原论文地址:https://arxiv.org/pdf/1409.0473.pdf
NEURAL MACHINE TRANSLATION
BY JOINTLY LEARNING TO ALIGN AND TRANSLATE
Dzmitry Bahdanau
Jacobs University Bremen, Germany
KyungHyun Cho Yoshua Bengio∗
Universite de Montr ´ eal
摘要
神经机器翻译是最近提出的机器翻译方法,与传统的统计机器翻译不同,神经机器翻译的目标是要构建一个单一的神经网络,可以通过联合调试这个神经网络使其翻译性能最大化。最近提出的神经机器翻译模型通常都属于编码器-解码器家族系列,编码器把原序列编码成定长向量,解码器用这个定长向量生成翻译结果。在这篇论文中,我们推测定长向量的使用是编码器-解码器架构的模型中提高性能的瓶颈所在,因此我们对该架构进行了扩展,使得模型可以从原序列中自动(软)搜索那些和预测的目标单词相关的序列部分,而不必显式的把这些部分转换成固定死的分段。使用这个新方法的模型的翻译性能,可以与既存的基于短语的英法翻译的最佳系统的性能相媲美。另外,量化分析结果表明,由模型找出的(软)对齐与我们的直觉不谋而合。
1 介绍
神经机器翻译最近由Kalchbrenner and Blunsom (2013), Sutskever et al. (2014) 以及Cho et al. (2014b)提出的新的机器翻译方法。不像传统的统计基于短语的翻译系统(例如Koehn et al., 2003)那样,由很多单独调试的小的子组件构成,神经机器翻译尝试构建一个单一的大型神经网络,读入原序列,输出正确的翻译结果。
大多数神经机器翻译模型都属于编码器-解码器家族系列(Sutskever et al., 2014; Cho et al., 2014a),对每一种语言都有一套编码器-解码器,或者包含一个语言特定的编码器作用在每个句子上,然后对每个句子的所有输出结果进行比较(Hermann and Blunsom, 2014)。编码器读取原序列并编码成一个定长向量,解码器根据这个定长向量输出翻译结果。整个编解码器系统,由翻译前后语言对的编码器和解码器构成,对其联合训练使得给定一个句子其输出正确翻译的概率得到最大化。
编码器-解码器方法的一个潜在的问题是,一个神经网络需要能够把原始句子的所有必要信息压缩进一个定长向量,这对于处理长句子来说很困难,特别是那些比训练语料更长的句子。Cho et al. (2014b)展示了实际上随着输入句子长度的增长,基本的编码器-解码器的性能会迅速恶化。
为了解决这个问题,我们对编码器-解码器模型进行了扩展,扩展后的模型会同时学习对齐和翻译。我们提出的模型每次生成一个翻译结果单词之前,都会从原句子中(软)搜索一组位置,与翻译结果单词最相关的信息都集中在这些位置上,然后模型根据与这些原位置信息关联的上下文向量以及目前为止所有已经生成的单词,来生成当前的目标单词。
这个方法与基本的编码器-解码器模型相比最具特色的就是,该方法不会尝试把整个输入句子编码成一个定长向量。相反的,它把输入句子编码成一个向量序列并适应性的选择其中的一个子集用来解码成翻译结果。不管句子有多长,都不得不压缩原句的所有信息至一个定长向量,使得长句子翻译陷入了困境。我们的方法把神经翻译模型从这种困境中解脱出来,因此我们的模型能够更好的处理长句。
这篇论文展示了,与基本的编码器-解码器方法相比,我们推荐的同时学习对齐和翻译的方法使得翻译性能得到了显著的提高。对于任意长度的句子都能观察到性能的提高,对于长句子提高尤其明显。在英法翻译任务中,使用我们推荐的方法的单一模型,或可比或接近于传统的基于短语的系统性能。此外,定量分析结果显示我们推荐的模型发现了原句和翻译结果之间语言学上貌似合理的(软)对齐方式。
2 背景: 神经机器翻译
从概率的观点来说,翻译相当于寻找一个目标句y,使得在给定原句x的情况下y的条件概率最大,也就是arg max p(y|x)。在神经机器翻译中,我们用平行训练语料拟合一个参数模型,使得训练语句对的概率最大,一旦翻译模型学到了条件概率分布,那给定一个原句,就能够通过搜索条件概率最大的那个句子,得到对应的翻译结果。
最近,有几篇论文提出使用神经网络直接学习这种条件概率分布(例如:Kalchbrenner and Blunsom, 2013; Cho et al., 2014a; Sutskever et al., 2014; Cho et al., 2014b; Forcada and Neco, 1997)。这种神经机器翻译方法通常包含两部分,第一部分把原句x编码,第二部分解码成目标句y。例如,(Cho et al., 2014a)和(Sutskever et al., 2014)使用了两个循环神经网络(RNN),把变长原句编码成一个定长向量,然后再把定长向量解码成变长目标句。
尽管还是一个非常新的方法,神经机器翻译已经展示了一个有前途的结果。Sutskever et al. (2014)报告指出基于带有LSTM单元的RNNs的神经机器翻译,在英法翻译任务中,达到了传统的基于短语的翻译系统的最佳性能(这里的最佳性能是指,没有使用任何神经网络组件的传统的基于短语的系统)。通过给既存翻译系统添加神经组件,比如为短语列表中的短语对打分(Cho et al., 2014a),或者重新排列候选翻译(Sutskever et al., 2014),其性能已经超过了前面提到的最佳性能。
2.1 RNN 编码器-解码器
这里我们简单描述一下称作RNN 编码器-解码器的框架,这个框架由Cho et al. (2014a) 和 Sutskever et al. (2014)提出,基于该框架,我们构造了一个可以同时学习对齐和翻译的新架构。
在RNN编码器-解码器框架中,编码器读入输入句子,它是一个向量序列x = (x1; · · · ; xTx),将其转换成一个向量c(尽管大多数之前的工作(例如:Cho et al., 2014a; Sutskever et al., 2014; Kalchbrenner and Blunsom, 2013)都把一个变长输入句子编码成一个定长向量,其实并不是必须的,甚至如果编码成变长向量会更好,我们会稍后展示。)。实现这一任务的最普通的方法是使用RNN,使得:
![]()
并且:
![]()
其中,ht属于n维实数空间,是t时刻的隐藏状态,c是由所有隐藏状态生成的向量,f和q是非线性函数。例如,Sutskever et al. (2014) 使用一个LSTM 作为f,并令q ({h1; · · · ; hT}) = hT 。
解码器被训练用来在给定上下文向量c和所有之前的已预测词{y1,…,yt'-1}的情况下,预测下一个单词yt′,换句话说,解码器通过把联合概率分解成一系列条件概率,定义了翻译结果y的概率p:
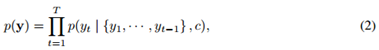
其中y = (y1, … , yTy). 在RNN中每个条件概率被定义为:
![]()
其中g 是一个多层非线性函数,用以输出yt的条件概率;st是RNN的隐藏状态。请注意解码器也可以使用如RNN和反卷积神经网络的混合体(Kalchbrenner and Blunsom, 2013)等其他架构。
3 学习对齐和翻译
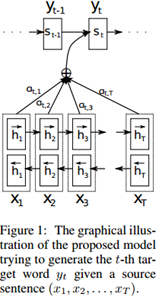
在这一部分,我们提出一个全新的神经机器翻译架构。这个新架构包含一个双向RNN作为编码器(参照3.2),和一个在翻译过程中对原始句子进行仿真搜索的解码器(参照3.1)。
3.1 解码器: 概要描述
在新模型架构中,我们定义公式(2)中的条件概率为:
![]()
其中si是i时刻RNN的隐藏状态,其计算公式为:
![]()
请注意既存的编码器-解码器方法(公式(2))中,每个单词使用的概率条件是相同的上下文向量c,而这里使用的概率条件是特定于每个目标单词yi的上下文向量ci。
上下文向量ci依赖于由编码器从输入序列中映射过来的标注序列(h1,· · · , hTx),其中的每一个标注hj都包含了输入序列的整体信息,并对输入序列中的第j个单词的附近部分给予了强烈关注。我们在3.2节详细解释如何计算这些标注。
然后对标注hj进行加权求和得到上下文向量ci:
![]()
hj的对应权重alphaij的计算方法:
![]()
其中:
![]()
这里a是一个对齐模型,它评价了输入序列的第j个单词附近的信息,在多大程度上与翻译输出序列的第i个单词yi相匹配,对齐模型的评价得分依赖于RNN隐藏状态si-1(恰在输出yi之前的状态,参考公式(4))和输入序列的第j个标注hj。
我们将对齐模型a参数化为一个前向传播神经网络,它同系统的其他组件一起进行联合训练。注意不像传统机器翻译那样作为一个隐变量,这里的对齐模型直接计算一个软对齐,这使得损失函数的梯度可以向后传播,因此对齐模型可以同整个翻译模型一起进行联合训练。
对所有标注加权求和的操作,我们可以理解成计算一个期望标注,这里的期望是指对齐的概率在标注序列上的分布。设alphaij是目标单词yi和原单词xj的对齐概率,那么第i个上下文向量ci就是给定所有标注和他们各自对应概率alphaij情况下的期望标注。(译者注:ci的意义就是统计了第i个目标单词与原始序列中的每个词,以及每个词附近的信息,如何发生关系,在多大程度上有关系,这就是第i个目标单词在原始序列中的上下文,恰好诠释了上下文这个概念。)
概率alphaij,或者其关联的能量eij,反映了在给定前一个隐藏状态si-1的情况下,在决策下一个隐藏状态si和生成下一个目标单词yi的时候,标注hj有多重要。直觉上,这是在解码器中实现了一个注意力机制,解码器可以决定应该关注输入序列中的哪些部分。传统的编码器不得不将原序列的所有信息编码到定长向量中,我们通过让解码器拥有注意力,把编码器从这种负担中解脱了出来。这个新方法使得信息散布在标注序列hj中,在后续处理中解码器可以从标注序列中选择性的获取信息。
3.2 编码器:双向RNN生成标注序列
公式(1)描述的通常的RNN,从输入序列x的第一个字符顺序读入,直到最后一个字符xTx。在我们提出的结构中,在每个单词的标注信息中,不仅要归纳前面单词的信息,还要归纳后面单词的信息,因此我们提议使用最近在语音识别(例如 Graves et al., 2013)中成功应用的双向RNN(BiRNN, Schuster and Paliwal, 1997)。
一个BiRNN包含一个前向和一个后向RNN。前向RNN f按照输入序列的原有字序读取(从x1到xTx),同时计算前向隐藏状态序列(前向h1, … , 前向hTx)而后向RNN逆序读取输入序列(从xTx到x1),同时计算后向隐藏状态序列(后向h1, … , 后向hTx)
对每个单词xj,通过拼接前向隐藏状态-前向hj-和后向隐藏状态-后向hj,我们得到标注:
![]()
这样以来,标注hj就同时包含了前后两个方向的单词信息。由于RNN倾向于对最近的输入有更好的表达,标注hj将会关注xj附近的信息。这些标注组成的序列被后面的解码器和对齐模型用来计算单词xj的上下文向量(公式(5)–(6))。
图1展示了我们提出的模型。
4 实验设定
我们在英法翻译任务上,使用ACL WMT ’14 (http://www.statmt.org/wmt14/translation-task.html)提供的双语平行语料验证我们提出的方法。作为比较,我们对最近由Cho et al. (2014a)提出的RNN编码器-解码器模型也做了一个性能报告。在两个模型上我们使用同样的训练手法和同样的数据集(模型实现在这里:https://github.com/lisa-groundhog/GroundHog)。
4.1 数据集
WMT ’14 数据集包含下面的英法语料: 欧洲议会(61M words), 新闻评论(5.5M), 联合国(421M) ,以及两个大小分别是90M和272.5M的爬虫语料,总计850M单词。我们使用Cho et al. (2014a)中描述的操作规程,使用Axelrod et al. (2011) (Available online at http://www-lium.univ-lemans.fr/˜schwenk/cslm_joint_paper/)提出的数据选取方法,将联合语料大小缩减到348M。尽管可以使用大得多的单语言语料来预训练编码器,但是我们没有使用前面提到的平行语料之外的任何单语言数据。我们把数据集WMT ’14中的news-test-2012 和news-test-2013拼接在一起作为验证数据集,并在在测试集news-test-2014上做模型评估。
经过常规的分词(我们使用开源的机器翻译包Moses中的分词脚本),我们使用每种语言中的前30000个高频词来训练模型,任何没有出现在这个名单中的词都被映射为一个特殊的词([UNK])。在这之外,我们没有对数据施加小写转换或词干提取等任何其他特殊预处理。
4.2 模型
我们训练两个模型,一个是RNN编码器-解码器模型(RNNencdec, Cho et al., 2014a),另一个是我们提出的模型,称它为RNNsearch。我们对每个模型训练两次:第一次使用长度不大于30的句子(RNNencdec-30, RNNsearch-30)训练,第二次使用长度不大于50的句子训练(RNNencdec-50, RNNsearch-50)。
RNNencdec的编码器和解码器各自包含1000个隐藏单元(在这篇论文中,提到“隐藏单元”我们是指门控隐藏单元(参照Appendix A.1.1))。RNNsearch的编码器由前向RNN和后向RNN构成,分别包含1000个隐藏单元,RNNsearch的解码器也包含1000个隐藏单元。两个模型都使用多层网络,后接一个单层maxout (Goodfellow et al., 2013)隐层来计算每个目标单词的条件概率(Pascanu et al., 2014)。
我们使用mini batch随机梯度下降算法,并使用Adadelta (Zeiler, 2012)优化算法来训练每个模型,每次梯度更新使用80个句子作为minibatch,每个模型我们训练了大概5天。
一旦模型训练完毕,我们使用集束搜索(beam search)方法找到使得条件概率最大化的翻译结果(例如Graves, 2012; Boulanger-Lewandowski et al., 2013)。Sutskever et al. (2014)在他们的神经机器翻译模型中使用了此方法来生成翻译结果。
更多模型架构和训练过程的细节,请参照附件A和B。
5 结果
5.1 定量结果
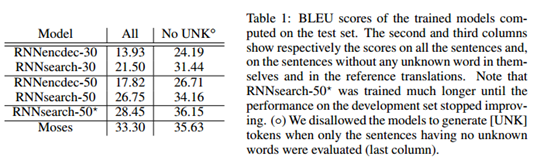
在表1中我们列出了翻译性能的BLEU得分。很明显在各种情况下RNNsearch都比传统的RNNencdec优秀,更重要的是,当我们用只包含认识单词的句子评估我们提出的模型时,其性能与传统的基于短语的翻译系统(Moses)的性能一样好。这是一个显著的进步,因为Moses除了我们使用的平行语料外,还使用了额外的单语言语料(418M单词)。
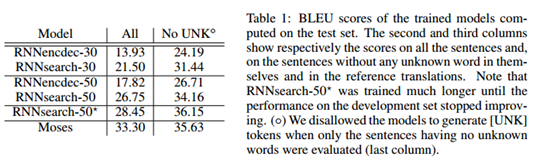
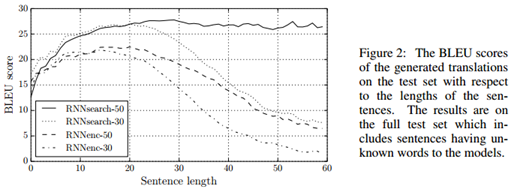
我们提出这个方法的背后动机之一就是,基本的编码器-解码器方法中的定长上下文向量可能会带来限制。我们推测这种限制使得基本编码器-解码器方法在处理长句子时不如我们提出的方法。在图2中,我们看到当句子长度增加时RNNencdec的性能急剧下降,另外RNNsearch-30和RNNsearch-50对句子长度更鲁棒,特别是RNNsearch-50,即使句子长度达到甚至超过50仍然没有性能恶化。图1中可以看到RNNsearch-30要比RNNencdec-50的性能还要好,这使我们提出的模型相对于基本编码器-解码器模型的优势得到了进一步确认。
5 结果
5.1 定量结果
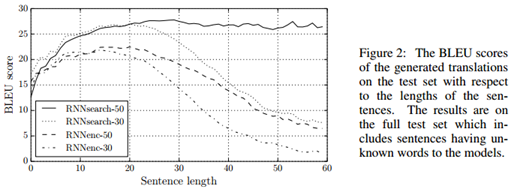
在表1中我们列出了翻译性能的BLEU得分。很明显在各种情况下RNNsearch都比传统的RNNencdec优秀,更重要的是,当我们用只包含认识单词的句子评估我们提出的模型时,其性能与传统的基于短语的翻译系统(Moses)的性能一样好。这是一个显著的进步,因为Moses除了我们使用的平行语料外,还使用了额外的单语言语料(418M单词)。
我们提出这个方法的背后动机之一就是,基本的编码器-解码器方法中的定长上下文向量可能会带来限制。我们推测这种限制使得基本编码器-解码器方法在处理长句子时不如我们提出的方法。在图2中,我们看到当句子长度增加时RNNencdec的性能急剧下降,另外RNNsearch-30和RNNsearch-50对句子长度更鲁棒,特别是RNNsearch-50,即使句子长度达到甚至超过50仍然没有性能恶化。图1中可以看到RNNsearch-30要比RNNencdec-50的性能还要好,这使我们提出的模型相对于基本编码器-解码器模型的优势得到了进一步确认。
5.2 定性分析
5.2.1 对齐
我们提出的方法提供了一个直观的方式来观察翻译结果和原句子之间的软对齐,这种直观性可以通过对公式(6)中的标注权重alphaij进行可视化来实现,如图3所示。每个图中的矩阵的每一行表明了与标注关联的权重。通过这个图我们可以看到原始句子中哪些位置在生成翻译目标单词时更重要。
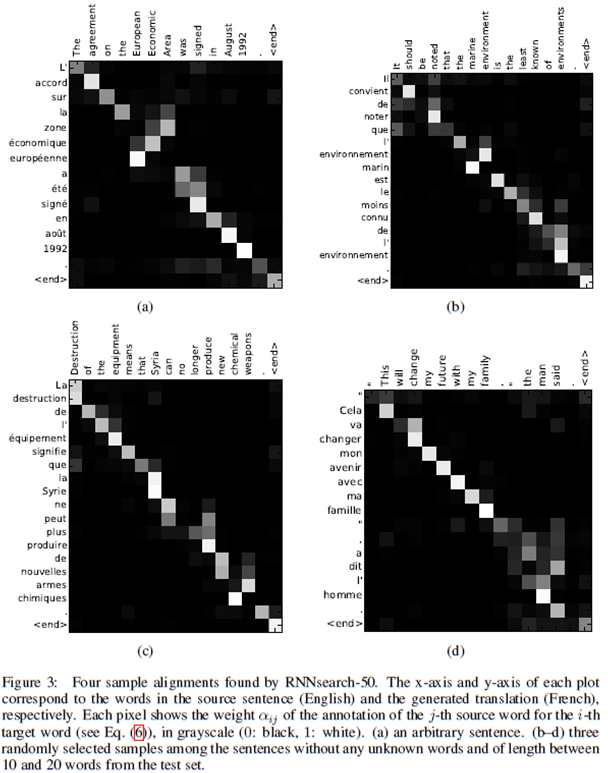
我们可以从图3的对齐中看出,英语和法语之间的单词对齐大致是单调性的,我们可以看到矩阵对角线上的权重最强。但是,也可以发现一些非平凡的,非单调的对齐。通常形容词和名词在法语和英语中的顺序是不同的,图3(a)中有一个这样的例子,图中显示模型正确的将短语[European Economic Area]翻译成了[zone economique europ ´ een]。RNNSearch模型能够跳过两个单词([European] and [Economic]),正确的将法语的zone和英语的area对齐,然后每次再回退一个词来完成整个短语[zone economique europ ´ eenne]。
与硬对齐相比,软对齐的优势是明显的,比如图3(d),原始短语[the man]被翻译成了[l’ homme],所有的硬对齐会把the对应到[l’],把man对应到[homme],但这样的对应无助于翻译,因为你必须the后面跟了什么单词才能决定the应该被翻译成[le], [la], [les] 还是 [l’]。我们的软对齐方法通过让模型同时关注the和man,从而自然而然的解决了这个问题,所以在这个例子中,我们看到模型正确的将the翻译成了[l’]。类似的结果也可以在图3的其他例子中看到。软对齐的另一个额外的好处是,它能够顺利的应对原句和目标句之间的长度差异,不会要求将某些单词的翻译与违反直觉的 ([NULL])对应起来。
5.2.2 长句子
略;
6 相关研究
6.1 对齐学习
最近Graves (2013)在手写体合成任务中,也提出了一个类似的把输出符号与输入符号进行对齐的方法。手写体合成任务中要求模型根据给定的字符串产生手写体。在Graves的研究中,他使用混合高斯核来计算标注的权重,这里使用一个对齐模型来预测位置,宽度以及核函数的混合系数。更具体一点,他的对齐限定在了预测位置以使位置可以单调增长。
与我们的方法的主要不同在于,Graves的标注的权重是单向移动的。而在机器翻译任务中,这会产生非常严重的限制,因为为了生成语法正确的翻译,经常需要调整语序(例如英语-德语翻译)。
相反,我们的方法,要求为翻译结果的每个单词计算原句子的每个单词的标注权重,这会增加计算量,但不是很严重,因为在翻译任务中,大多数句子的长度在10-40个单词之间。然而,这一点可能会限制其应用到其他任务。
6.2 用于机器翻译的神经网络
Bengio et al. (2003)中介绍了神经概率语言模型,研究者们在给定一定量的前序单词的前提下,使用一个神经网络对下一个单词的条件概率进行建模。从这份研究以后,神经网络就开始在机器翻译中广泛使用。然而,神经网络的功能受到了很大的限制,只用于为既存的统计机器翻译系统提供单一的特征,或者对寄存系统提供的候选翻译进行重新排序。
例如,Schwenk (2012)提出使用一个前向神经网络来计算一对原短语和目标短语的得分,作为一个追加特征应用在既存的基于短语的统计机器翻译系统中。最近,Kalchbrenner and Blunsom (2013) and Devlin et al. (2014)报告称,他们成功的将神经网络作为既存翻译系统的一个子模块。传统上,训练一个神经网络作为目标语言模型,用于重新评分或者对候选翻译进行重新排序(see, e.g., Schwenk et al., 2006)。
尽管我们上面介绍的方法提高了寄存翻译系统的最佳性能,但我们更有兴趣基于神经网络设计一个全新的翻译系统。因此我们在这片论文中提出的神经机器翻译方法,是之前的研究的一个转折点。不是把神经网络作为既存系统的一部分,我们的模型可以独立运行并从原句子直接生成翻译结果。
7 结论
传统的机器翻译方法,是一个编码器-解码器结构的方法,它将输入句子 编码成一个定长向量然后由解码器将其解码成翻译结果。基于最近Cho et al. (2014b) and Pouget-Abadie et al. (2014)的研究,我们推测固定长度的上下文向量的使用在翻译长句子时会有问题。
在这篇论文中,我们提出了解决这个问题的一个新架构。我们通过在生成每个目标单词时,使模型可以对输入单词或者对通过编码器计算出的标注信息进行搜索,扩展了基本的编码器-解码器架构。这将模型从不得不把输入句子编码成定长向量的尴尬中解放出来,也使得模型只聚焦在与下一个目标单词相关的信息上。这个方法的一个主要的积极影响是,使得神经机器翻译系统可以在翻译长句子时产生好的结果。不同于传统的机器翻译系统,系统的所有组件,包括对齐机制,都可以联合进行训练,以更高的对数似然概率生成正确的翻译。
我们把提出的模型称为RNNsearch,在英法翻译任务中对其进行了测试。实验表明,在任何长度的句子中,RNNsearch模型都显著优于传统的编码器-解码器模型(RNNencdec),并且其对句子长度的鲁棒性强很多。在定量分析中,我们研究了RNNsearch生成的软对齐,从中我们可以得出结论,正是该模型可以将每个目标单词与相关原单词,或者元单词的标注对其,因此才生成了正确的翻译结果。
或许更重要的是,我们提出的方法的性能可以与既存的基于短语的统计机器翻译系统相媲美。考虑到我们推荐的架构,或者整个神经机器翻译家族,是在今年才被提出的,所以可以说这一性能是一个突出的成果。我们相信这里提出的架构对更好的机器翻译和更好的语言理解来说,是一个有前景的开始,
这里留下的一个挑战是,如何更好地处理未知词,或者罕见词。为了更广泛的应用,以及在所有的场景中达到机器翻译的最佳性能,这是必须要解决的问题。