1.回顾smo
前面几节详细的介绍了支持向量机的理论,首先是从线性分类进行引入支持向量机,然后寻找最优超平面,即寻找最大间隔(目的是为了寻找最优超平面),为了解决约束条件引入了拉格朗日因子把约束添加到目标式子中,通过对偶方式把问题转移到求解拉格朗日因子上,同时为了解决离群值问题,引入了松弛变量,最后形式为只含有拉格朗日因子和kkt约束条件,即如下:

该方程的解决就是使用SMO算法即Sequential minimal optimization(序列最小优化),在这里需要说明的是,为了不编辑式子,本人通过剪贴原始论文的方式进行讲解,但是原始论文和我们上面的表达式不同,不同的原因前几篇文章已经详细讲解了,在这里再简单的提一下,是因为当时作者假设是:

最后的形式是这样的:

和我们推的正好相反,我们是求最大值,他是求最小值,原因是减号颠倒了,如果两边强行两边乘以一个负号就和我们的形式一样了,所以大家需要知道这一点,别晕了,为了方便(不想编辑公式了),我按照原作者的格式进行讲解,理解是一样的,中间有区别的我会强调说明一下,下面在帮大家回忆一下smo算法的大致流程和原理:
先任意定两个变量为未知的,其他
任意赋值给定为已知,例如我们先假设
和
是未知的,他的均为已知,那么通过等式(
)用
表示
,带回上式,此时未知数只有
,因此化简后是一个含
的二次函数(因为其他
都已知量,而且这时候
被
表示了),最后化简成
![]() ,其中系数均为已知数,这时候在求解
,其中系数均为已知数,这时候在求解,进而求解
,这两个参数最后就计算出来了,至于如何更新,我们开始详细通过公式说明:

其中

大家如果前面自己手推了这个式子不难理解,这里就不详解了,继续往下:
由等式约束可知:
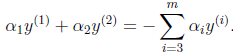
因为在这里把、
看做未知数,其他看做已知数,因此等式右边可以使用一个常数
来代替即:
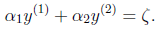
继续化简,把 看做因变量,
看做自变量,用
表示
:
把这个式子带回上面目标表达式得到关于的一元二次方程即:
求关于一元二次方程的极值大家都知道求倒,直接对求导并令其等于0即可:

通过上式可求得,带到下面的式子即:
得到的值,此时分别记为
、
,优化前的解记为
、
,因为其他的
参数均为已知的,又有等式约束为:

无论新旧值他们都要遵守这个约束即(常数其实就是):

下面就是如何化简求出、
呢?只要把上面的求导式子中的v1和v2求出问题就解决了,下面给出求v1和v2的过程:
还记的我们最初的目标函数是这个:,把通过对w、b求导得出的w值代入这个目标函数为:

表示样本
的预测值,
表示样本
的真实值,定义
表示预测值与真实值之差为 :
又因为
大家注意此时i是1,2,j是从3开始的到N,那么下面这个式子j(式子里的i)从1开始的,把代入,然后观察式子, 下式能否拆开呢?是不是可拆成含
的式子呢?
我把上式的i使用j代替了。上式把求和拆成两项可以吧,两式等价,我们看看下式中间求和项和上面的vi一样吗? 一 样的,因此可以求出v1和v2了。
即v1和v2可以表示为:
把求出来的代入上面的求导公式里,同时化简后使用代替:
代入进来;
化简得:(注意这里的求出的、
是未满足约束条件的占时使用
代替)
使用代替,并使用
代替:

下面加入约束项,继续推倒:
约束项我们在SMO算法中讲解的很详细,不懂的建议好好看一下,保证你能看明白,我把那个约束图详解了,好,我们继续:
然后考虑约束 0 ≤ ≤ C 可以得到
的解析解为:

画出图如下(之前的文章如果看懂了这里就很简单了。我直接上图了):

根据 y j 同号或异号,可得出两个上、下界分别为:

所以:

简单总结一下就是在约束范围内 仍然取这个计算出的值,但是如果超过这个范围。则直接取L或者H。
根据下面的公式计算出:
进而得到:

大家可能会有疑问就是为什么是y1*y2,其实很简单,因为y1和y2要么是1要么是-1,乘和除是一样的。
下面我们考虑一下临界条件:但是在如下几种情况下,
需要取临界值L或者H.

也可以这样理解:
对下面的式子即目标求二阶导数:
就是这个式子:
当η<0时,目标函数为凸函数,没有极小值,极值在定义域边界处取得。
当η=0时,目标函数为单调函数,同样在边界处取极值。
计算方法:
当和
时,代入求
的式子中求出
和
,其中
:
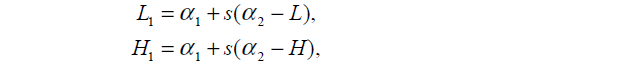
代入原目标式子得到 和
比较二者大小,
取较小的对应边界点(因为目标是取极小值,当然取小的那个了)
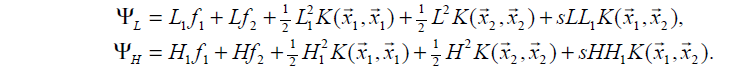
其中:
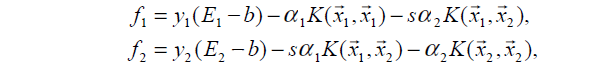
启发式选择变量:
第一个变量的选择称为外循环,首先遍历整个样本集,选择违反KKT条件的作为第一个变量,接着依据相关规则选择第二个变量(见下面分析),对这两个变量采用上述方法进行优化。当遍历完整个样本集后,遍历非边界样本集(0<
<C)中违反KKT的
作为第一个变量,同样依据相关规则选择第二个变量,对此两个变量进行优化。当遍历完非边界样本集后,再次回到遍历整个样本集中寻找,即在整个样本集与非边界样本集上来回切换,寻找违反KKT条件的
作为第一个变量。直到遍历整个样本集后,没有违反KKT条件
,然后退出。
边界上的样本对应的=0或者
=C,在优化过程中很难变化,然而非边界样本0<
<C会随着对其他变量的优化会有大的变化。

上面是KKT条件,那么什么是违反KKT条件呢?下面便是违反KKT条件的可能:

第二个变量的选择:

首先在非边界集上选择能够使函数值足够下降的样本作为第二个变量,
如果非边界集上没有,则在整个样本集上选择第二个变量,
如果整个样本集依然不存在,则重新选择第一个变量。
b值的确定:
下面的(5)式就是这个式子:
在根据下面这个式子就可以完成b的更新:
通过上面这两个式子便可以看懂下面对b进行更新的推倒:

主要参考了这篇文章
写吐了,下面在代码中在详细解释