logistic regression 中的反向传播 (back propagation)
梯度下降
在《深度学习中的 logistic regression》 一文中,最后我们得到了 logistic regression 的 cost function :
J(ω,β)=m1i∑L(y^,P(y∣x))
接下来只需要用梯度下降求解 cost function 的极小值。
现在我们在 logistic regression 中有 两个参数,
z=xTω+β,权重
ω,偏置
β。
因此梯度下降为:
{}ω:=ω−α∂ω∂J(ω,β)β:=β−α∂β∂J(ω,β)
其中
α 为学习率(超参数)。
接下来的未知量只有
∂ω∂J(ω,β) 和
∂β∂J(ω,β) 。所以接下来的问题就是求解这两个值,这两个值我们会把它叫做
J(ω,β) 的梯度,记为
∇J(ω,β)。即:
∇J(ω,β)=[∂ω∂J(ω,β)∂β∂J(ω,β)]
因此我们把这个算法叫做梯度下降。
现在我们要求解梯度,就需要用到 反向传播 求梯度下降。
反向传播
我们先来看一个普遍的正向传播。
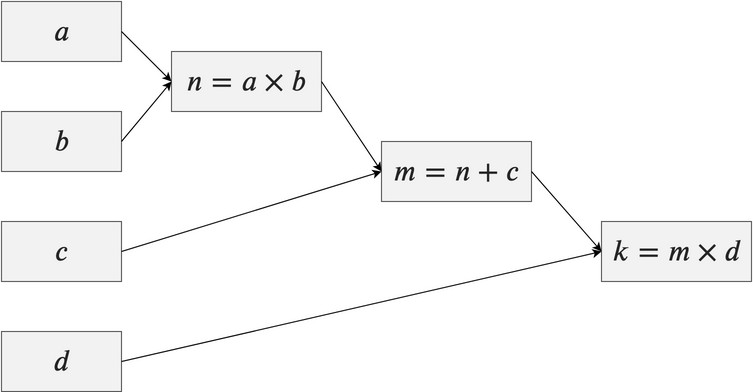
那它的反向传播长什么样呢?
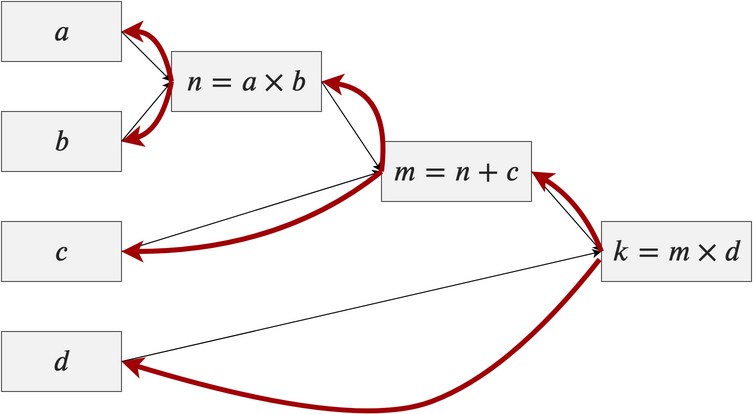
红色线就是表示的反向传播,每条线代表
我们先看一下在 loss function 前的反向传播。

这个是正向的传播,有目前的
ω 和
β 计算
z,然后通过
σ(z) 计算
y^,其中
y^ 表示
P(y=1∣x),然后通过
lossfunction 计算出 loss。
接下来如果我们已经求出 loss 了,我们要对
ω 和
β 进行修正。
也就是要求反向传播。
先把旧稿发出,未完待续。(或许没有后续???)
想被催更
