AlexNet
2012年,Alex Krizhevsky(Hinton的学生)提出了AlexNet,它可以看做是LeNet的一个更深更宽版本。
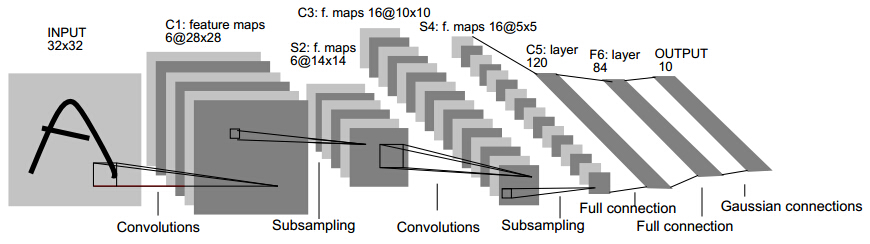
这就是Gradient-Based Learning Applied to Document Recognition论文里LeNet模型的架构。
LeNet 这个网络虽然很小,但是它包含了卷积神经网络的基本模块:卷积层,池化层,全链接层。是其他深度学习模型的基础。
但是由于当时的计算机性能(没有GPU),还有数据样本的限制等等原因没有快速发展起来。
而AlexNet在论文ImageNet Classification with Deep Convolutional Neural Networks 中的架构如下:
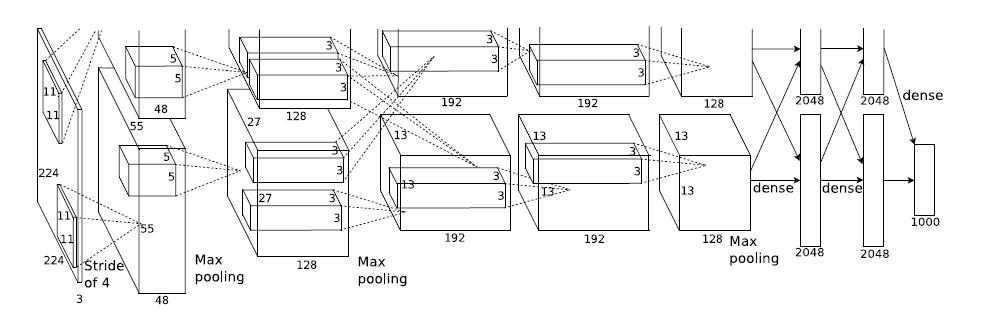
可以看到整体的思想并没有改变,但是却引入了ReLU,Dropout和LRN等trick。
整个AlexNet包含了了八个需要训练的层(不包括池化层),前五层是卷积层,后三层是全连接层。上图之所以分开两部分是因为作者使用了两块GPU训练。
AlexNet的每层结构参数如下:
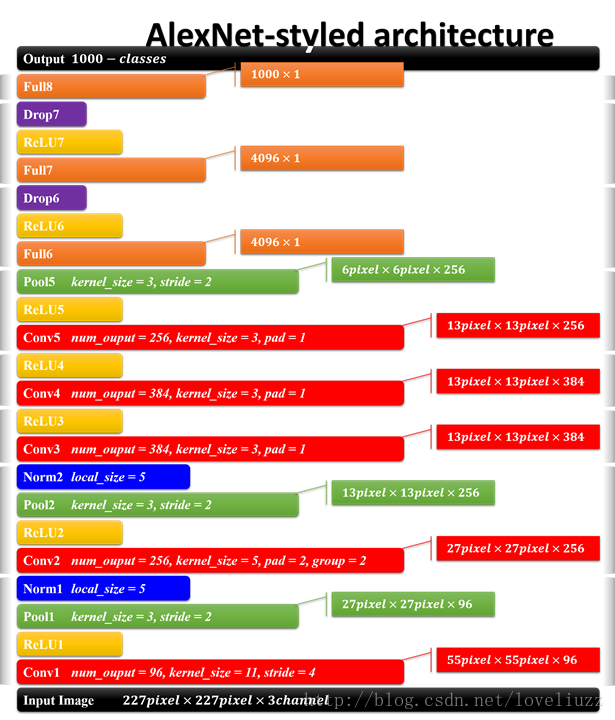
AlexNet主要用到的新技术包括:
1.使用了ReLU激活函数代替sigmoid激活函数
Relu函数:f(x)=max(0,x)
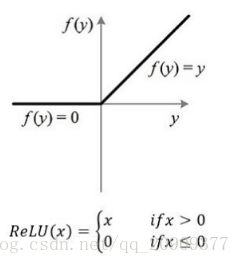
ReLU的有效性体现在两个方面:
- 克服梯度消失的问题
- 加快训练速度
而sigmoid会在网络层数增加的时候带来梯度弥散的问题。
2.使用Dropout随机忽略一部分神经元
dropout是指在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中丢弃。
对于dropout为何会有效,这要有两种观点:
参考http://blog.csdn.net/stdcoutzyx/article/details/49022443
1.受人类繁衍影响提出了dropout
论文Dropout: A Simple Way to Prevent Neural Networks from Overfitting里面提到,Dropout类似于性别在生物进化中的角色,物种为了使适应不断变化的环境,性别的出现有效的阻止了过拟合,即避免环境改变时物种可能面临的灭亡。dropout也能达到同样的效果,它迫使一个神经单元和随机挑选出来的其他神经单元能够达到好的效果。消除减弱了神经元节点间的联合适应性,增强了泛化能力。
2.dropout相当于一种ensemble
我们都知道在机器学习之中ensemble的模型能比单一模型更具有泛化性能,因为ensemble模型是多个单一模型的集成,然而对于训练多个神经网络模型的ensemble会出现耗时和容易过拟合的问题,而dropout是将某些神经元随机的丢弃,相当于每次训练都得到一个比定义的模型更窄的模型。

这样,在训练的时候我们就似乎能够获得多个模型,而在测试的时候我们就不再使用dropout,相当于我们使用了多个模型的ensemble。
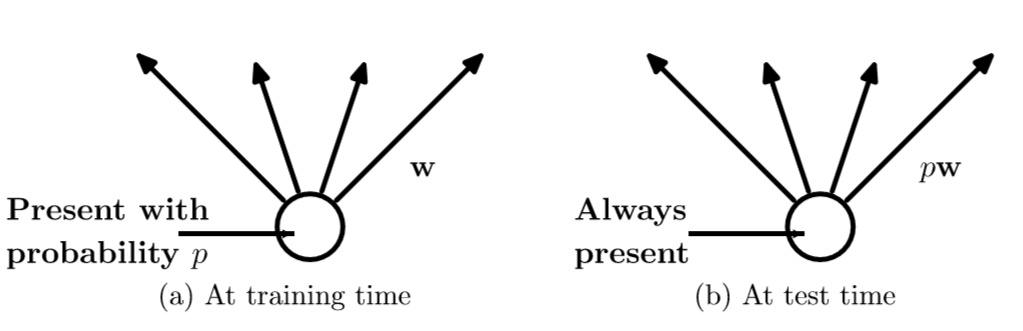
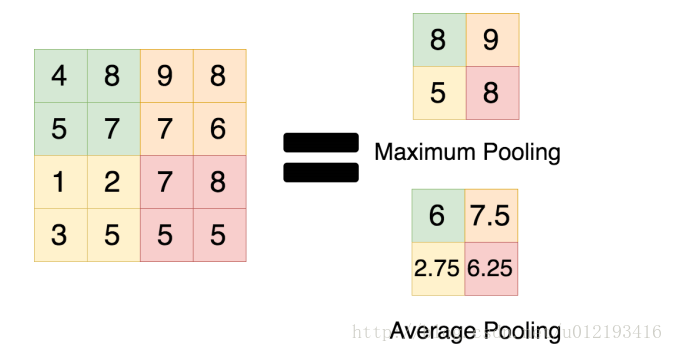
3.使用Max pooling代替Average pooling
此前CNN普遍使用average pooling,这样会带来模糊化的效果,并且论文中提出了让步长小于池化核的尺寸,这样池化层的输出之间就会有重叠和覆盖,提升了特征的丰富性。max pooling更多的保留纹理信息。average pooling更强调对整体特征信息进行一层下采样,在减少参数维度的贡献上更大一点。
4.数据增强 data augmentation
随机地从原始图像中截取区域,并水平翻转,增加了数据量。如果没有数据增强,CNN很可能会落入过拟合的尴尬局面,加入了数据增强之后可以提高模型的泛化性能。
VGGNet
VGGNet是google和牛津大学一起研发的卷积神经网络。如下是VGGNet个级别的网络结构图
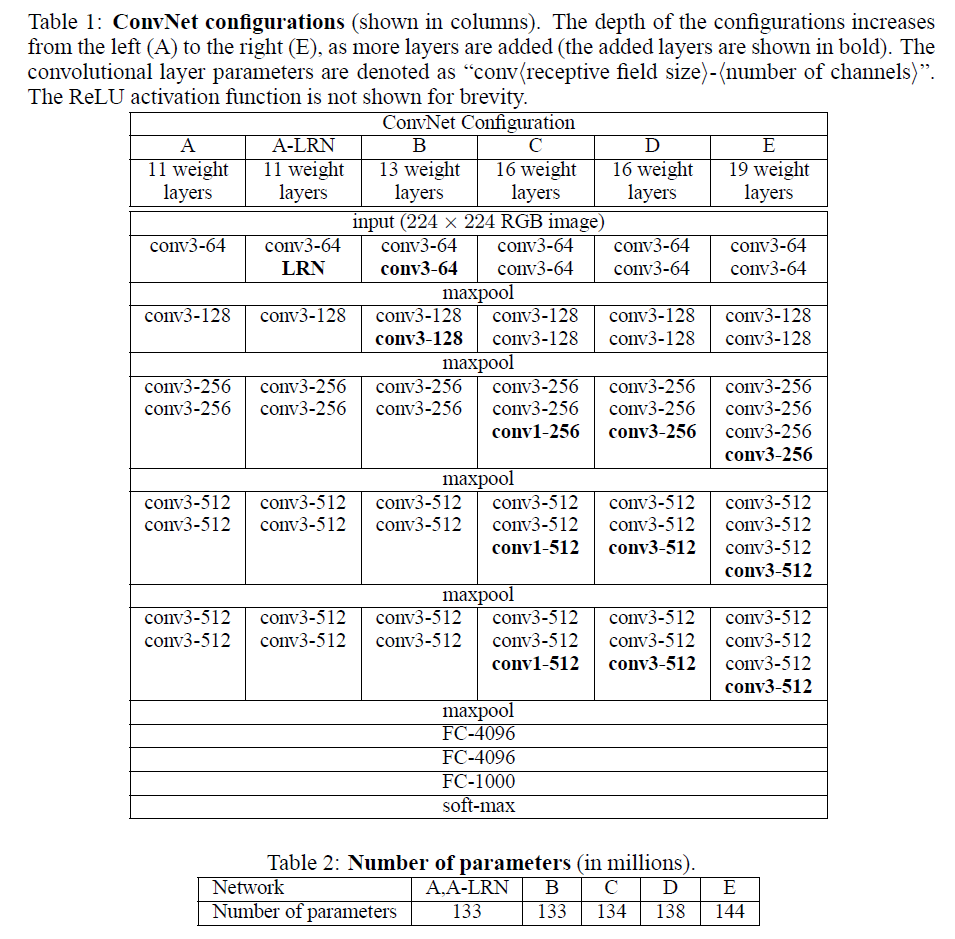
从图中可以看出,该网络结构有如下的特点:
(1)VGG全部使用3*3卷积核、2*2池化核,不断加深网络结构来提升性能。
(2)A到E网络变深,参数量没有增长很多,参数量主要在3个全连接层。
(3)训练比较耗时的依然是卷积层,因计算量比较大。
(4)VGG有5段卷积,每段有2~3个卷积层,每段尾部用池化来缩小图片尺寸。
(5)每段内卷积核数一样,越靠后的段卷积核数越多:64–128–256–512–512。
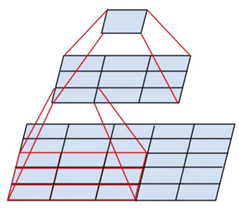
之所以使用3*3的卷积核堆叠起来是因为,这样可以扩大局部的感受野的同时又降低了参数的数量,三个3*3的卷积层串联相当于1个7*7的卷积层,但3个串联的3*3的卷积层有更少的参数量,有更多的非线性变换(3次ReLU激活函数),使得CNN对特征的学习能力更强。
同时在训练的时候有一个trick就是先训练层数比较小的的简单网络,然后再复用这些简单网络的权重初始化后面几个复杂的网络,使得训练的收敛更加快。
而在预测的时候,使用multi-scale的方法,将要预测的数据scale到一个比原来数据更小的尺寸同时预测,然后再最后使用平均的分类结果,提高了预测的准确率和图片的利用率。btw,训练的时候也是用了multi-scale的方法做数据增强。
论文作者总结了几个观点包括:
1.LRN层的作用不大
2.越深的网络效果越好
3.大一些的卷积核可以学习到更大的空间特征
在我看来就是一个成本和效率的问题,为了降低训练的成本而使用了更小一点的卷积核(因为大的卷积核要训练的参数比较多),至于越深的网络越好,是因为有更多的非线性变换,在高维空间里可以学到低维空间无法区分的特征。
AlexNet 和 VGGNet的对比
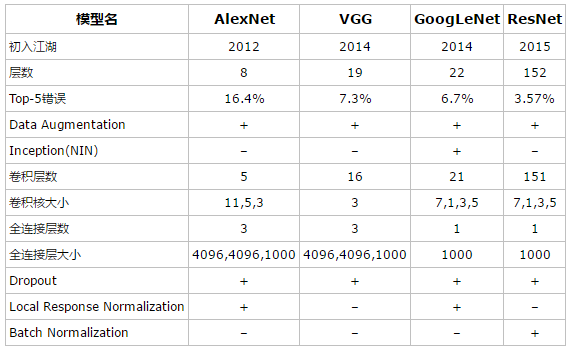
虽然VGGNet比AlexNet的参数要多,但反而需要更少的迭代次数就可以收敛,主要原因是更深的网络和更小的卷积核带来的隐式的正则化效果。
参考文献:
1.ImageNet Classification with Deep Convolutional Neural Networks
2.VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION
3.《TensorFlow实战》