preface:最近的任务,还是爬微博。之前的用不上,post提交,还是不太熟悉,模拟登陆不了,故换种方式,用selenium模拟登陆,从此任何登录以及js调用都是浮云,我模拟登录分分钟解决。之前的时而有用,时而没用,不稳定,写得不够鲁棒。但这次,真能够抓取微博,表示还是有点进步的。
主要任务是通过搜索关键词,爬取跟关键词有关的微博。
主要流程:
- 用selenium模拟鼠标键盘登录;
- 模拟点搜索框,输入搜索关键词;
- 保存当页html,模拟点击下一页;
- 直到没有下一页,处理保存下来的html(也可在上一步直接提取,不保存到当地),提取微博<p></p>之间的内容(若有展开全文形式的微博没有处理);
效果:
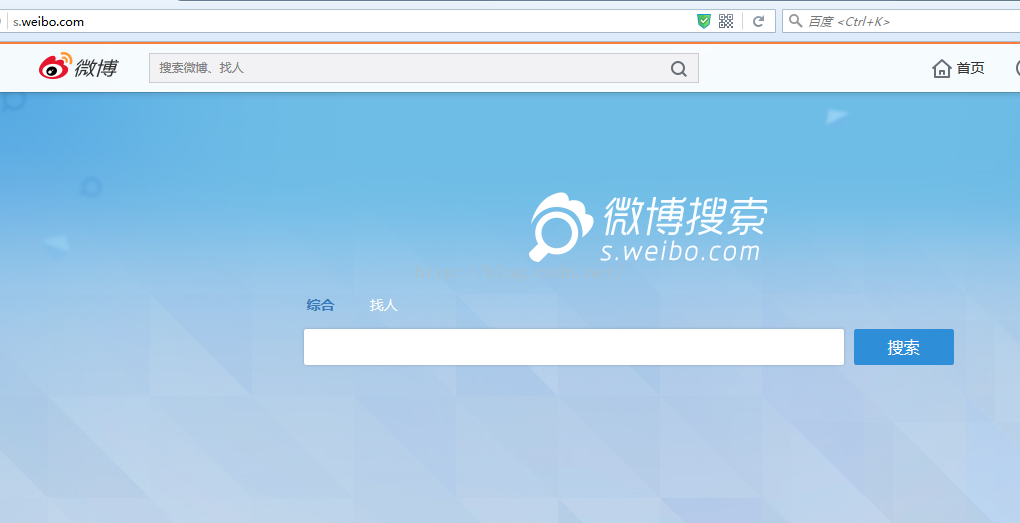
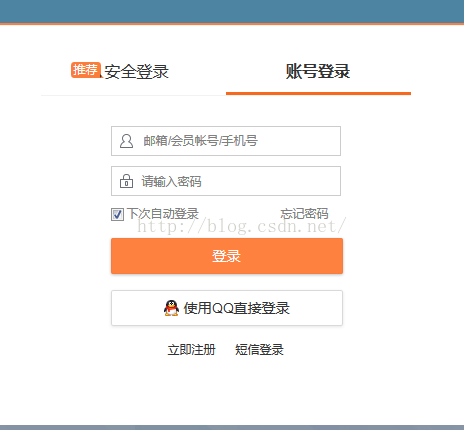
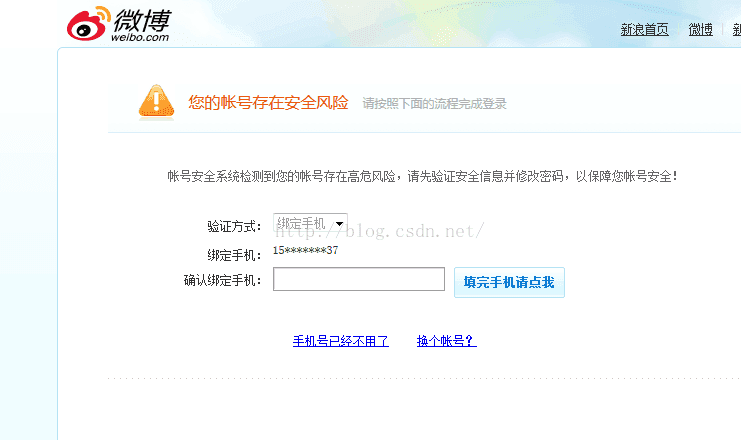
具体效果跟真实点击效果一致,不过若是爬取太多次,会导致验证问题,此时,可能需要换个账号登录重新爬了。所以说,注意延时,time.sleep(),保证网速加载比较快比较重要。
coding:
# -*- coding: utf-8 -*- import os import time import logging from selenium import webdriver from selenium.common.exceptions import NoSuchElementException from bs4 import BeautifulSoup as bs import sys reload(sys) sys.setdefaultencoding("utf-8") ''' 0.安装火狐 1.安装selenium,可通过pip安装:pip install selenium 2.程序里面改三处:用户名、密码、搜过的关键词search_text 3.需要手动输入验证码,并且验证码大小写敏感,若是输错了,等3秒再输入。 4.爬下来了,用BeautifulSoup提取,并且将相同文本的放在一起,并且排序 时间:5秒一个,不可缩短,不然加载不出来下一页这个按钮,然后程序就挂了,若网速快些,延时可以短些。 ''' #username_ = "你自己的微博号" #password_ = "密码" #logging.basicConfig(level=logging.DEBUG) logging.basicConfig(level=logging.INFO) browser = webdriver.Firefox() href = 'http://s.weibo.com/' browser.get(href) time.sleep(2) # 右上登陆 login_btn = browser.find_element_by_xpath('//a[@node-type="loginBtn"]') login_btn.click() time.sleep(3) # 选择账号登录 name_login = browser.find_element_by_xpath('//a[@action-data="tabname=login"]') name_login.click() time.sleep(2) # 输入用户名,密码 username = browser.find_element_by_xpath('//input[@node-type="username"]') password = browser.find_element_by_xpath('//input[@node-type="password"]') username.clear() username.send_keys(username_) password.clear() password.send_keys(password_) # 提交登陆 sub_btn = browser.find_element_by_xpath('//a[@suda-data="key=tblog_weibologin3&value=click_sign"]') sub_btn.click() while True: try: verify_img = browser.find_element_by_xpath('//img[@node-type="verifycode_image"]') except NoSuchElementException: break if verify_img: # 输入验证码 verify_code = browser.find_element_by_xpath('//input[@node-type="verifycode"]') verify_code_ = raw_input('verify_code > ') verify_code.clear() verify_code.send_keys(verify_code_) # 提交登陆 sub_btn = browser.find_element_by_xpath('//a[@suda-data="key=tblog_weibologin3&value=click_sign"]') sub_btn.click() time.sleep(2) else: break #===============================以上这部分的登陆,放在函数里面返回browser出错,需要单独拿出来======================== def get_weibo_search(search_text, browser): search_form.send_keys(search_text.decode('utf-8'))#将关键词送到搜索栏中,进行搜索 # 点击搜索 search_btn = browser.find_element_by_xpath('//a[@class="searchBtn"]') search_btn.click() time.sleep(3)#进入循环之前,让第一页先加载完全。 # 这块可以得到具体的网页信息 count = 1 logging.info('try download html for : {}'.format(search_text.encode("gbk"))) topics_name = search_text.encode("gbk") topics_name = topics_name.replace(" ","_")#将名字里面的空格换位_ os_path = os.getcwd() key_dir = os.path.join(os_path,topics_name) if not os.path.isdir(key_dir): os.mkdir(key_dir) while True: # 保存网页 file_name = topics_name+os.sep+'{}_{}.html'.format(topics_name, count) with open(file_name, 'w') as f: f.write(browser.page_source) logging.info('for page {}'.format(count)) try: next_page = browser.find_element_by_css_selector('a.next') #next_page = browser.find_element_by_xpath('//a[@class="page next S_txt1 S_line1"]') time.sleep(1) next_page.click()#有的时候需要手动按F5刷新,不然等太久依然还是出不来,程序就会挂,略脆弱。 count += 1 time.sleep(5)#完成一轮之前,保存之前,先让其加载完,再保存 except Exception,e:#异常这里,跑一次,跳出,跑多个query,断了一个query后,下个继续不了,还需优化 logging.error(e) break #====================================================== def get_weibo_text(file_name):#将html文件里面的<p></p>标签的内容提取出来 text = [] soup = bs(open(file_name)) items = soup.find_all("div",class_="WB_cardwrap S_bg2 clearfix") if not items: text = [] for item in items: line = item.find("p").get_text() #print line text.append(line) return text def get_weibo_all_page(path, file_names):#将<span style="font-family: Arial, Helvetica, sans-serif;">文件夹下所有文件里提取出来微博的合并起来</span> texts_all = [] for file_name in file_names: #print file_name, texts = get_weibo_text(path+os.sep+file_name) #print len(texts) for text in texts: text = text.replace("\t","") text = text.strip("\n") text = text.strip(" ") if text in texts_all:#若是重了,不加入到里面 pass else: texts_all.append(text) return texts_all def get_results_weibo(weibos_name):#合并若干个文件夹下提取出来的微博 texts = [] for file_name in weibos_name: with open(file_name) as f: text = f.readlines() for line in text: line = line.strip("\n") if line not in texts: texts.append(line) return texts #================== if __name__=="__main__": try: #browser = login() # 进行搜索 search_form = browser.find_element_by_xpath('//input[@class="searchInp_form"]') search_form.clear() searchs_text = ["火影忍者","火影忍者 雏田","火影忍者 小樱"] for search_text in searchs_text: get_weibo_search(search_text, browser) #====== path = search_text.encode("gbk") path = path.replace(" ","_")#文件夹路径里面若有空格,替换为下滑线 file_names = os.listdir(path) texts_all = get_weibo_all_page(path, file_names) texts_all_sorted = sorted(texts_all) weibo_text_name = path+"_weibos.txt" f = open(weibo_text_name,"w") for text in texts_all_sorted: f.write(text+"\n") f.close() except Exception,e: print e #============将几个_weibos.txt文件合并到一起 print "together:" file_names_weibos = [i for i in os.listdir(os.getcwd()) if i.endswith("_weibos.txt")] texts = get_results_weibo(file_names_weibos) f = open("results.txt","w") for text in sorted(texts): f.write(text+"\n") f.close()
转载请注明来源:http://blog.csdn.net/u010454729?viewmode=list