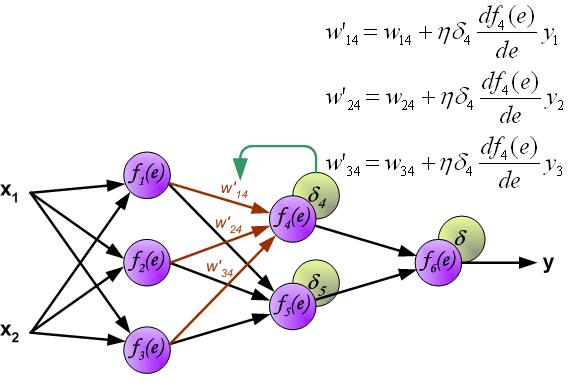
首先说这个图解的优点:先形象说明了forward-propagation,然后说明了error backward-propagation,最后根据误差和梯度更新权重。没错这是backprop,又非常直观,但是从前的backprop了。
backprop的发展路线大概是,1974年有个Harvard博士生PaulWerbos首次提出了backprop,不过没人理他,1986年Rumelhart和Hinton一起重新发现了backprop,并且有效训练了一些浅层网络,一下子开始有了名气。那个时候的backprop从现在看来并不是个很清晰的概念,把梯度和更新一块打包了,从这点看来和我贴出来的图是一回事。如果有看过mitchell机器学习教材的同学可能也会觉得下面的图眼熟。
随着神经网络的继续发展,到了深度学习大行其道的今天,更新权值的思路其实变得更简单粗暴了。概括一下就是,把原来打包式的做法拆开成了1)求梯度;2)梯度下降。所以现在我们再提到backprop,一般只是指第一步:求梯度。这就是为什么好多答案直接说就是个链式法则,因为确实就是链式法则。
不过个人觉得还是有可以直观理解的一些点:
1)链式法则的直观理解的,之所以可以链式法则,是因为梯度直观上理解就是一阶近似,所以梯度可以理解成某个变量或某个中间变量对输出影响的敏感度的系数,这种理解在一维情况下的直观帮助可能并不是很大,但是到了高维情况,当链式法则从乘法变成了Jacobian矩阵乘法的时候,这个理解起来就形象多了。神经网络中的链式法则恰好都几乎是高维的。
2)Computational graph。最高票答案和
的答案中都有提到,就不赘述,其实就是计算代数中的一个最基础办法,从计算机的角度来看还有点动态规划的意思。其优点是表达式给定的情况下对复合函数中所有变量进行快速求导,这正好是神经网络尤其是深度学习的场景。现在主流深度学习框架里的求导也都是基于Computational Graph,比如theano,torch和tensorflow,Caffe也可以看做是computaiona graph,只不过node是layer。总结:图中的确实是backprop,但不是深度学习中的backprop,不过backward的大体思想是一样的,毕竟误差没法从前往后计算啊。
=========== update: 2016.10.7 ===========
原答案:
这大概是题主想要的吧(多图):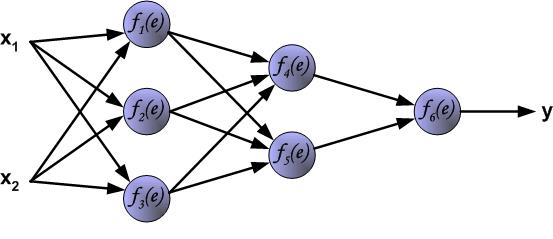

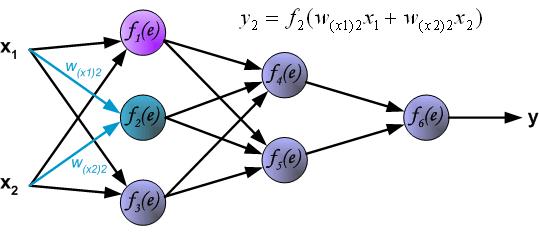
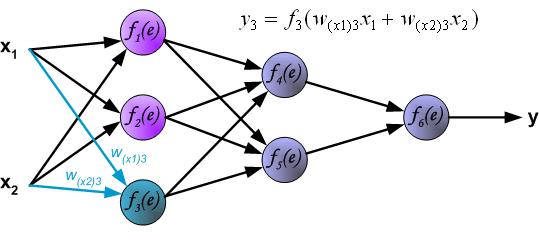

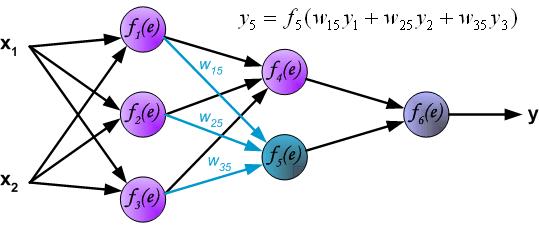



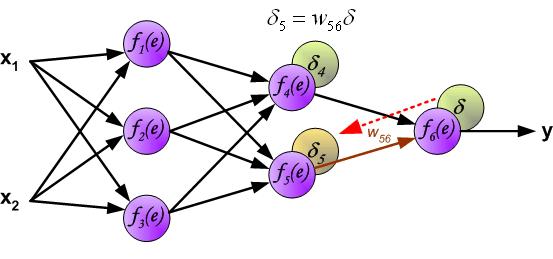

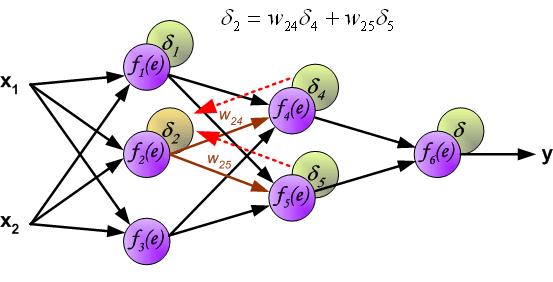

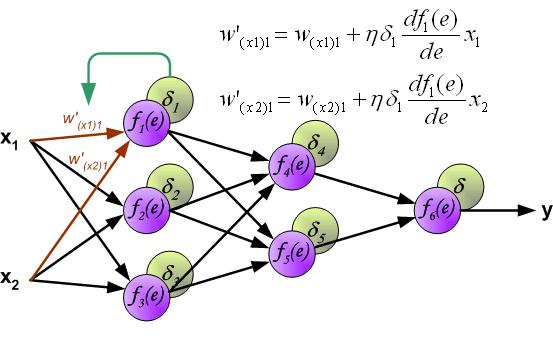

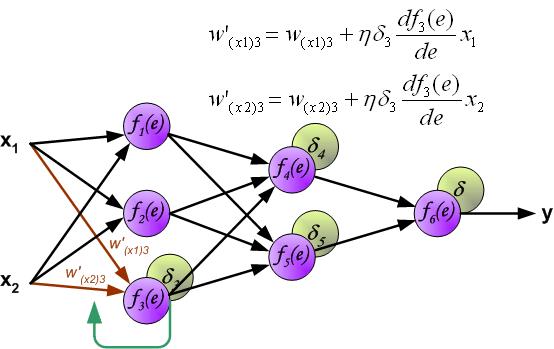


链接:https://www.zhihu.com/question/27239198/answer/43560763