版权声明:本文为博主原创文章,未经博主允许不得转载。转载请注明出处:http://blog.csdn.net/autocyz?viewmode=contents——autocyz https://blog.csdn.net/autocyz/article/details/51614178
反向传播算法是多层神经网络的训练中举足轻重的算法,本文着重讲解方向传播算法的原理和推导过程。因此对于一些基本的神经网络的知识,本文不做介绍。在理解反向传播算法前,先要理解神经网络中的前馈神经网络算法。
前馈神经网络
如下图,是一个多层神经网络的简单示意图:
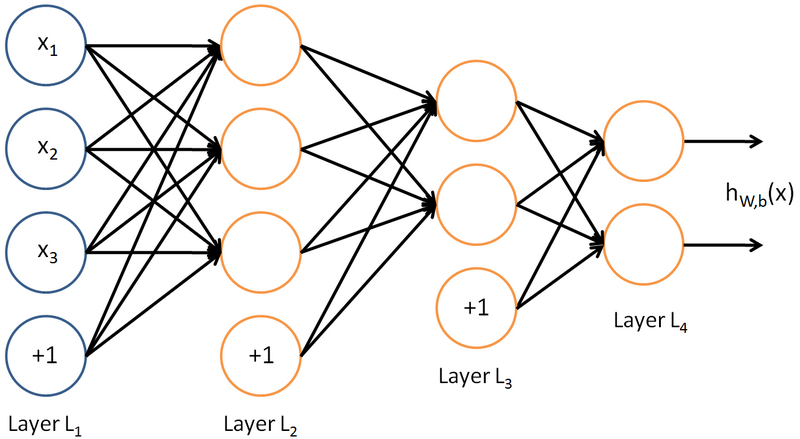
给定一个前馈神经网络,我们用下面的记号来描述这个网络:
L
:表示神经网络的层数;
nl
:表示第
l
层神经元的个数;
fl(∙)
:表示
l
层神经元的激活函数;
Wl∈Rnl×nl−1
:表示
l−1
层到第
l
层的权重矩阵;
bl∈Rnl
:表示
l−1
层到
l
层的偏置;
zl∈Rnl
:表示第
l
层神经元的输入;
al∈Rnl
:表示第
l
层神经元的输出;
前馈神经网络通过如下的公式进行信息传播:
zl=Wl⋅al−1+blal=fl(zl)
上述两个公式可以合并写成如下形式:
zl=Wl⋅fl(zl−1)+bl
这样通过一层一层的信息传递,可以得到网络的最后输出
y
为:
x=a0→z1→a1→z1→⋯→aL−1→zL→aL=y
反向传播算法
在了解前馈神经网络的结构之后,我们一前馈神经网络的信息传递过程为基础,从而推到反向传播算法。首先要明确一点,反向传播算法是为了更好更快的训练前馈神经网络,得到神经网络每一层的权重参数和偏置参数。
在推导反向传播的理论之前,首先看一幅能够直观的反映反向传播过程的图,这个图取材于Principles of training multi-layer neural network using backpropagation。如果图中看不清可以去源地址看。
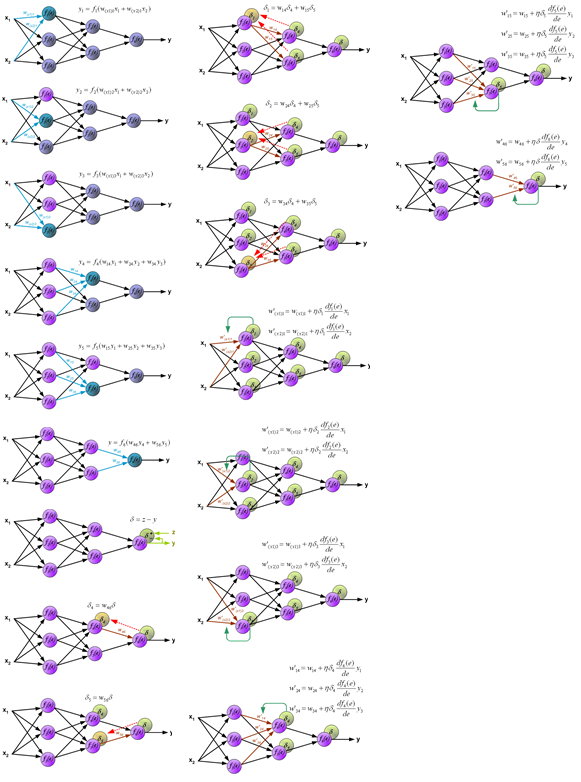
给定一组样本
(xi,yi),1≤i≤N
,使用前馈神经网络,其输出为
f(x|W,b)
,而求解
W
和
b
时,将其看成一个优化问题,优化问题的目标函数为:
J(W,b)=∑i=1NL(yi,f(xi|W,b))+12λ||w||2=∑i=1NJ(W,b;xi,yi)+12λ||w||2
这里
W
和
b
包含了每一层的权重矩阵和偏置向量,
||w||2=∑Ll=1∑nl+1j=1∑nli=1Wlij
。
我们的目标是最小化
J(W,b;x,y)
,采用梯度下降法,我们可以用如下方法更新参数:
Wl=Wl−α∂J(W,b)∂Wl=Wl−α∑i=1N∂J(W,b;xi,yi)∂Wl+αλW
bl=bl−α∂J(W,b)∂bl=bl−α∑i=1N∂J(W,b;xi,yi)∂bl
上述更新参数的公式中,重点是如何计算
∂J(W,b;xi,yi)∂Wl
和
∂J(W,b;xi,yi)∂bl
。
这里首先计算
∂J(W,b;xi,yi)∂Wl
,根据链式法则
∂J(W,b;xi,yi)∂Wl
可以写成如下形式(这里是反向传播算法的核心之处):
∂J(W,b;x,y)∂Wlij=tr⎛⎝(∂J(W,b;x,y)∂zl)T∂zl∂Wlij⎞⎠
这里,我们将
∂J(W,b;x,y)∂zl
定义为
δl
,是目标函数关于第
l
层神经元的偏导数,用来表示第
l
层的神经元对最终误差的影响。
现在上述公式中的
∂J(W,b;x,y)∂zl
用
δl
来表示,第二项中的
zl=Wl⋅al−1+bl
,所以:
∂zl∂Wlij=∂(Wl⋅al−1+bl)∂Wlij=⎡⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢0⋮a(l−1)j⋮0⎤⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥←第i行
所以前面要求的
∂J(W,b;x,y)∂Wlij
对应的结果表达为:
∂J(W,b;x,y)∂Wlij=δlia(l−1)j
所以梯度下降法中的:
∂J(W,b;x,y)∂Wl=δl(a(l−1))T
同理,
∂J(W,b;x,y)∂bl=δl
上述的所有推导得到的结果是将梯度下降法中的表达式用误差项
δl
来表示,下面就要看看
δl
的具体求解方法。
这里
δl
的求解也要用到求导中的链式法则,整个反向传播算法的核心就是两个链式法则的运用,因此这里
δl
的求解也是重中之重。
δl=∂J(W,b;x,y)∂zl(δ的定义)=∂al∂zl⋅∂z(l+1)∂al⋅∂J(W,b;x,y)∂z(l+1)(链式法则)=diag(f′l(zl))⋅(W(l+1))T⋅δ(l+1)=f′l(zl)⊙(W(l+1))Tδ(l+1)
现在分析上述链式法则中三项结果的由来:
对于第一项
∂al∂zl
,因为
al=fl(zl)
,而
fl(⋅)
是按位计算的函数,因此:
∂al∂zl=∂fl(zl)∂zl=diag(f′l(zl))
对于第二项
∂z(l+1)∂al
,
z(l+1)=W(l+1)⋅al+bl
,所以
∂z(l+1)∂al=(W(l+1))T
至此,从上述公式可以看出,第
l
层的误差项
δl
可以通过第
l+1
层的误差项计算得到。这就是误差反向传播的真谛。而反向传播算法的含义是:第l层的一个神经元的误差项是所有与该神经元相连的第l+1层的神经元的误差项的权重和,再乘上该神经元的激活函数的梯度。
在计算每一层的误差项之后,我们就计算每一层的梯度了。所以神经网络的训练过程可以分为如下三步:1、首先前馈计算每一层的状态和激活值,直到最后一层;2、反向传播计算每一层的误差;3、计算每一层参数的偏导数,并更新参数。