本博客仅为作者记录笔记之用,不免有很多细节不对之处。还望各位看官能够见谅,欢迎批评指正。
在机器学习和深度学习中,过拟合是一个十分常见的问题,一旦模型过拟合了,可能这个模型就无法适用于业务场景中了。所以为了降低产生过拟合的风险,机器学习中的大牛们提出了以下几种方法供大家使用:
- 引入正则化
- Dropout
- 提前终止训练
- 增加样本量
本文将对这5种方法进行简单的讲解分析。
1. 正则化
正则化的思想十分简单明了。由于模型过拟合极有可能是因为我们的模型过于复杂。因此,我们需要让我们的模型在训练的时候,在对损失函数进行最小化的同时,也需要让对参数添加限制,这个限制也就是正则化惩罚项。
假设我们模型的损失函数为
加入正则项
常用的正则化有两种:
L1正则:
L1正则项的表达式为:
L1=∑ki=1||wi||1
其中w代表模型的参数,k代表模型参数的个数。L2正则
L2正则项的表达式为:
L1=∑ki=1||wi||22
其中w代表模型的参数,k代表模型参数的个数。
L1正则与L2正则的思想就是不能够一味的去减小损失函数,你还得考虑到模型的复杂性,通过限制参数的大小,来限制其产生较为简单的模型,这样就可以降低产生过拟合的风险。
它们的区别在于L1更容易得到稀疏解。为什么呢?我们先看看一个直观的例子:

假设我们模型只有
而使用L1正则项的另一个好处是:由于L1正则项求解参数时更容易得到稀疏解,也就意味着求出的参数中含有0较多。因此它自动帮你选择了模型所需要的特征。L1正则化的学习方式是一种嵌入式特征学习方式,它选取特征和模型训练时一起进行的。
2. Dropout
Dropout是在深度学习中降低过拟合风险的常见方法,它是由大牛Hinton老爷子提出的。老爷子认为在神经网络产生过拟合主要是因为神经元之间的协同作用产生的。因此老爷子在神经网络进行训练的时候,让部分神经元失活,这样就阻断了部分神经元之间的协同作用,从而强制要求一个神经元和随机挑选出的神经元共同进行工作,减轻了部分神经元之间的联合适应性。
Dropout的具体流程如下:
- 对
l 层第j 个神经元产生一个随机数r(l)j∼Bernouli(p) - 将
l 层第j 个神经元的输入乘上产生的随机数作为这个神经元新的输入:x(l)∗j=x(l)j∗r(l)j - 此时第
l 层第j 个神经元的输出为:
yl+1j=f(∑kj=1(wl+1j∗x(l)∗j+b(l+1)))
其中,k为第l层神经元的个数,f为该神经元的激活函数,b为偏置,w为权重向量。
注意:当我们采用了Dropout之后再训练结束之后,应当将网络的权重乘上概率p得到测试网络的权重,或者可以在训练时,将样本乘上
3. 提前终止
在对模型进行训练时,我们可以将我们的数据集分为三个部分,训练集、验证集、测试集。我们在训练的过程中,可以每隔一定量的step,使用验证集对训练的模型进行预测,一般来说,模型在训练集和验证集的损失变化如下图所示:
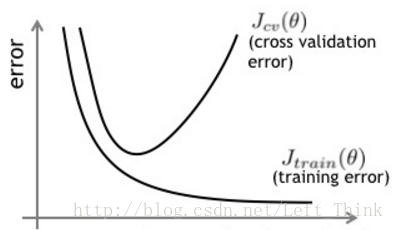
可以看出,模型在验证集上的误差在一开始是随着训练集的误差的下降而下降的。当超过一定训练步数后,模型在训练集上的误差虽然还在下降,但是在验证集上的误差却不在下降了。此时我们的模型就过拟合了。因此我们可以观察我们训练模型在验证集上的误差,一旦当验证集的误差不再下降时,我们就可以提前终止我们训练的模型。
4. 增加样本量
在实际的项目中,你会发现,上面讲述的那些技巧虽然都可以减轻过拟合的风险,但是却都比不上增加样本量来的更实在。为什么增加样本可以减轻过拟合的风险呢?这个要从过拟合是啥来说。过拟合可以理解为我们的模型对样本量学习的太好了,把一些样本的特殊的特征当做是所有样本都具有的特征。举个简单的例子,当我们模型去训练如何判断一个东西是不是叶子时,我们样本中叶子如果都是锯齿状的话,如果模型产生过拟合了,会认为叶子都是锯齿状的,而不是锯齿状的就不是叶子了。如果此时我们把不是锯齿状的叶子数据增加进来,此时我们的模型就不会再过拟合了。因此其实上述的那些技巧虽然有用,但是在实际项目中,你会发现,其实大多数情况都比不上增加样本数据来的实在。
下面顺便介绍一下深度学习中一个比较厉害的trick:Batch Normalization
BN是15年提出的用于减轻过拟合风险的一种方法,现在这个算法被大量的引用于各种网络。事实证明该方法在加快模型的收敛速度,提高模型的泛化能力。
那什么是BN呢?顾名思义,BN就是批正则化。由于我们现在在对神经网络进行优化求解时,通常是使用SGD。每次输入一个mini-batch的数据到神经网络中。在某一层输入数据到神经元之前,对神经元的输入做一个归一化的处理,即将数据归一化为均值为0,方差为1。
其中,
其中,
有人可能要问,那BN到底为什么能够加快模型的收敛速度,提高模型的泛化能力?
附上我的github主页,欢迎各位的follow~~~献出小星星~
参考文献
1 理解dropout
2 深度学习(二十二)Dropout浅层理解与实现
3 “西瓜书”机器学习 :周志华
4 深度学习(二十九)Batch Normalization 学习笔记