传统的机器翻译系统通常依赖于基于文本统计特性的复杂特征工程,需要投入大量工程大见他们。
神经机器翻译系统NMT,把一句话的意思映射到一个固定长度的特征向量,然后基于此进行翻译。由于NMT不再依赖于n-gram计数,而是捕捉文本更高层的含义。
基于encoder-decoder的模型
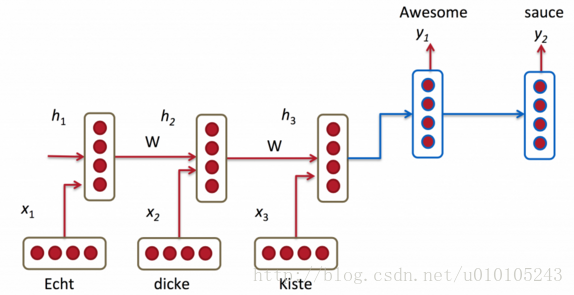
NMT系统使用RNN将源语句(比如,一句德语)编码为一个向量,然后同样用RNN将其解码为英语。
如上图中,“Echt”,”Dicke”,”Kiste”以此输入到编码器中,然后解码器开始生成翻译的语句,解码器持续依次生成生成对应的翻译,这里的h向量表示的编码器的内部状态,在解码器的那内部也有对应的隐状态;下面是较为全面的网络结构模型
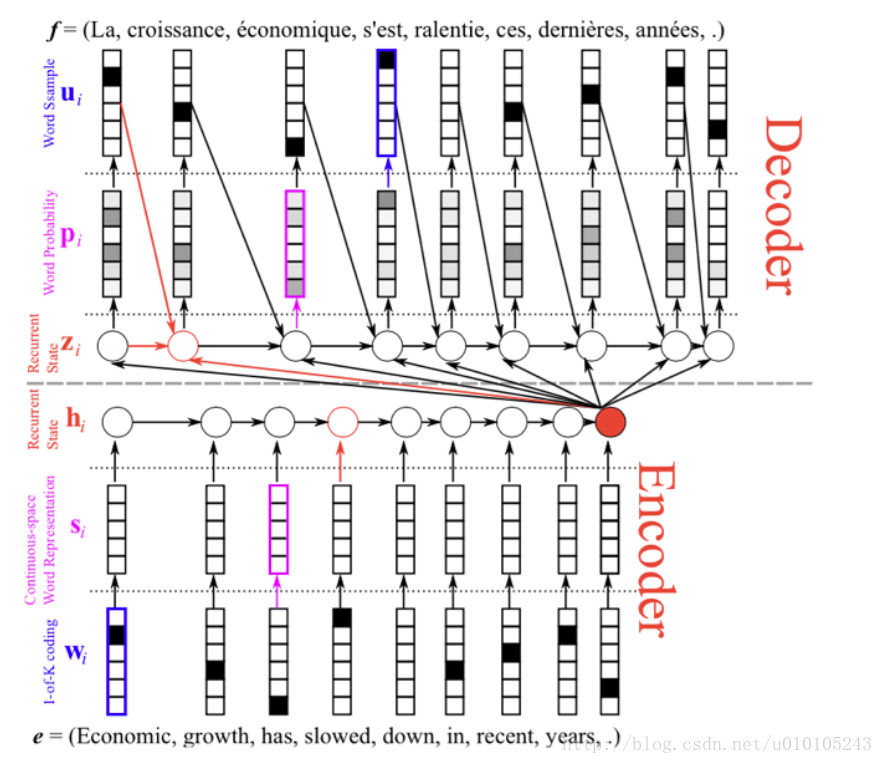
encoder-decoder模型的不足
可以看出来编码器在翻译时仅仅依赖于最后的隐藏状态,h3向量必须对源句子的所有内容进行编码,它必须充分捕捉句子的含义,这个句子就是sentence embedding;
但是,问题在于我们无法将一个很长的句子所包含的所有信息编码成一个向量,很多的细节比如位置信息等就无法捕捉到,然后解码器仅仅根据这个向量生成很完美的翻译。
假设原文句子有50个单词,英文译文的第一个单词可能与原文的第一个单词高度相关,这就意味着解码器必须考虑50步之前的信息,而且那边信息需要以某种方式编码到向量中。
RNN在处理这类长距离依赖的关系上会出现问题,LSTM理论上能够处理这类问题,但是在实际的工程中仍然是无效的,有人将源语言的语序倒置或者两次输入同一个序列发现翻译的效果好一点,这样的方式跟语言的特点有关。
Attention机制
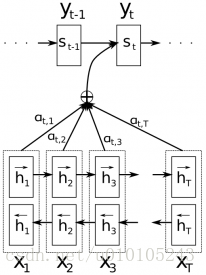
Attention机制,使得我们不需要将完整的原文句子编码为固定长度的向量,相反,我们允许解码器在每一步输出时使用原文的不同部分,尤为重要的是让模型根据输入的句子和已经生成的内容决定使用什么。
从输出端看公式:
其中
上面的公式可以理解为解码器进行解码时参考的输入部分的权重
其中
http://papers.nips.cc/paper/5847-attention-based-models-for-speech-recognition.pdf
关于权重分配的讨论: https://www.zhihu.com/question/54038778
x是输入的文本,上图中使用了双向的RNN,现在的解码器输出的词语
- 前一步的输出
- 所有输入状态的一个权重组合而不值是最后的一个状态
α 是决定每个输入状态对应输出状态的权重贡献,如果αt,2,αt,3 的值很大,这意味着解码器在生成译文的第三个词语是,会更关注与原文句子的第2,3个状态。