什么事过拟合?
过拟合(overfitting)是指在模型参数拟合过程中的问题,由于训练数据包含抽样误差,训练时,复杂的模型将抽样误差也考虑在内,将抽样误差也进行了很好的拟合。
具体表现就是最终模型在训练集上效果好;在测试集上效果差。模型泛化能力弱。
1:正则化
1.1 L1 正则
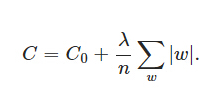
1.2 L2 正则
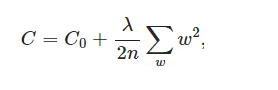
L1正则与L2正则的思想就是不能够一味的去减小损失函数,你还得考虑到模型的复杂性,通过限制参数的大小,来限制其产生较为简单的模型,这样就可以降低产生过拟合的风险。
在优化损失函数的时候L1正则化会产生稀疏矩阵,导致一部分w为0,注意这也是L1正则化的核心思想。产生稀疏矩阵之后,一部分w为0,一部分不为0,这样即可对特征进行选择。选择比较重要、明显的特征作为分类和预测的依据,抛弃那些不重要的特征。
L2正则化则是趋向于把所有参数w都变得比较小,一般认为参数w比较小的时候,模型比较简单。直观上来说,L2正则化的解都比较小,抗扰动能力强。在求解过程中,L2通常倾向让权值尽可能小,最后构造一个所有参数都比较小的模型。因为一般认为参数值小的模型比较简单,能适应不同的数据集,也在一定程度上避免了过拟合现象。参数足够小,数据偏移得多一点也不会对结果造成什么影响,可以说“抗扰动能力强”。
2:BN
Batch Normalization有两个功能:
- 可以加快训练和收敛速度
- 可以防止过拟合:BN的使用使得一个mini-batch中的所有样本都被关联在了一起,因此网络不会从某一个训练样本中生成确定的结果
3:提前终止
4:增加样本数量
5:Dropout算法
最直观的原因其实就是:防止参数过分依赖训练数据,增加参数对数据集的泛化能力。因为在实际训练的时候,每个参数都有可能被随机的Drop掉,所以参数不会过分的依赖某一个特征的数据,而且不同参数之间的相互关联性也大大减弱,这些操作都可以增加泛化能力。在神经网络进行训练的时候,让部分神经元失活,这样就阻断了部分神经元之间的协同作用,从而强制要求一个神经元和随机挑选出的神经元共同进行工作,减轻了部分神经元之间的联合适应性。
更为深入的来讲,Dropout其实是一种分布式表示:
分布式表征(Distributed Representation),是人工神经网络研究的一个核心思想。那什么是分布式表征呢?简单来说,就是当我们表达一个概念时,神经元和概念之间不是一对一对应映射(map)存储的,它们之间的关系是多对多。具体而言,就是一个概念可以用多个神经元共同定义表达,同时一个神经元也可以参与多个不同概念的表达,只不过所占的权重不同罢了。
举例来说,对于“小红汽车”这个概念,如果用分布式特征地表达,那么就可能是一个神经元代表大小(形状:小),一个神经元代表颜色(颜色:红),还有一个神经元代表车的类别(类别:汽车)。只有当这三个神经元同时被激活时,就可以比较准确地描述我们要表达的物体。