preface:最近因为任务的关系,需要各种爬虫,根据指定人物爬百度百科、指定电影电视剧爬豆瓣影评、指定餐馆爬大众点评评论等等,这些都挺简单的,不过就是各种情况的分析麻烦。像是爬取人物百科,有的人物具有多义项;一般都是baike.baidu.com这个入口爬的,而有点人不在列表中,而是直接跳转,有点不是直接跳转,而是另外一个人的名字(英文人物的中文名百度百科);人物名字带有括号解释的那种,若有保存为文件名的时候,需要替换成其他的东西;还有多义项人物的时候,涉及到js回调,需要展开多义项才能取出,所有义项;又或者在百度百科里面是有,但是通过baike.baidu.com这个入口找不到,如007:幽灵党;再还有在爬取出来的文本中,中文符号变成了英文符号了,如XXX(xxx省长)变成XXX(xxx省长)。一旦人物实体多了,各种类型人物名字、电影都出来了,需要考虑的因素也就多了。
需要注意的是:
一旦开始爬,就想着尽可能把需要爬取的东西都爬下来,不要漏了某部分,结果又要重新爬。
如百度百科人物的inforbox,这个应该是相当重要的,卤煮当时没注意,觉得有点的人有,有的人没有,像是古代不是那么有名人物的百度百科,通常很简短没有inforbox,也很难提取,但是也应当在爬的时候标示下是否有inforbox,若有则爬下来。
再如豆瓣影评,有个“有用/无用”的个数,比较有用的评论其个数就高,不太有名的就低了,不太有名的电影,基本上都是为0,即使如此,也应当全部尽可能爬下来,至于以后是否用,再看是否从中提取了,否则再爬一次太麻烦。
卤煮遇到比较烦躁的是ip经常被封,即使用了代理也用了time.sleep(),也依然被封ip,看来卤煮还是太嫩了。还有的就是卤煮采用了python多线程爬取,效果还是有的,只是若是中间停下来了,不知从何开始,只能更新待爬取的实体了,带爬实体s = set(带爬实体s) - set(已爬实体s),由于实体在保存的时候可能做了些替换,如符号替换成了其他东西,依然是需要考虑挺多的,从效率上来看,还是值得的,卤煮机器为4核,启动4个线程,比原来快4倍,当然,这是在不被封ip的条件下。
上面是爬比较简单,处理比较麻烦;但又同时需要根据指定关键字爬新浪微博,这个让卤煮有点觉得有点难,还好之前看过一些关于模拟登陆之类的网上xx学院的视频课,以及研一的时候有个project,根据指定id爬取该人的微博的任务,虽然当时是使用师兄的代码,但此时可以作为参考,以及以前积累的一些和网上找的资料,再加上同仁的一起讨论,对于卤煮这个菜鸟,算是稍微弄好了。
一、工具
python基础包:
bs用于解析htmlfrom bs4 import BeautifulSoup as bs import urllib import urllib2 import cookielib import base64 import re import json import hashlib import rsa import binascii import sys reload(sys) sys.setdefaultencoding("utf-8")urllib,urllib2用于抓包
cookielib用于保存cookie
base64,rsa用于对用户名、密码加密(需要通过公钥和用户名、密码得到的结果进行提交)#rsa的安装可通过python的pip安装。若是已经安装其他的导致装不了rsa,cd到site-package文件夹下,rm ?? rsa*忘了加什么参数了,反正就是移除python包下,有关rsa的东西,再装。
binascii用于将加密信息转化为16进制
json用于解析js
后面三行固定保证编辑器默认格式为utf-8
Fiddler软件分析cookie、回调、请求等等信息。当然F12不错,但Fiddler(需要配合IE使用)用起来更方便些。
火狐浏览器+F12、IE浏览器。
二、分析:登陆
1.初始界面
这里使用简便式登陆,url = 'http://login.sina.com.cn/sso/login.php?client=ssologin.js(v1.4.18)',即:
Figure 1: 登陆界面
只需要登陆即可,另外这个界面好像不需要验证码。通过weibo.com登陆的话,次数多了需要验证码了。
2.提交postdata
在IE浏览器中手动输入用户名密码(憋点下次自动登陆和安全登陆),分析fiddler,
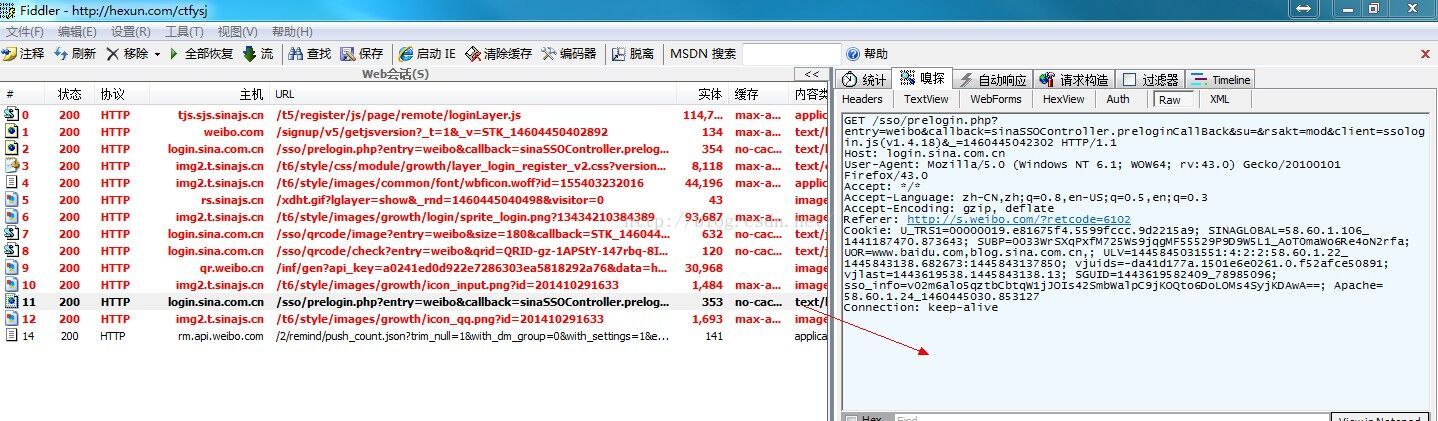
Figure 2:Fiddler分析
可以看到在第2个和第11个,有个URL:http://login.sina.com.cn/sso/prelogin.php?entry=weibo&callback=sinaSSOController.preloginCallBack等等,其他都是一些什么图片js等无关紧要的东西,从这里开始,加上一些我们要提交的东西,就得到最终的登陆结果了。分析这里body,需要提交部分:
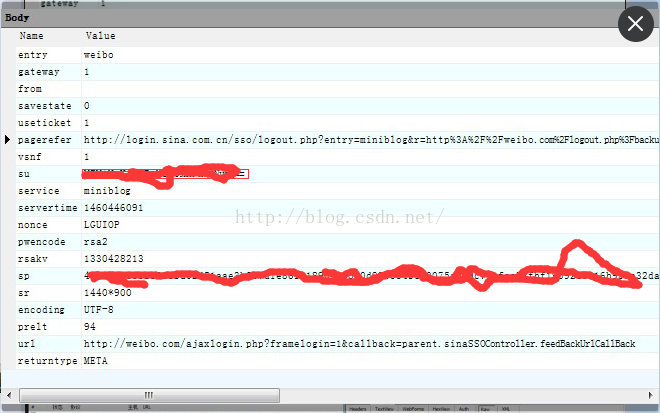
需要提交的东西还是挺多的:entry,getway,from,savestate,等等,其中su,sp分别为用户名和密码的加密结果,其中需要注意的是加密方式pwencode:rsa2,在以前的版本里是通过wsse加密的,可以参考博客python使用rsa加密算法模块模拟登陆新浪微博登陆,有些是固定死的,有些是需要通过刚才的第11个链接返回的js(在Fiddler中可以看到,忘了截图)中提取的,如servertime,nonce这两个需要用来加密用户名,另外加上代理等扔到参数里面,就可以通过urllib2来模拟登陆获得登陆的url了,获得登陆url要再经过urllib解析即可。
3.后续查询:
在登陆成功后,只要设定query和爬取的页数,循环爬取就可以了,爬到了html文件,用bs解析即可得到包含关键字的微博。找到了页面分分钟爬下来,这个就简单了。
4.coding:
5.结果分析:
# -*- coding: utf-8 -*- """ Created on Fri Apr 08 17:10:36 2016 @author: Administrator """ #coding=utf8 from bs4 import BeautifulSoup as bs import urllib import urllib2 import cookielib import base64 import re import json import hashlib import rsa import binascii import sys reload(sys) sys.setdefaultencoding("utf-8") pubkey = 'EB2A38568661887FA180BDDB5CABD5F21C7BFD59C090CB2D245A87AC253062882729293E5506350508E7F9AA3BB77F4333231490F915F6D63C55FE2F08A49B353F444AD3993CACC02DB784ABBB8E42A9B1BBFFFB38BE18D78E87A0E41B9B8F73A928EE0CCEE1F6739884B9777E4FE9E88A1BBE495927AC4A799B3181D6442443' cj = cookielib.LWPCookieJar() cookie_support = urllib2.HTTPCookieProcessor(cj) opener = urllib2.build_opener(cookie_support, urllib2.HTTPHandler) urllib2.install_opener(opener) postdata = { 'entry': 'weibo', 'gateway': '1', 'from': '', 'savestate': '7', 'userticket': '1', 'ssosimplelogin': '1', 'vsnf': '1', #'vsnval': '', 'su': '', 'service': 'miniblog', 'servertime': '', 'nonce': '', #'pwencode': 'wsse', 'pwencode': 'rsa2', 'sp': '', 'pagerefer':'http://login.sina.com.cn/sso/logout.php?entry=miniblog&r=http%3A%2F%2Fweibo.com%2Flogout.php%3Fbackurl%3D%252F', 'raskv':'', 'sr':'1440*900', 'prelt':'94', 'encoding': 'UTF-8', 'url': 'http://weibo.com/ajaxlogin.php?framelogin=1&callback=parent.sinaSSOController.feedBackUrlCallBack', 'returntype': 'META' } def get_servertime(): url = 'http://login.sina.com.cn/sso/prelogin.php?entry=weibo&callback=sinaSSOController.preloginCallBack&su=dW5kZWZpbmVk&client=ssologin.js(v1.3.18)&_=1329806375939' data = urllib2.urlopen(url).read() p = re.compile('\((.*)\)') try: json_data = p.search(data).group(1) data = json.loads(json_data) servertime = str(data['servertime']) nonce = data['nonce'] rsakv=data['rsakv'] return servertime, nonce,rsakv except: print 'Get severtime error!' return None def get_pwd(pwd, servertime, nonce): #pwd1 = hashlib.sha1(pwd).hexdigest()#旧的加密方式,pwencode的值需要为wsse #pwd2 = hashlib.sha1(pwd1).hexdigest() #pwd3_ = pwd2 + servertime + nonce #pwd3 = hashlib.sha1(pwd3_).hexdigest() #return passwd global pubkey rsaPublickey = int(pubkey, 16) key = rsa.PublicKey(rsaPublickey, 65537) #创建公钥 message = str(servertime) + '\t' + str(nonce) + '\n' + str(pwd) #拼接明文js加密文件中得到 passwd = rsa.encrypt(message, key) #加密 passwd = binascii.b2a_hex(passwd) #将加密信息转换为16进制。 print passwd return passwd def get_user(username): username_ = urllib.quote(username) username = base64.encodestring(username_)[:-1] return username def login(): username = '你的登录邮箱' pwd = '你的密码' url = 'http://login.sina.com.cn/sso/login.php?client=ssologin.js(v1.4.18)' try: servertime, nonce,rsakv = get_servertime() except: return global postdata postdata['servertime'] = servertime postdata['nonce'] = nonce postdata['rsakv'] = rsakv postdata['su'] = get_user(username) postdata['sp'] = get_pwd(pwd, servertime, nonce) for i in postdata: print i,":", postdata[i]#可以看提交的哪些数据 # print postdata["su"] # print postdata["sp"] postdata = urllib.urlencode(postdata) headers = {'User-Agent':'Mozilla/5.0 (X11; Linux i686; rv:8.0) Gecko/20100101 Firefox/8.0'} req = urllib2.Request( url = url, data = postdata, headers = headers ) result = urllib2.urlopen(req) text = result.read() #print len(text) #print 30*"*" #print text #p = re.compile('location\.replace\(\'(.*?)\'\)')#p = re.compile('location\.replace\(\'(.*?)\'\)') p = re.compile('location\.replace\(\"(.*?)\"\)') login_url = p.findall(text)[0] #login_url = p.search(text).group(1) print login_url print 30*"*" try: result1 =urllib2.urlopen(login_url).read() fres = open("fres.txt","w") fres.write(result1) fres.close() # print len(result1) # print type(result1) print u"登录成功!"#是否登录成功还要看result1的内容是否是别的什么, query = "深圳禁摩限电" page_num = 1 url = "http://s.weibo.com/weibo/{0}&b=1&nodup=1&page={1}".format(query, page_num) #http://s.weibo.com/weibo/深圳禁摩限电&b=1&nodup=1&page=1 print url.encode("gbk") #newurl = "http://baike.baidu.com"+suburl req = urllib2.Request(url) html = urllib2.urlopen(req).read() #print html # html = urllib2.urlopen(url) # req = urllib2.urlparse() #soup = bs(html) f_query1 = open("shenzhenlimitcar_sf.html","w") f_query1.write(html) f_query1.close() except Exception,e: print 'Login error!' print e if __name__=="__main__": login()
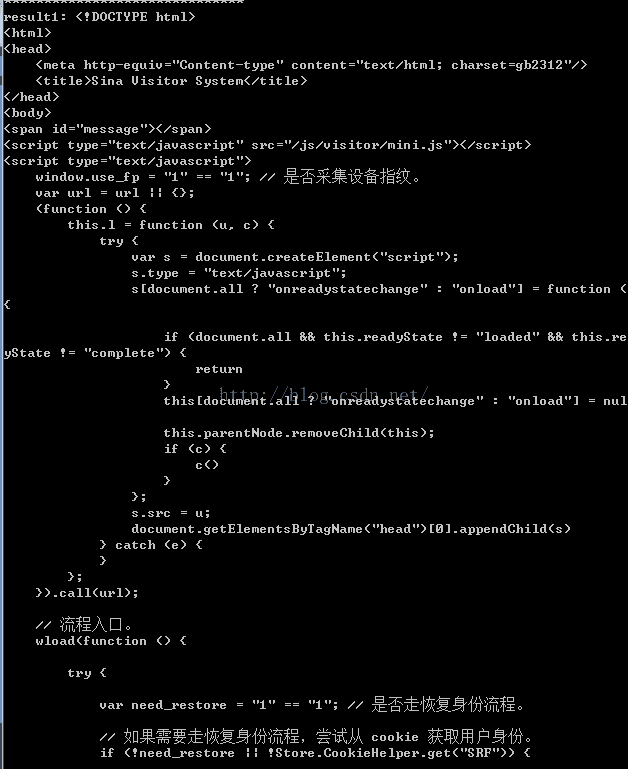
Figure 4: 登录失败
若是fres文件中出现了上述结果,里面有“出错情况返回登录页。"等字,表明还是未成功(成功的那个下次再贴出来)。
另外,若是失败了,可能表明账号被封了,换个账号试试,或者等几个小时再试试。总之,不要辣么频繁的登陆,登陆成功了,把cookie拿下来,保持登陆的状态就可以了。经验证,在linux系统下,是阔以的;而卤煮转到windows下就挂了。
三、感谢
感谢同学的帮忙,一起讨论分析。这里贴上他的博客和github,以及fork师兄写的代码(参考了最终版本的,未放在github中)和fork网友的爬虫代码。另外知乎上的一个爬虫问题,挺多人讨论的并且有的贡献了自己的代码,也可以参考。
转载请注明:http://blog.csdn.net/u010454729