BackPropagation算法是多层神经网络的训练中举足轻重的算法。
简单的理解,它的确就是复合函数的链式法则,但其在实际运算中的意义比链式法则要大的多。
背景知识
简单表达式和理解梯度
从简单表达式入手可以为复杂表达式打好符号和规则基础。先考虑一个简单的二元乘法函数。对两个输入变量分别求偏导数还是很简单的:
导数的意义:函数变量在某个点周围的极小区域内变化,而导数就是变量变化导致的函数在该方向上的变化率。
注意等号左边的分号和等号右边的分号不同,不是代表分数。相反,这个符号表示操作符被应用于函数
,并返回一个不同的函数(导数)。对于上述公式,可以认为
值非常小,函数可以被一条直线近似,而导数就是这条直线的斜率。换句话说,每个变量的导数指明了整个表达式对于该变量的值的敏感程度。比如,若
,则
,
的导数
。这就说明如果将变量
的值变大一点,整个表达式的值就会变小(原因在于负号),而且变小的量是
变大的量的三倍。通过重新排列公式可以看到这一点(
)。同样,因为
,可以知道如果将
的值增加
,那么函数的输出也将增加(原因在于正号),且增加量是
。
函数关于每个变量的导数指明了整个表达式对于该变量的敏感程度。
如上所述,梯度是偏导数的向量,所以有
。即使是梯度实际上是一个向量,仍然通常使用类似“x上的梯度”的术语,而不是使用如“x的偏导数”的正确说法,原因是因为前者说起来简单。
我们也可以对加法操作求导:
这就是说,无论其值如何,的导数均为1。这是有道理的,因为无论增加
中任一个的值,函数
的值都会增加,并且增加的变化率独立于
的具体值(情况和乘法操作不同)。取最大值操作也是常常使用的:
上式是说,如果该变量比另一个变量大,那么梯度是1,反之为0。例如,若,那么max是4,所以函数对于
就不敏感。也就是说,在
上增加
,函数还是输出为4,所以梯度是0:因为对于函数输出是没有效果的。当然,如果给
增加一个很大的量,比如大于2,那么函数
的值就变化了,但是导数并没有指明输入量有巨大变化情况对于函数的效果,他们只适用于输入量变化极小时的情况,因为定义已经指明:
。
使用链式法则计算复合表达式
现在考虑更复杂的包含多个函数的复合函数,比如。虽然这个表达足够简单,可以直接微分,但是在此使用一种有助于读者直观理解反向传播的方法。将公式分成两部分:
和
。在前面已经介绍过如何对这分开的两个公式进行计算,因为
是
和
相乘,所以
,又因为
是
加
,所以
。然而,并不需要关心中间量
的梯度,因为
没有用。相反,函数
关于
的梯度才是需要关注的。链式法则指出将这些梯度表达式链接起来的正确方式是相乘,比如
。在实际操作中,这只是简单地将两个梯度数值相乘,示例代码如下:
# 设置输入值
x = -2; y = 5; z = -4
# 进行前向传播
q = x + y # q becomes 3
f = q * z # f becomes -12
# 进行反向传播:
# 首先回传到 f = q * z
dfdz = q # df/dz = q, 所以关于z的梯度是3
dfdq = z # df/dq = z, 所以关于q的梯度是-4
# 现在回传到q = x + y
dfdx = 1.0 * dfdq # dq/dx = 1. 这里的乘法是因为链式法则
dfdy = 1.0 * dfdq # dq/dy = 1
最后得到变量的梯度[dfdx, dfdy, dfdz],它们告诉我们函数f对于变量[x, y, z]的敏感程度。这是一个最简单的反向传播。一般会使用一个更简洁的表达符号,这样就不用写df了。这就是说,用dq来代替dfdq,且总是假设梯度是关于最终输出的。
这次计算可以被可视化为如下计算线路图像:
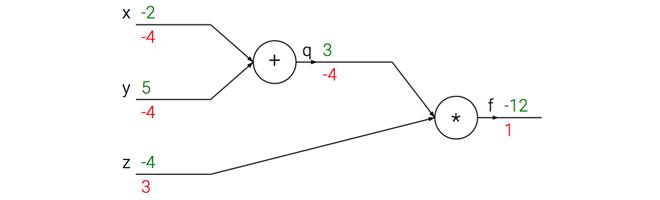
上图的真实值计算线路展示了计算的视觉化过程。前向传播从输入计算到输出(绿色),反向传播从尾部开始,根据链式法则递归地向前计算梯度(显示为红色),一直到网络的输入端。可以认为,梯度是从计算链路中回流。
简单理解
如下的神经网络

- 前向传播
对于节点来说,
如下:

接着对

类似的,我们能得到节点、
、
的输出
、
、
。
- 误差
得到结果后,整个神经网络的输出误差可以表示为:

其中就是刚刚通过前向传播算出来的
是节点
用来衡量二者的误差。
这个)
展开得到

- 后向传播
对输出层的
通过梯度下降调整
,需要求
,由链式法则:
,
如下图所示:
以上3个相乘得到梯度很多教材比如Stanford的课程,会把中间结果
记做
,表示这个节点对最终的误差需要负多少责任。所以有
。
对隐藏层的
通过梯度下降调整
,需要求
,由链式法则:
,
如下图所示:
参数
,之后又影响到
、
。
求解每个部分:,
其中,这里
的计算也类似,所以得到
。
,
相乘得到
得到梯度后,就可以对。
在前一个式子里同样可以对
进行定义,
,所以整个梯度可以写成

