作为国内社交媒体的领航者,很遗憾,新浪微博没有提供以“关键字+时间+区域”方式获取的官方API。当我们看到国外科研成果都是基于某关键字获得的社交媒体数据,心中不免凉了一大截,或者转战推特。再次建议微博能更开放些!
1、切入点
庆幸的是,新浪提供了高级搜索功能。找不到?这个功能需要用户登录才能使用……没关系,下面将详细讲述如何在无须登录的情况下,获取“关键字+时间+区域”的新浪微博。
首先我们还是要登录一下,看看到底是个什么样的功能。

然后我们看看地址栏:
- http://s.weibo.com/wb/%25E4%25B8%25AD%25E5%259B%25BD%25E5%25A5%25BD%25E5%25A3%25B0%25E9%259F%25B3&xsort=time®ion=custom:11:1000×cope=custom:2014-07-09-2:2014-07-19-4&Refer=g
这么长?其实蛮清晰、简单的。解析如下:
固定地址部分:http://s.weibo.com/wb/
关键字(2次URLEncode编码):%25E4%25B8%25AD%25E5%259B%25BD%25E5%25A5%25BD%25E5%25A3%25B0%25E9%259F%25B3
返回微博的排序方式(此处为“实时”):xsort=time
搜索地区:region=custom:11:1000
搜索时间范围:timescope=custom:2013-07-02-2:2013-07-09-2
可忽略项:Refer=g
是否显示类似微博(未出现):nodup=1 注:加上这个选项可多收集微博,建议加上。默认为省略参数,即省略部分相似微博。
某次请求的页数(未出现):page=1
既然是这么回事,我们接下来就可以使用网页爬虫的方式获取“关键字+时间+区域”的微博了……
2、采集思路
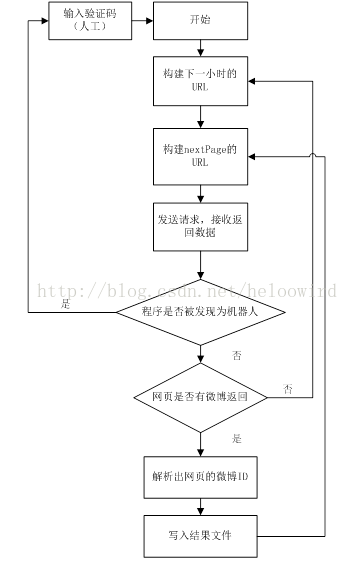
大体思路如下:构造URL,爬取网页,然后解析网页中的微博信息,如下图所示。微博官方提供了根据微博ID进行查询的微博信息的API,故本文只负责讲述收集微博ID。
另外,高级搜索最多返回50页微博,那么时间间隔设置最小为宜。所以时间范围(timescope)可设置为1小时,如2013-07-01-2:2013-07-01-2。
目前没有模拟登陆,所以需要设置两个邻近URL请求之间的随机休眠时间,过于频繁会被认为是机器人,你懂的。
3、具体实现
作为爬虫小工具,用python非常适合。作为python初学者,不要怪我写得像java。首先实现一个爬取每个小时的类。
- class CollectData():
- """每小时数据收集类
- 利用微博高级搜索功能,按关键字搜集一定时间范围内的微博。
- 大体思路:构造URL,爬取网页,然后解析网页中的微博ID。后续利用微博API进行数据入库。本程序只负责收集微博的ID。
- 登陆新浪微博,进入高级搜索,输入关键字”空气污染“,选择”实时“,时间为”2013-07-02-2:2013-07-09-2“,地区为”北京“,之后发送请求会发现地址栏变为如下:
- http://s.weibo.com/wb/%25E7%25A9%25BA%25E6%25B0%2594%25E6%25B1%25A1%25E6%259F%2593&xsort=time®ion=custom:11:1000×cope=custom:2013-07-02-2:2013-07-09-2&Refer=g
- 固定地址部分:http://s.weibo.com/wb/
- 关键字二次UTF-8编码:%25E7%25A9%25BA%25E6%25B0%2594%25E6%25B1%25A1%25E6%259F%2593
- 排序为“实时”:xsort=time
- 搜索地区:region=custom:11:1000
- 搜索时间范围:timescope=custom:2013-07-02-2:2013-07-09-2
- 可忽略项:Refer=g
- 显示类似微博:nodup=1 注:这个选项可多收集微博,建议加上。默认不加此参数,省略了部分相似微博。
- 某次请求的页数:page=1
- 另外,高级搜索最多返回50页微博,那么时间间隔设置最小为宜。所以该类设置为搜集一定时间段内最多50页微博。
- """
- def __init__(self, keyword, startTime, region, savedir, interval='50', flag=True, begin_url_per = "http://s.weibo.com/weibo/"):
- self.begin_url_per = begin_url_per #设置固定地址部分,默认为"http://s.weibo.com/weibo/",或者"http://s.weibo.com/wb/"
- self.setKeyword(keyword) #设置关键字
- self.setStartTimescope(startTime) #设置搜索的开始时间
- self.setRegion(region) #设置搜索区域
- self.setSave_dir(savedir) #设置结果的存储目录
- self.setInterval(interval) #设置邻近网页请求之间的基础时间间隔(注意:过于频繁会被认为是机器人)
- self.setFlag(flag) #设置
- self.logger = logging.getLogger('main.CollectData') #初始化日志
- ##设置关键字
- ##关键字需解码
- def setKeyword(self, keyword):
- self.keyword = keyword.decode('GBK').encode("utf-8")
- print 'twice encode:',self.getKeyWord()
- ##设置起始范围,间隔为1小时
- ##格式为:yyyy-mm-dd-HH
- def setStartTimescope(self, startTime):
- if not (startTime == '-'):
- self.timescope = startTime + ":" + startTime
- else:
- self.timescope = '-'
- ##设置搜索地区
- def setRegion(self, region):
- self.region = region
- ##设置结果的存储目录
- def setSave_dir(self, save_dir):
- self.save_dir = save_dir
- if not os.path.exists(self.save_dir):
- os.mkdir(self.save_dir)
- ##设置邻近网页请求之间的基础时间间隔
- def setInterval(self, interval):
- self.interval = int(interval)
- ##设置是否被认为机器人的标志。若为False,需要进入页面,手动输入验证码
- def setFlag(self, flag):
- self.flag = flag
- ##构建URL
- def getURL(self):
- return self.begin_url_per+self.getKeyWord()+"®ion=custom:"+self.region+"&xsort=time×cope=custom:"+self.timescope+"&nodup=1&page="
- ##关键字需要进行两次urlencode
- def getKeyWord(self):
- once = urllib.urlencode({"kw":self.keyword})[3:]
- return urllib.urlencode({"kw":once})[3:]
- ##爬取一次请求中的所有网页,最多返回50页
- def download(self, url, maxTryNum=4):
- content = open(self.save_dir + os.sep + "weibo_ids.txt", "ab") #向结果文件中写微博ID
- hasMore = True #某次请求可能少于50页,设置标记,判断是否还有下一页
- isCaught = False #某次请求被认为是机器人,设置标记,判断是否被抓住。抓住后,需要复制log中的文件,进入页面,输入验证码
- mid_filter = set([]) #过滤重复的微博ID
- i = 1 #记录本次请求所返回的页数
- while hasMore and i < 51 and (not isCaught): #最多返回50页,对每页进行解析,并写入结果文件
- source_url = url + str(i) #构建某页的URL
- data = '' #存储该页的网页数据
- goon = True #网络中断标记
- ##网络不好的情况,试着尝试请求三次
- for tryNum in range(maxTryNum):
- try:
- html = urllib2.urlopen(source_url, timeout=12)
- data = html.read()
- break
- except:
- if tryNum < (maxTryNum-1):
- time.sleep(10)
- else:
- print 'Internet Connect Error!'
- self.logger.error('Internet Connect Error!')
- self.logger.info('filePath: ' + savedir)
- self.logger.info('url: ' + source_url)
- self.logger.info('fileNum: ' + str(fileNum))
- self.logger.info('page: ' + str(i))
- self.flag = False
- goon = False
- break
- if goon:
- lines = data.splitlines()
- isCaught = True
- for line in lines:
- ## 判断是否有微博内容,出现这一行,则说明没有被认为是机器人
- if line.startswith('<script>STK && STK.pageletM && STK.pageletM.view({"pid":"pl_weibo_direct"'):
- isCaught = False
- n = line.find('html":"')
- if n > 0:
- j = line[n + 7: -12].encode("utf-8").decode('unicode_escape').encode("utf-8").replace("\\", "")
- ## 没有更多结果页面
- if (j.find('<div class="search_noresult">') > 0):
- hasMore = False
- ## 有结果的页面
- else:
- page = etree.HTML(j)
- dls = page.xpath(u"//dl") #使用xpath解析
- for dl in dls:
- mid = str(dl.attrib.get('mid'))
- if(mid != 'None' and mid not in mid_filter):
- mid_filter.add(mid)
- content.write(mid)
- content.write('\n')
- break
- lines = None
- ## 处理被认为是机器人的情况
- if isCaught:
- print 'Be Caught!'
- self.logger.error('Be Caught Error!')
- self.logger.info('filePath: ' + savedir)
- self.logger.info('url: ' + source_url)
- self.logger.info('fileNum: ' + str(fileNum))
- self.logger.info('page:' + str(i))
- data = None
- self.flag = False
- break
- ## 没有更多结果,结束该次请求,跳到下一个请求
- if not hasMore:
- print 'No More Results!'
- if i == 1:
- time.sleep(random.randint(55,75))
- else:
- time.sleep(15)
- data = None
- break
- i += 1
- ## 设置两个邻近URL请求之间的随机休眠时间,你懂的。目前没有模拟登陆
- sleeptime_one = random.randint(self.interval-30,self.interval-10)
- sleeptime_two = random.randint(self.interval+10,self.interval+30)
- if i%2 == 0:
- sleeptime = sleeptime_two
- else:
- sleeptime = sleeptime_one
- print 'sleeping ' + str(sleeptime) + ' seconds...'
- time.sleep(sleeptime)
- else:
- break
- content.close()
- content = None
- ##改变搜索的时间范围,有利于获取最多的数据
- def getTimescope(self, perTimescope, hours):
- if not (perTimescope=='-'):
- times_list = perTimescope.split(':')
- start_datetime = datetime.datetime.fromtimestamp(time.mktime(time.strptime(times_list[-1],"%Y-%m-%d-%H")))
- start_new_datetime = start_datetime + datetime.timedelta(seconds = 3600)
- end_new_datetime = start_new_datetime + datetime.timedelta(seconds = 3600*(hours-1))
- start_str = start_new_datetime.strftime("%Y-%m-%d-%H")
- end_str = end_new_datetime.strftime("%Y-%m-%d-%H")
- return start_str + ":" + end_str
- else:
- return '-'
有了每个小时的类之后,那就可以设置开始收集的时间了。
- def main():
- logger = logging.getLogger('main')
- logFile = './collect.log'
- logger.setLevel(logging.DEBUG)
- filehandler = logging.FileHandler(logFile)
- formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s: %(message)s')
- filehandler.setFormatter(formatter)
- logger.addHandler(filehandler)
- while True:
- ## 接受键盘输入
- keyword = raw_input('Enter the keyword(type \'quit\' to exit ):')
- if keyword == 'quit':
- sys.exit()
- startTime = raw_input('Enter the start time(Format:YYYY-mm-dd-HH):')
- region = raw_input('Enter the region([BJ]11:1000,[SH]31:1000,[GZ]44:1,[CD]51:1):')
- savedir = raw_input('Enter the save directory(Like C://data//):')
- interval = raw_input('Enter the time interval( >30 and deafult:50):')
- ##实例化收集类,收集指定关键字和起始时间的微博
- cd = CollectData(keyword, startTime, region, savedir, interval)
- while cd.flag:
- print cd.timescope
- logger.info(cd.timescope)
- url = cd.getURL()
- cd.download(url)
- cd.timescope = cd.getTimescope(cd.timescope,1) #改变搜索的时间,到下一个小时
- else:
- cd = None
- print '-----------------------------------------------------'
- print '-----------------------------------------------------'
- else:
- logger.removeHandler(filehandler)
- logger = None
- if __name__ == '__main__':
- main()
就这样了……
如果想编译成windows窗口文件或者想改造成自己小爬虫,欢迎去 github pull一下!!