基于seq2seq模型的机器翻译
文章目录
前言
机器翻译的起源可以追溯到上世界80年代,那时的机器翻译主要依赖于语言学的发展,分析句法、语义、语用等。后来,研究者开始将统计模型应用于机器翻译,这种方法是基于对已有的文本语料库的分析来生成翻译结果。随着深度学习的兴起,如今神经网络开始被运用在机器翻译上,并在短短几年取得了丰硕的成果。 目前的机器翻译,其基本思想来源于Nal Kalchbrenner 和 Phil Blunsom在2013年提出的端到端编码器-解码器结构。2014 年,Sutskever等开发了一种名叫序列到序列(seq2seq)学习的方法,google以此模型在其深度学习框架tensorflow的tutorial中给出了具体的实现方法,取得了很好的效果。一、什么是seq2seq模型
Seq2Seq模型是输出的长度不确定时采用的模型,这种情况一般是在机器翻译的任务中出现,将一句中文翻译成英文,那么这句英文的长度有可能会比中文短,也有可能会比中文长,所以输出的长度就不确定了。如下图所,输入的中文长度为4,输出的英文长度为2。
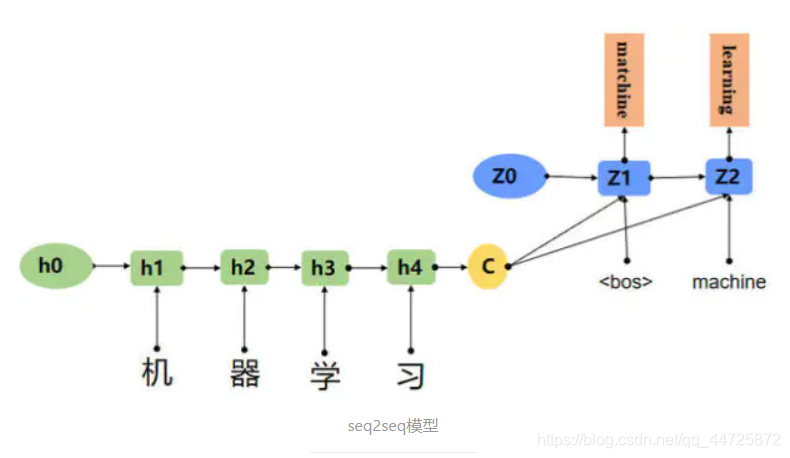
图片和解释文字参考自Seq2Seq模型概述
seq2seq模型是一种序列对序列的模型,从上面的图可以比较明显的看出,该模型由两个部分组成,如果这还不够明显,我们看看下图:
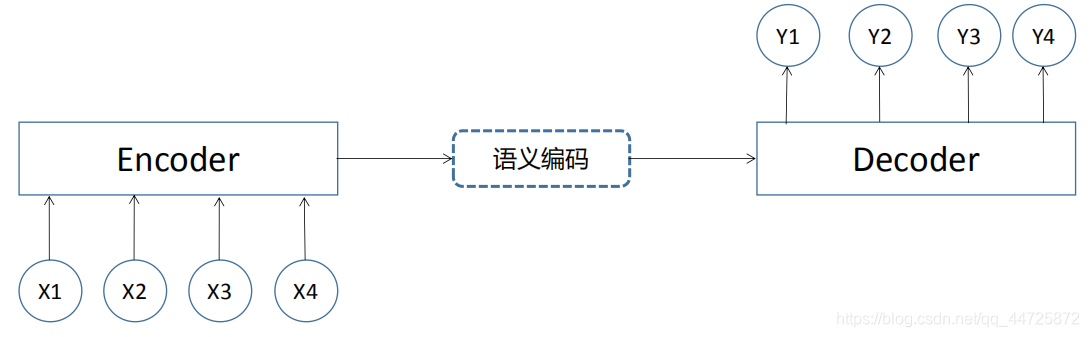
这样看起来是不是更简单了一点,seq2seq模型通过一个encoder和一个decoder组成,这两个部分都是循环神经网络模型。
基本原理是这样:Encoder结构先将输入数据编码成一个上下文向量,该上下文向量通常是Encoder的最后一个隐藏状态。Decoder将该上下文向量作为输入,对其进行解码,输出相应的目标序列。
由于Encoder-Decoder结构不限制输入和输出的序列长度,因此应用的范围非常广泛,比如:机器翻译、文本摘要、阅读理解、语音识别等。
二、机器翻译实战
1.数据集介绍和数据预处理
首先介绍一下数据集,这是一个由两万多条数据组成的txt文件,文件里面每一行都包括一个英文句子和其对应中文翻译,句子和翻译中间通过一个 \t 来分隔如下图所示:

接下来进行数据的预处理:
这是用于数据预处理函数,在之后的工作中会直接将这个文件导入主文件中。
def getdata():
with open('cmn.txt', 'r', encoding='utf-8') as f:
data = f.read()
data = data.split('\n')
data = data[:100]
en_data = [line.split('\t')[0] for line in data]
ch_data = ['\t' + line.split('\t')[1] + '\n' for line in data]
# 分别生成中英文字典
en_vocab = set(''.join(en_data))
id2en = list(en_vocab)
en2id = {
c:i for i,c in enumerate(id2en)}
# 分别生成中英文字典
ch_vocab = set(''.join(ch_data))
id2ch = list(ch_vocab)
ch2id = {
c:i for i,c in enumerate(id2ch)}
en_num_data = [[en2id[en] for en in line ] for line in en_data]
ch_num_data = [[ch2id[ch] for ch in line] for line in ch_data]
de_num_data = [[ch2id[ch] for ch in line][1:] for line in ch_data]
import numpy as np
# 获取输入输出端的最大长度
max_encoder_seq_length = max([len(txt) for txt in en_num_data])
max_decoder_seq_length = max([len(txt) for txt in ch_num_data])
# 将数据进行onehot处理
encoder_input_data = np.zeros((len(en_num_data), max_encoder_seq_length, len(en2id)), dtype='float32')
decoder_input_data = np.zeros((len(ch_num_data), max_decoder_seq_length, len(ch2id)), dtype='float32')
decoder_target_data = np.zeros((len(ch_num_data), max_decoder_seq_length, len(ch2id)), dtype='float32')
for i in range(len(ch_num_data)):
for t, j in enumerate(en_num_data[i]):
encoder_input_data[i, t, j] = 1.
for t, j in enumerate(ch_num_data[i]):
decoder_input_data[i, t, j] = 1.
for t, j in enumerate(de_num_data[i]):
decoder_target_data[i, t, j] = 1.
return encoder_input_data, decoder_input_data,decoder_target_data,ch2id,id2ch,en_data
这个函数看起来没有那么复杂,所以就简单讲讲,首先读入文件,并将文件里的英文句子和中文句子分开,再进行拆分,生成中文词典和英文词典(这里使用英文字母作为生成词向量的依据),最后将英文句子和中文句子翻译成词向量并用独热编码表示。
至此,数据预处理完成。
2.搭建模型
Encoder模型
首先对模型的Encoder部分进行搭建,为此我们需要考虑3个方面:
Encoder模型的输入是什么样子?
Encoder模型使用怎样的RNN单元?
模型的哪部分作为Decoder的输入?
模型的输入可以使用Input来设定,输入的形状要与字典长度相同:
encoder_input = Input(shape=(None,len(vocabulary)))
模型使用LSTM单元,维度设置为HIDDEN_SIZE,return_sequences字段用来决控制是否需要每一步的输出,return_states用来控制是否输出隐藏层状态。
encoder_LSTM = LTM(HIDDEN_SIZE, return_sequences=True, return_state=True,name='encoder')
Encoder使用最后一层的隐藏状态,即encoder_state_h和 encoder_state_c作为Decoder的输入:
encoder_h, encoder_state_h, encoder_state_c = encoder_LSTM (encoder_input)
Decoder模型
对Decoder部分进行搭建,我们需要考虑3个方面:
Decoder模型的输入是什么样子?
Decoder模型使用怎样的RNN单元?
模型的输出是怎样的结构?
前两步与Encoder相似,对于Decoder的输出,我们使用一个全连接层,并使用softmax激活函数将输出的向量映射到目标语言的字典上。
lstm = LSTM(HIDDEN_SIZE, return_sequences=True, return_state=True,name='decoder')
decoder_h, _, _ = lstm(decoder_inputs, initial_state=[encoder_state_h, encoder_state_c])
decoder_dense = Dense(CH_VOCAB_SIZE, activation='softmax',name='dense')
decoder_outputs = decoder_dense(decoder_h)
Decoder部分还可以使用注意力机制:
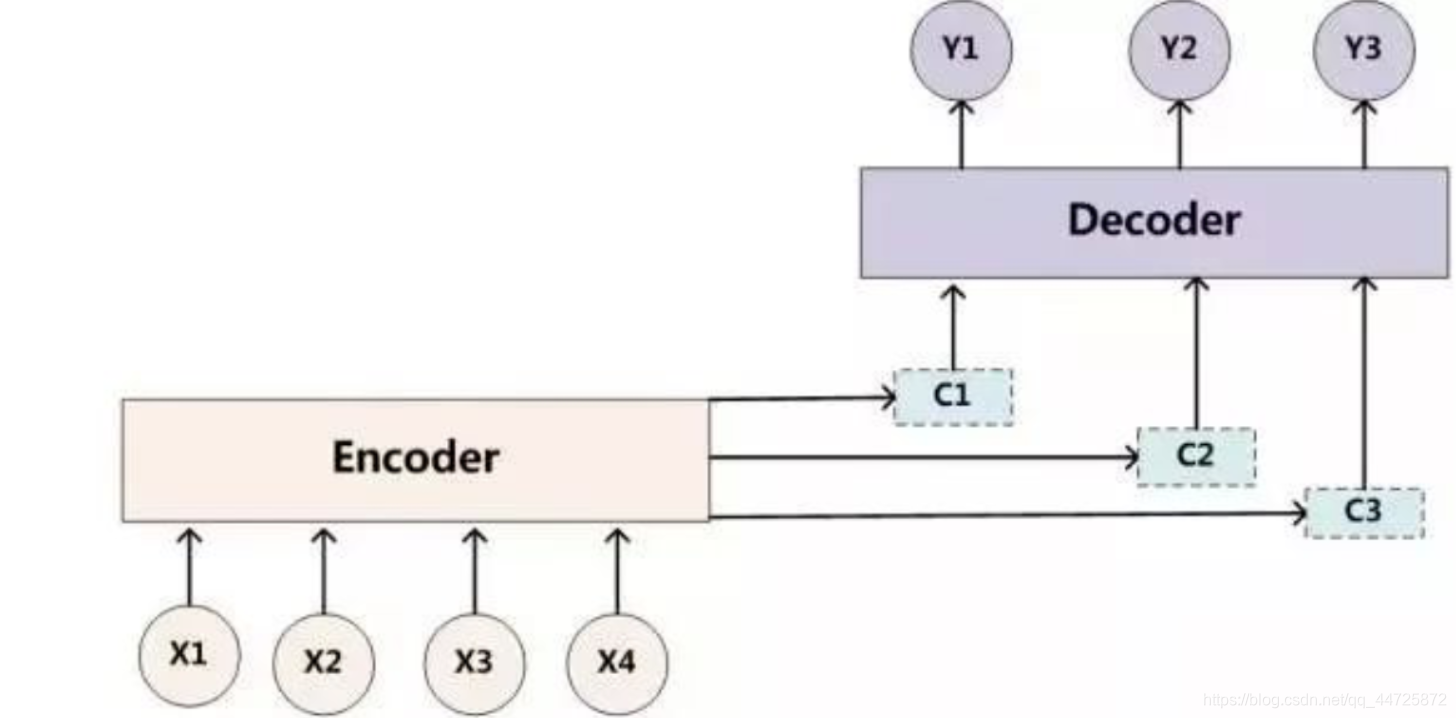
该方法通过一个attention层,将Encoder部分的每一步的输出与decoder_inputs联系起来作为decoder的输入。相当于根据序列的每个时间步将编码器编码为不同隐藏向量c,在解码时,结合每个不同的c进行解码输出,这样得到的结果会更加准确。但在这里没有用到。
3.模型训练
训练模型时,我们用Model模块将Encoder和Decoder封装,并通过optimizer选择优化器,loss选择损失函数。
model = Model([encoder_inputs, decoder_inputs], decoder_outputs)
opt = Adam(lr=LEARNING_RATE, beta_1=0.9, beta_2=0.999, epsilon=1e-08)
model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accu\fracy'])
模型在训练时,将之前预处理好的数据输入模型,并设置相应参数即可。
model.fit([encoder_input_data, decoder_input_data], decoder_target_data,
batch_size=BATCH_SIZE,
epochs=EPOCHS,
validation_split=0.2)
其中x为输入的数据,y为输出的数据。batch_size为每一批处理的序列数,epochs为训练的迭代次数,validation_split为训练集和验证集的比例。
4.建立推断模型并整理输出
建立推断模型
推断模型的建立也分为两部分,模型Encoder部分的结构与训练时完全相同,因此只需要将原来的encoder部分封装起来即可:
# Encoder inference model
encoder_model = Model(encoder_inputs, [encoder_state_h, encoder_state_c])
而Decoder部分,需要将每一步的输出作为下一步的输入:
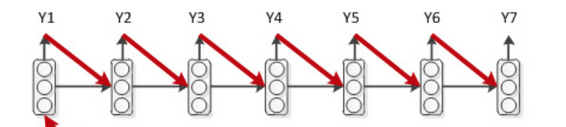
decoder
因此需要对Decoder部分重新设计。
首先确定Decoder部分的输入与输出,输入部分的大小应与Encoder输出的大小相同。
decoder_state_input_h = Input(shape=(HIDDEN_SIZE,))
decoder_state_input_c = Input(shape=(HIDDEN_SIZE,))
由于我们需要每一步的输出作为下一步的输入,因此需要将Decoder的隐藏状态和输出向量都存下来以备用。
decoder_h, state_h, state_c = decoder(decoder_inputs, initial_state=[decoder_state_input_h, decoder_state_input_c])
decoder_outputs = decoder_dense(decoder_h)
最后将Decoder的部分封装:
decoder_model = Model([decoder_inputs, decoder_state_input_h, decoder_state_input_c], [decoder_outputs, state_h, state_c])
输出整理
Decoder部分的输出是一个概率向量,它的每一位对应着字典中相应位置的概率,通常我们将输出向量中概率值最高的一位,作为预测的结果:
output_tokens, h, c= decoder_model.predict([target_seq, h, c])
sampled_token_index = np.argmax(output_tokens[0, -1, :])
在获得Encoder部分的输出后,我们需要设计一个程序结构,使得Decoder部分将每一步的输出送入下一步之中,并且当输出了终止符号或者超过最长输出序列长度时,停止程序。
while True:
output_tokens, h, c= decoder_model.predict([target_seq, h, c])
sampled_token_index = np.argmax(output_tokens[0, -1, :])
outputs.append(sampled_token_index)
target_seq = np.zeros((1, 1, CH_VOCAB_SIZE))
target_seq[0, 0, sampled_token_index] = 1
if sampled_token_index == ch2id['\n'] or len(outputs) > 20: break
结果展示
先看一下最终的代码文件:
import data_prepare
from keras.models import Model
from keras.layers import Input, LSTM, Dense, Embedding,concatenate,TimeDistributed,RepeatVector,Bidirectional
from keras.optimizers import Adam
import numpy as np
EN_VOCAB_SIZE = 47
CH_VOCAB_SIZE = 147
HIDDEN_SIZE = 256
LEARNING_RATE = 0.003
BATCH_SIZE = 100
EPOCHS = 100
encoder_input_data, decoder_input_data,decoder_target_data,ch2id,id2ch,en_data = data_prepare.getdata()
# ==============encoder=============
encoder_inputs = Input(shape=(None, EN_VOCAB_SIZE))
encoder_h, encoder_state_h, encoder_state_c = LSTM(HIDDEN_SIZE, return_sequences=True, return_state=True,name='encoder')(encoder_inputs)
# ==============decoder=============
decoder_inputs = Input(shape=(None, CH_VOCAB_SIZE))
decoder = LSTM(HIDDEN_SIZE, return_sequences=True, return_state=True,name='decoder')
decoder_dense = Dense(CH_VOCAB_SIZE, activation='softmax',name='dense')
decoder_h, _, _ = decoder(decoder_inputs, initial_state=[encoder_state_h, encoder_state_c])
decoder_outputs = decoder_dense(decoder_h)
model = Model([encoder_inputs, decoder_inputs], decoder_outputs)
opt = Adam(lr=LEARNING_RATE, beta_1=0.9, beta_2=0.999, epsilon=1e-08)
model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy'])
#模型训练
model.fit([encoder_input_data, decoder_input_data], decoder_target_data,
batch_size=BATCH_SIZE,
epochs=EPOCHS,
validation_split=0.2,verbose=0)
##################
# encoder模型和训练相同,直接封装即可
encoder_model = Model(encoder_inputs, [encoder_state_h, encoder_state_c])
# decoder部分需要重新设计
decoder_state_input_h = Input(shape=(HIDDEN_SIZE,))
decoder_state_input_c = Input(shape=(HIDDEN_SIZE,))
decoder_h, state_h, state_c = decoder(decoder_inputs, initial_state=[decoder_state_input_h, decoder_state_input_c])
decoder_outputs = decoder_dense(decoder_h)
decoder_model = Model([decoder_inputs, decoder_state_input_h, decoder_state_input_c], [decoder_outputs, state_h, state_c])
##################
for k in range(50, 100):
test_data = encoder_input_data[k:k + 1]
#对test_data进行预测
h, c = encoder_model.predict(test_data)
target_seq = np.zeros((1, 1, CH_VOCAB_SIZE))
target_seq[0, 0, ch2id['\t']] = 1
outputs = []
while True:
output_tokens, h, c= decoder_model.predict([target_seq, h, c])
sampled_token_index = np.argmax(output_tokens[0, -1, :])
outputs.append(sampled_token_index)
target_seq = np.zeros((1, 1, CH_VOCAB_SIZE))
target_seq[0, 0, sampled_token_index] = 1
if sampled_token_index == ch2id['\n'] or len(outputs) > 20: break
print(en_data[k])
print(''.join([id2ch[i] for i in outputs]))
我使用的是vscode来运行这段代码,输出的结果:
It's me.
是我。
Join us.
加入我们吧。
Keep it.
留着吧。
Kiss me.
吻我。
Perfect!
完美!
See you.
再见!
Shut up!
閉嘴!
Skip it.
不管它。
Take it.
拿走吧。
Wake up!
醒醒!
Wash up.
去清洗一下。
We know.
我们知道。
Welcome.
欢迎。
Who won?
谁赢了?
Why not?
为什么不?
You run.
你跑。
Back off.
往后退点。
Be still.
静静的,别动。
Beats me.
我一无所知。
Cuff him.
把他铐上。
Drive on.
往前开。
Get away!
滾!
Get away!
滾!
Get down!
趴下!
Get lost!
滾!
Get real.
醒醒吧。
Good job!
干的好!
Good job!
干的好!
Grab Tom.
抓住汤姆。
Grab him.
抓住他。
Have fun.
抓住他。
He tries.
他跑。
Humor me.
抱抱汤姆。
Hurry up.
他跑。
Hurry up.
他跑。
I forgot.
我同意。
I resign.
我退出。
I'll pay.
我迷失了。
I'm busy.
我沒事。
I'm cold.
我老了。
I'm fine.
我沒事。
I'm full.
我沒事。
I'm sick.
我老了。
I'm sick.
我老了。
I'm tall.
我老了。
Leave me.
他跑。
Let's go!
留着吧。
Let's go!
留着吧。
Let's go!
留着吧。
Look out!
找到汤姆。
总结
简单的看看上面展示的结果,可以看到大部分的翻译还是比较正确的例如:It's me.、Join us.等等,当然也有一些比较差的例如结果的后半段。尤其是部分英文总是翻译成汤姆,很有意思,我看了看数据集里确实汤姆占了挺大的比重,可能是因此所以有些单词会莫名其妙的翻译成汤姆。 结果里还有一个比较有意思的翻译,就是I'm cold.这条,本来应该是我冷,但却翻译成了我老了;转念一想把c去掉不就是我老了的意思了嘛。 总的来说,模型整体的表现还是不错的。博客来自EduCoder平台的机器翻译实训项目,加上一些自己的理解而写。