上篇我们讲到,线性和非线性都转化为求解的问题即:

求解的方法就是SMO算法,下面详细介绍SMO算法:
在讲解SMO算法之前先说明一下讲解思路,首先先帮助大家理解这个式子,说明推倒的过程细节,然后和原论文对照,本文不打算刚开始就深入数学公式,先带大家感性认识一下SMO的算法实现过程,通过语言描述继续讲解,让大家对该算法有一个整体的认识 ,然后在循序渐进深入数学公式,吃透原理,这样符合知识的接受过程。
首先我们需要先明确上式中的字母是什么意思,其中是拉格朗日乘子,这个大家都知道,y是分类标签只取值1,-1,x是分类数据了,那么为什么会出现
,原因在哪呢?大家需要搞清楚这个来源才知道他们代表什么意思,才知道如何进行运算,在这里我把前面的推倒公式拿过来,简单讲解一下来源,然后给出自己展开的式子。

从倒数第二行,大家可以看到第一项我们可以看做一个含有未知数的常数项,第二项大家感觉是不是很眼熟即,向量的转置乘以本向量这就是求內积啊,只是说这里的A不简单而已,两个i不是同时变化的,因此为了方便把其合在一起,而合在一起的前提是需要表现两个i不一样,因此引入了j以示区别,至于为什么不一样,举一个简单的例子,因为里面是求和,大家各自展开求和在相乘,举个例子,含有三项的:
(a1 + a2 + a3)* (a1 + a2 + a3)= + a1*a2 + a1+a3 + a2*a1 +
+ a2*a3 + a3*a1 + a3*a2 +
= +
+
+ 2a1*a2 + 2a1*a3 + 2a2*a3
求和后各自展开,结果是上式,如果直接把两个i合并为一个i,那么化简会是什么样呢?
其实就只有平方项了即:+
+
之所以讲解这个,原因是希望大家能拿笔自己推一下上面的式子,同时按照下面的要求展开试试,虽然没必要推这些,但是如果去做一下,你会发现数学的推倒很有助于理解,同时这种“复杂”的式子其实还好,强化学习中的数学推倒比这里复杂多了,所以建议大家以后遇到数学公式尽量自己推一遍,比你看几遍有用的多,好了,废话不多说,把上面的结果按如下要求展开,
把和
看做未知数,其他的
看做已知数进行展开,我先给出自己推倒的(讲真编辑这个式子很耗费时间,我查了一下网上其他人的推到感觉有点问题,所以打算自己推倒一下,为了确认自己正确把原论文读了一下,是正确的):

先令 ------------为內积,为了大家能看懂就做这一个假设:
其中最后一项是常数项,因为除了和
为未知数,其他的
都为已知数,上面分解过程和上面举得小例子是一样的,在这里需要强调的是,原著论文的推到公式结果和这个不同,是因为他的前提不同,为给大家对比,同时知道为什么经常出现那种推到的原因,在这里再说明一下到目前为止还没涉及到smo知识,只在给大家整理一下推倒思路,因为只要把这些搞懂,推倒才有可能,下面给出原著作者论文的推倒过程:
首先他假设的分离平面就和我们不一样,但是道理都是一样的:

与我们之前的 是一样的意思
他的优化目标相同即:
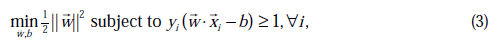
经过引入拉格朗日因子和对偶后再求对w、b求导为:

其实到这里就和我们的形式是一样的,只是正负号位置不一样的,所以极值就是求极小值了,这也是差异的原因继续往下:
加入松弛变量以后:

到这里就是我们最后的求解式子了,有点不同,但是原理都是一样的
把和
看做未知数,其他的
看做已知数进行展开为:
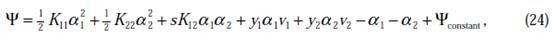
我和他展开的是差不多的,只是正负号问题,原因上面讲了,在查看相关的推倒博客,发现好多人目标是我们定义的目标,分解后就是这个结果,真不知道如何来的,所以自己动手推了一遍,形式和原著一样,结果只是正负号位置不同,因此在这里特此说明一下,下面就开始smo算法,这些都是理解基础,只有知其所以然才能往下进行。
好,我们再回到这个式子
一般含有2n个未知数的解不好求,常用解法一般都不可行,如果是你我可能都没办法了,但是微软的算法工程师John C. Platt在1998年提出了这个解决方法,是目前解决该问题最有效的方法,他的解决方法是什么呢?其实理解很简单,就是那么多变量,我先任意定两个变量为未知的,其他
任意赋值给定为已知,例如我们先假设
和
是未知的,他的均为已知,那么通过等式(
)用
表示
,带回上式,此时未知数只有
,因此化简后是一个含
的二次函数(因为其他
都已知量,而且这时候
被
表示了),为了更明显我把前面化简的式子拿过来大家看看就知道了:
大家使用 表示
,会发现只剩下
了而最高为两次,这时候对L求极值就是简单的二次函数求极值问题,当然我们需要在约束条件下进行求解,求出
后也就可以顺利的求出
,这个时候根据启发式选择方法(后面会讲)在任意选择两个进行求解(在约束条件下),就这样不停的迭代,直到每个参数基本上不在变化了,最优解就求出来,然后再求w,b,当然大概流程是这样,但是实际要比这复杂的多,如果不打算深入理解的到这里就可以了,下面就通过数学公式进行全面讲解。
在深入讲解之前还需要看一下我们需要优化的函数约束条件所代表的物理意义:
在前面我们曾说过,如果没有引入松弛变量,是可以取到无穷大,即在分类错误的情况下即:
如果正确分类,则=0不影响我们的求极值,此时的约束条件为:
如果在边界线以内呢?那就是等于1的情况,此时 ,约束条件为:
那么假如松弛因子呢?形式差不多,只是 有了上界,其中
:
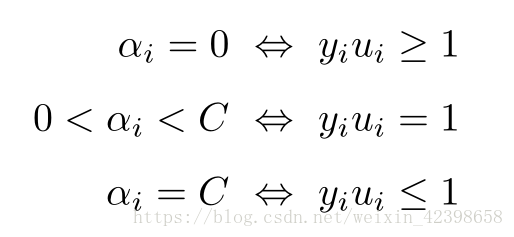
上面的条件也就是kkt条件(KKT条件大家没忘吧?忘记的回到前面再看看),下面还是把和
看做未知数,其他为已知进行讲解,套公式前还需把
、
的范围求出(约束条件),这里大家都知道那个图,但是没有细讲为什么就得出那个图了,可能其他博主认为大家的数学水平很高吧,在这里我将详细讲解这个图,然后推出
、
的取值范围:
其实限制、
取值的就是上面的最后两行的约束,同时为什么每次只取两个
,原因也在这里,因为如果只取一个未知数,那么这个未知数根据上面最后两行的约束可以直接求出来了,所以需要取两个未知数,那么上面可以化简成如下的式子(不想编辑公式了,大家体谅一下,意思都是一样的,只是下表不同):
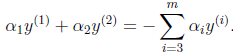
这个式子很简单,就是把最后那个约束条件展开,只有 、
是未知的,其他均为已知的,因此为了方面,可将等式右边标记成实数值
,则:
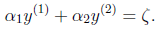
当为异号时,也就是一个为1,一个为-1时,他们可以表示成一条直线,斜率为1。如下图:

首先为异号,即1和-1,因此上式可以写为
,而约束条件就是
,此时把
看做自变量,
看做因变量,此时可以写为:
,同时两个
都满足
,因此约束条件就为上图中的正方形区域内了。
此时的的取值就有一个范围了,最大值和最小值。我们先看最小值的情况:
其中上面的两条线代表的是一个函数只是不同情况而已,也因此最大值和最小值是一个不确定数,需要分情况讨论,首先我们看看最小值的情况,大家看看上图我画圈的L1和L2,这就是最小值的取值可能了,我们先看看L1。此时L1取值为0,这时候蓝线左右移,只要不超过正方形的对角线是不会影的取值的,即此时
恒取0,一旦超过对角线左移后就到达红线的可能,此时
的取值就是就是L2,计算出L2即可(就是L2的坐标(0,-
),此时
使用
、
表示)为:
-
这时候就取二者的较大值即:,同理最大值H也是如此计算的,下面给出总体的取值范围:

同理当为异号时:

到这里我们就把的约束条件找到了,下面就是利用
表示
,并代入前面展开的式子里:
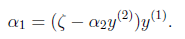
在带入上面推倒的式子里,如果大家前面自己推倒了这里就很简单了,带进去,我就不带进去了,直接截图了:
可以表示成![]() 。其中a,b,c是固定值。这样,通过对W进行求导可以得到
。其中a,b,c是固定值。这样,通过对W进行求导可以得到![]() ,然而要保证
,然而要保证![]() 满足
满足![]() ,我们使用
,我们使用![]() 表示求导求出来的
表示求导求出来的![]() ,然而最后的
,然而最后的![]() ,要根据下面情况得到:
,要根据下面情况得到:
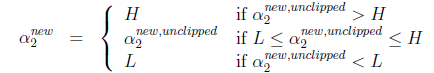
此时就可以更新好了 ,通过
计算的到
这样两个即计算出来了,此时除了b都计算出来了,而b的计算不容易,这里我先简述一下,然后给出公式,大家尝试理解一下:
b每一步都要更新,因为前面的KKT条件指出了![]() 和
和![]() 的关系,而
的关系,而![]() 和b有关,在每一步计算出
和b有关,在每一步计算出![]() 后,根据KKT条件来调整b。
后,根据KKT条件来调整b。
其中
b有以下几种可能具体参考这篇博文,其中上面的图和公式大部分来源这篇博客,特此说明,最后我没有详解更新过程,这部分我打算放在后面代码的实现过程进行详解,在那里可以详细的讲解该部分,在这里大家只需要理解是如何计算拉格朗日参数的,整个SMO的算法思想理解就可以了,思想才是关键。
下面给出启发式变量的选择,简单来说就是选择任意两个变量的原则是以优先,如果
或者
进行迭代,最后结果不会有什么变化,下面给出那篇文章的解说:

到这里基本SMO原理就结束了,但是还有很多问题需要解决,例如实际到底是如何更新的?建议多读读那篇论文,最关键的问题是下图的计算问题
后面的的计算问题,如果维度低还好,但是如果维度很高计算量就很恐怖了,如何解决呢?支持向量机之所以很强大就在于它趋向完美,这个可以通过核函数进行解决,下篇将进行详解。
本篇结束时写点感想,通过这一列推倒我们发现解决问题的思路和出发点,这是我们需要好好体会和理解的地方,如果遇到很棘手的问题的,一般都可以通过相对较简单的方法进行解决,只是这个‘简单’的方法没那么容易想到,这需要我们很广的知识领域,同时需要较好的数学推倒能力和算法理解能力,所以搞算法数学是基础。