1.什么是注意力机制?
注意力机制模仿了生物观察行为的内部过程,即一种将内部经验和外部感觉对齐从而增加部分区域的观察精细度的机制。例如人的视觉在处理一张图片时,会通过快速扫描全局图像,获得需要重点关注的目标区域,也就是注意力焦点。然后对这一区域投入更多的注意力资源,以获得更多所需要关注的目标的细节信息,并抑制其它无用信息。
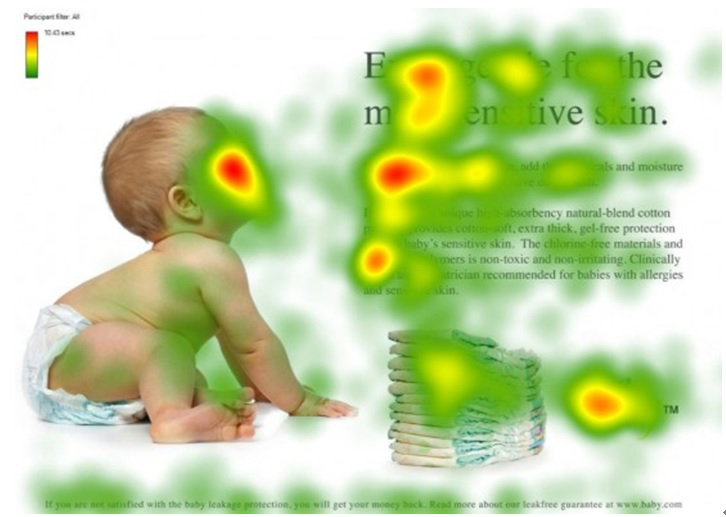
图片来源:深度学习中的注意力机制,其中红色区域表示更关注的区域。
2|0Encoder-Decoder 框架
目前大多数的注意力模型都是依附在 Encoder-Decoder 框架下,但并不是只能运用在该模型中,注意力机制作为一种思想可以和多种模型进行结合,其本身不依赖于任何一种框架。Encoder-Decoder 框架是深度学习中非常常见的一个模型框架,例如在 Image Caption 的应用中 Encoder-Decoder 就是 CNN-RNN 的编码 - 解码框架;在神经网络机器翻译中 Encoder-Decoder 往往就是 LSTM-LSTM 的编码 - 解码框架,在机器翻译中也被叫做 Sequence to Sequence learning 。
所谓编码,就是将输入的序列编码成一个固定长度的向量;解码,就是将之前生成的固定向量再解码成输出序列。这里的输入序列和输出序列正是机器翻译的结果和输出。
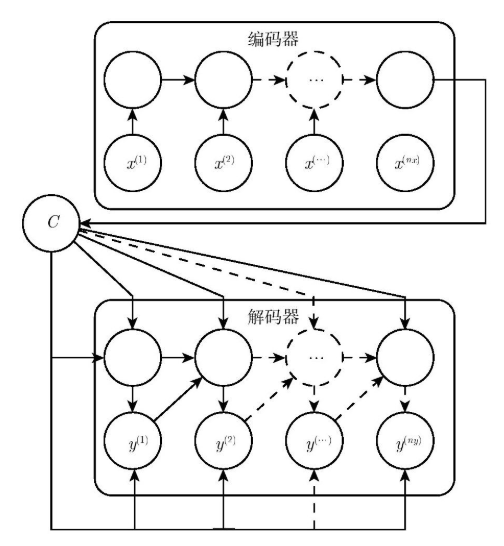
为了说明 Attention 机制的作用,以 Encoder-Decoder 框架下的机器翻译的应用为例,该框架的抽象表示如下图:

2|1局限性
Encoder-Decoder 框架虽然应用广泛,但是其存在的局限性也比较大。其最大的局限性就是 Encoder 和 Decoder 之间只通过一个固定长度的语义向量 CC 来唯一联系。也就是说,Encoder 必须要将输入的整个序列的信息都压缩进一个固定长度的向量中,存在两个弊端:一是语义向量 C 可能无法完全表示整个序列的信息;二是先输入到网络的内容携带的信息会被后输入的信息覆盖掉,输入的序列越长,该现象就越严重。这两个弊端使得 Decoder 在解码时一开始就无法获得输入序列最够多的信息,因此导致解码的精确度不够准确。
3|0Attention 机制
在上述的模型中,Encoder-Decoder 框架将输入 XX 都编码转化为语义表示 CC,这就导致翻译出来的序列的每一个字都是同权地考虑了输入中的所有的词。例如输入的英文句子是:Tom chase Jerry,目标的翻译结果是:汤姆追逐杰瑞。在未考虑注意力机制的模型当中,模型认为 汤姆 这个词的翻译受到 Tom,chase 和 Jerry 这三个词的同权重的影响。但是实际上显然不应该是这样处理的,汤姆 这个词应该受到输入的 Tom 这个词的影响最大,而其它输入的词的影响则应该是非常小的。显然,在未考虑注意力机制的 Encoder-Decoder 模型中,这种不同输入的重要程度并没有体现处理,一般称这样的模型为 分心模型。
而带有 Attention 机制的 Encoder-Decoder 模型则是要从序列中学习到每一个元素的重要程度,然后按重要程度将元素合并。因此,注意力机制可以看作是 Encoder 和 Decoder 之间的接口,它向 Decoder 提供来自每个 Encoder 隐藏状态的信息。通过该设置,模型能够选择性地关注输入序列的有用部分,从而学习它们之间的“对齐”。这就表明,在 Encoder 将输入的序列元素进行编码时,得到的不在是一个固定的语义编码 C ,而是存在多个语义编码,且不同的语义编码由不同的序列元素以不同的权重参数组合而成。一个简单地体现 Attention 机制运行的示意图如下:
定义:对齐
对齐是指将原文的片段与其对应的译文片段进行匹配。
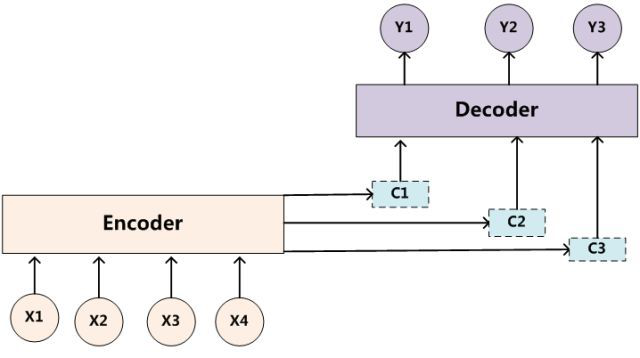

其中,hihi 表示 Encoder 的转换函数,F(hj,Hi)F(hj,Hi) 表示预测与目标的匹配打分函数。将以上过程串联起来,则注意力模型的结构如下图所示:
