https://www.bilibili.com/video/BV1Ep4y1Q71p
活动作品ICLR 2020论文分享-BERT在神经机器翻译中的应用


要解决的问题:
- 直接用预训练的结果
- BERT训练和NMT任务的分词方式不一样,引起句子长短不一样
- BERT双向,decoder 单向 —— BERT作为embedding输入,不适用于decoder 端;
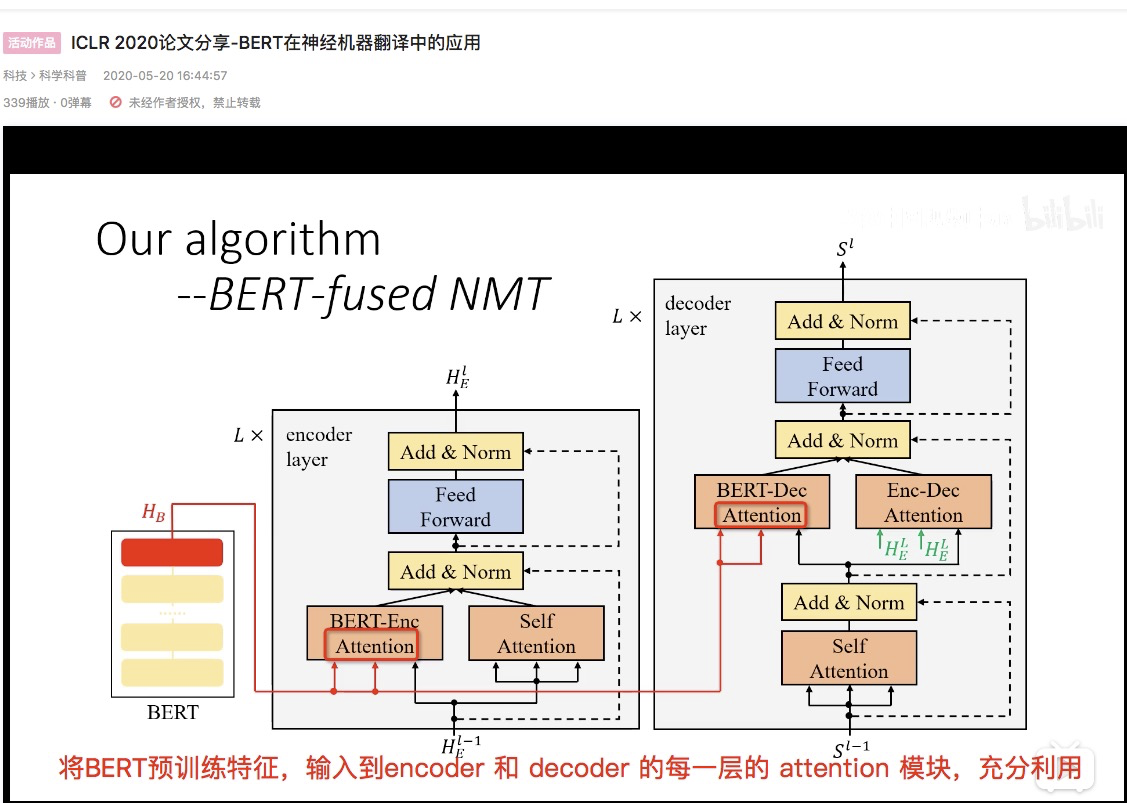
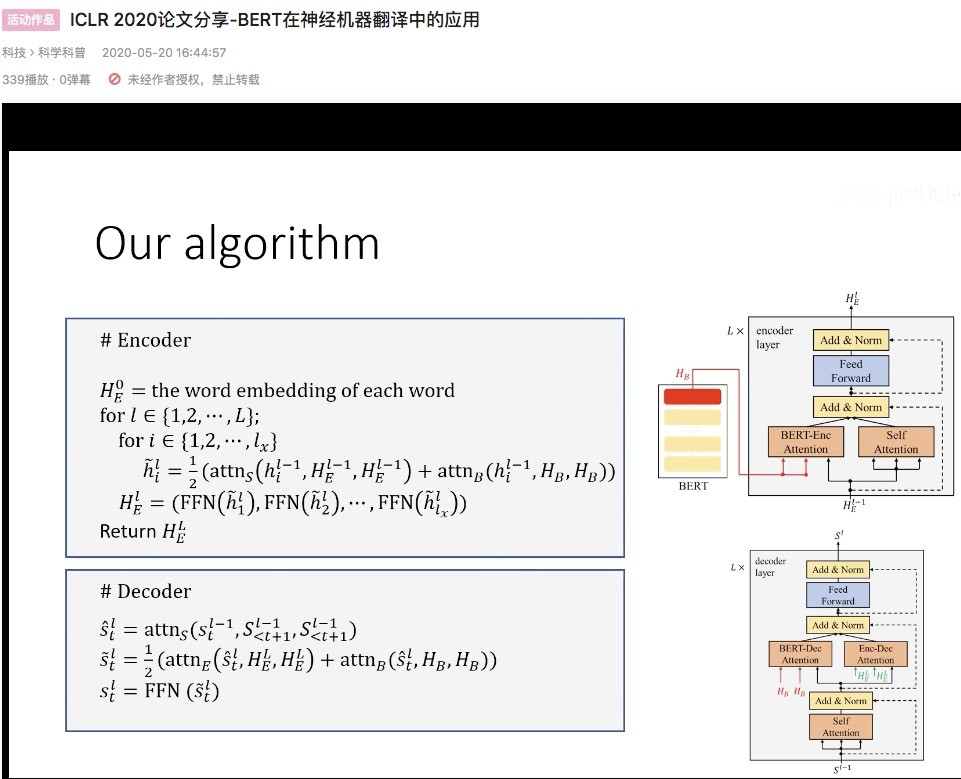
原 Transformer 中的 self-attention 是 Warm-up的——一用一个训练到收敛的模型的参数初始化
红线 BERT attention 随机初始化
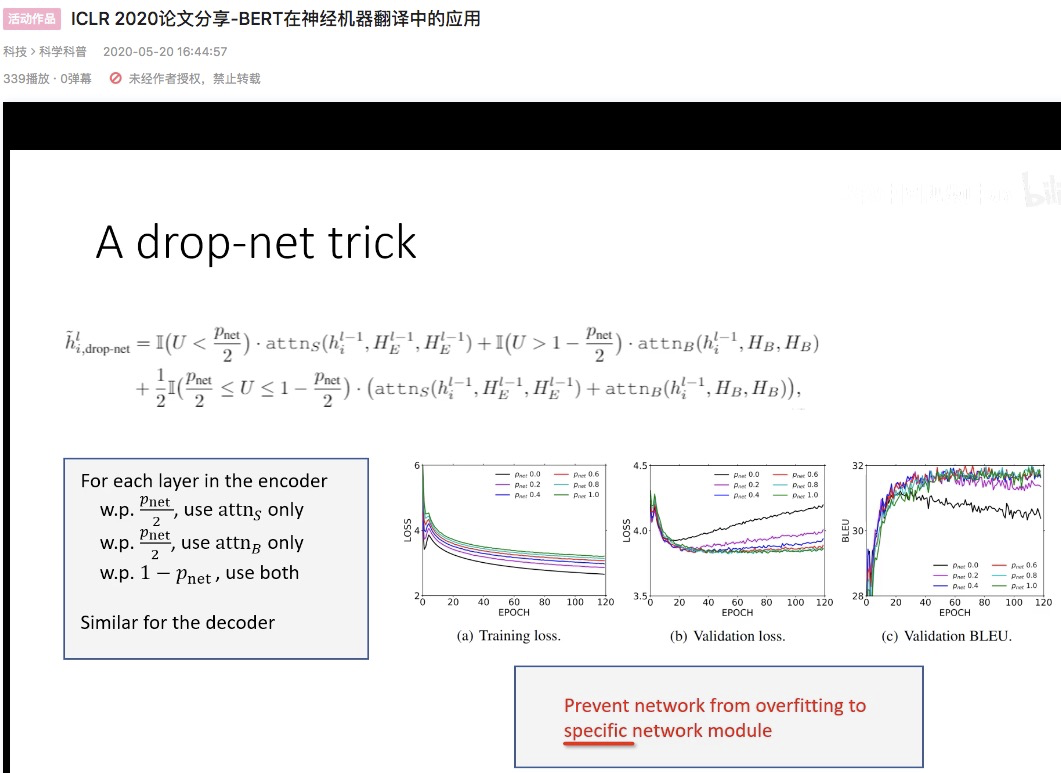
drop-out 率 p 增大,训练loss 会变大,但 validation loss 会变小
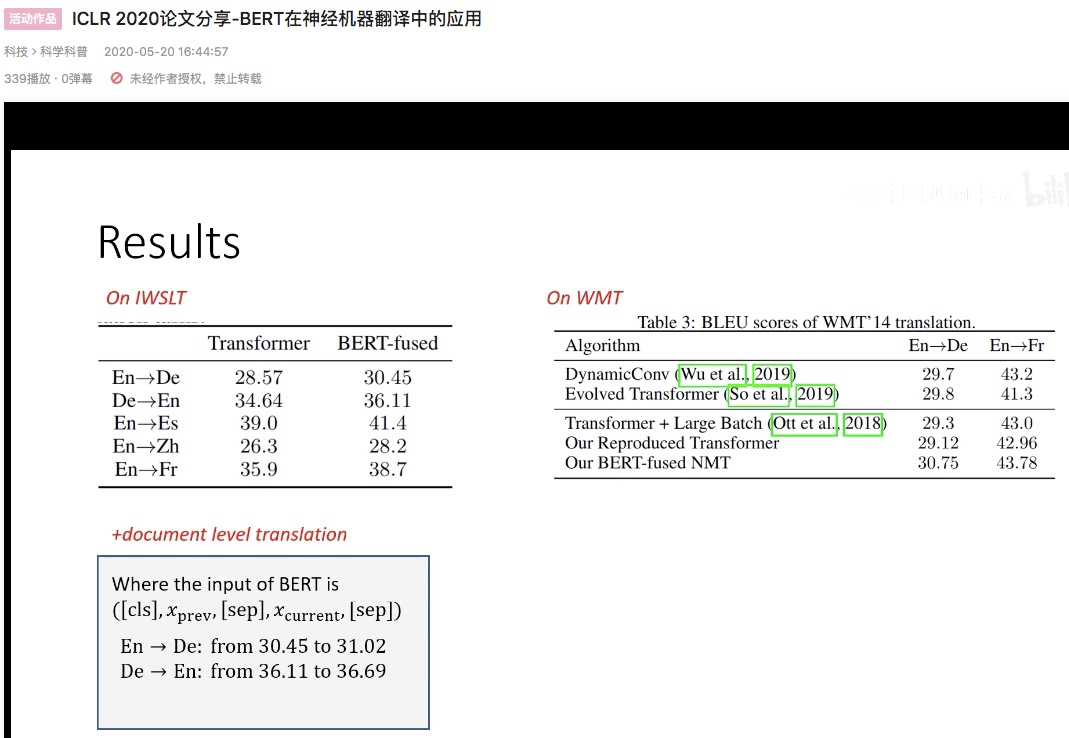
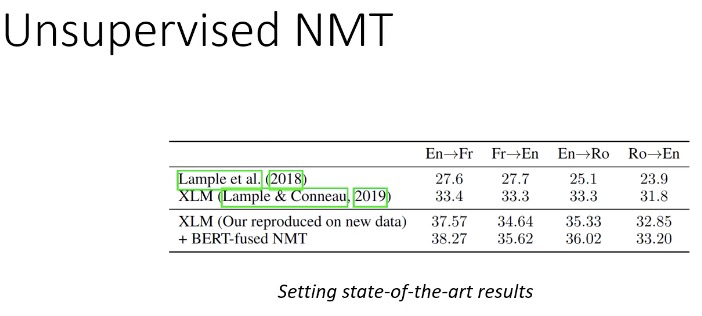
效果超过了其它:精心设计的模型结构 & NAS 搜索出来的模型结构
IWSLT是连续文档切分成句子组成的数据集,所以我们猜测:BERT对文档级的翻译有帮助
(左下角)

tune BERT 的参数,效果会变差
两部分 attention 并排 比 stack,效果更好
从BERT中汲取到了对翻译有用的信息,并不是单纯引入了更多的参数带来的效果