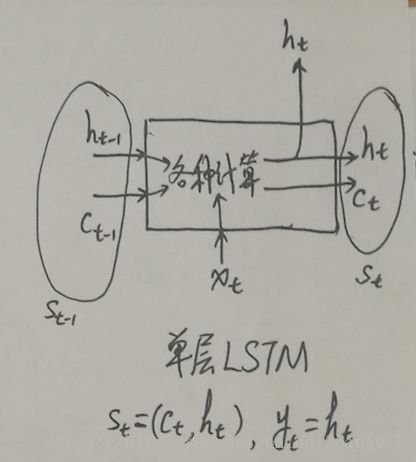
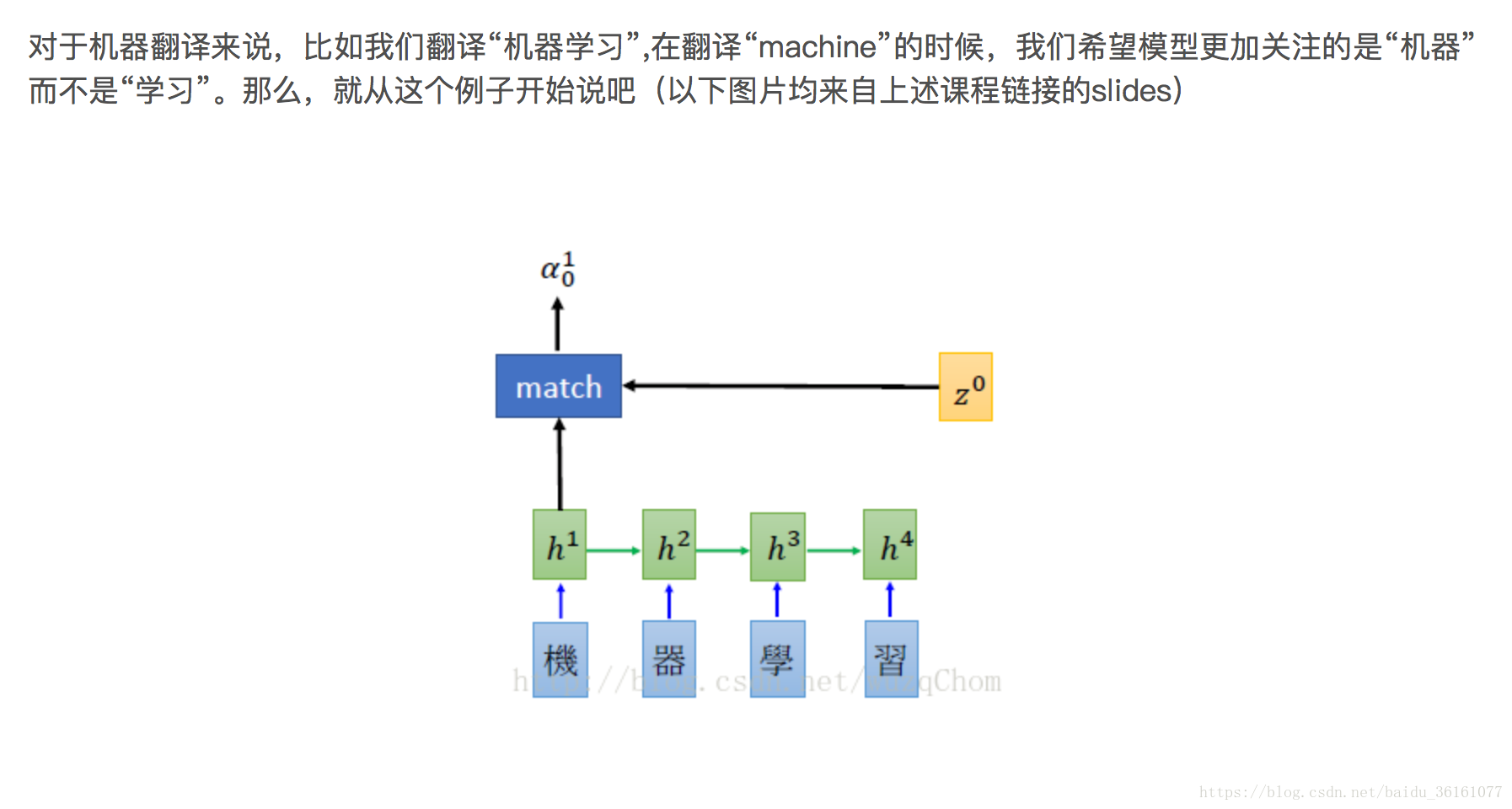
1.首先‘机器学习’经过word embedding之后变成词向量,‘机器学习’就相当于一个矩阵了,每个词都相当于一个向量,上图中的h0,h1,h2,…..这些都是RNN对词向量进行编码的隐状态,这些隐状态是什么呢?有什么作用?结合之前的RNN和LSTM的网络的结构的输入和输出可以知道,从图2 中就可以看出单层的RNN中的hidden_state 和output是一样的。在LSTM中的输出的st包含了hidden_state 和 cell_state, cell_state是决定了哪些信息是保留的,哪些信息是遗忘掉的,其中真正用于循环的状态 s_t 其实是 (c_t, h_t) 组成的 tuple(就是 TensorFlow 里的 LSTMStateTuple,当然,如果你选择不用 tuple 表示 LSTM 的内部状态,也可以把 c_t 和 h_t 拼起来,合起来拼成一个 Tensor,这样的话它的状态就是一个 Tensor 了,这时做别的计算可能会方便一些,这个其实就是TensorFlow 里的 state_is_tuple 这个开关。),而输出y_t 仅仅是 h_t(例如网络后面再接一个全连接层然后用softmax 做分类,这个全连接层的输入仅仅是 h_t,而没有c_t),这时就可以看到区分 RNN 的输出和状态的意义了。
2.Lee 老师里面的h1,h2,h3,h4是RNN隐层的输出向量,RNN隐层的hidden_states和output其实是一样的,所以h1,h2,h3,h4,可以说是不同时间步的编码向量,
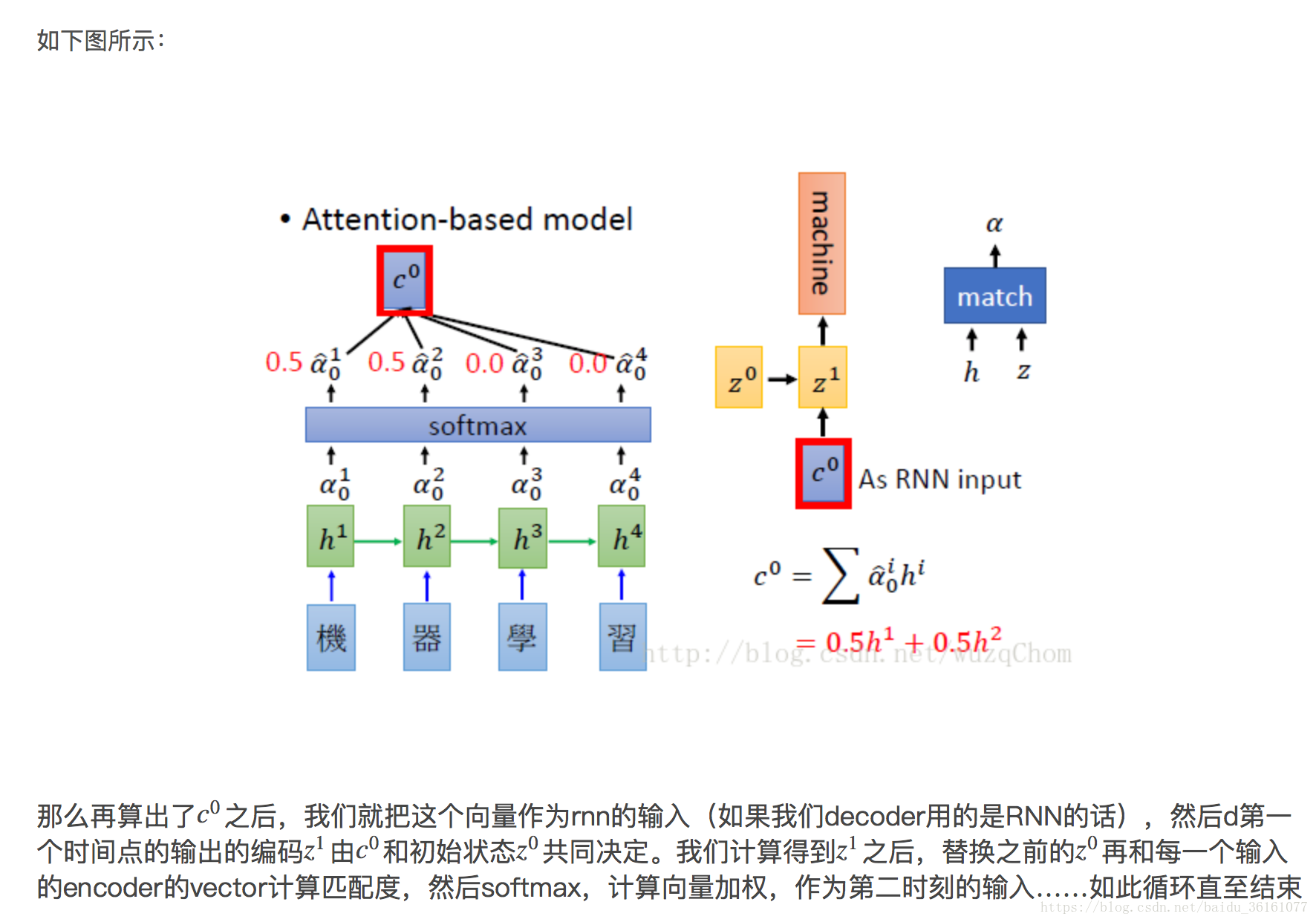
3.初始化解码器端的隐含状态(z0,initial_state),将z0与encoder端的h0,h1,h2,h3分别做match计算,得到每一个timestep的 match score,然后利用softmax 将match score 归一化到(0,1),那么我们可以根据归一化的match score 计算出加权向量和,即c0,然后利用c0和z0作为RNN的输入计算得到z1。